Parquet表在spark与Impala间兼容性测试
一、 背景
目前市面上的大数据技术非常多,但苦了我们做方案的,到底哪家强呢?一方面也要去尊重客观事实,一方面要去满足客户期望,而当两者出现冲突的情况下,选择上就有点左右为难。针对sql on hadoop类的组件,hive/Impala/spark-sql/presto,接触过一点,也做过部分的验证,结论暂时与客户所期望的有点出入,因此目前有点小纠结。之所以说是部分验证,因为这里头涉及到的方面还是非常之多的,机器环境、场景覆盖面,不能够草率下结论,比方说,在同等条件下可能A技术比B技术牛,当集群的规模放大之后A技术可能又比B技术牛,这是完全可能的,所以说要做一个严谨的比较不是那么容易。
那么,我就联想到软件设计上的办法,对象和方法分离,数据与计算分离。能不能先不要拘泥在某一种技术选型上,把视线聚焦到数据本身处理上来,数据保持一份,在计算引擎上允许自由的切换选择,一旦某个环节上A技术不满足要求可切换至B技术,不指望一点改造都没,但代价要求可控的(其实都是一些SQL为主,改动不是很大)。这个里面就涉及到表共享访问问题。好在大多的sql on hadoop都基于hive保存元数据,本身对表的读写都是互通的,人家已经设计得好好的了,不存在大的制约。在实际运用过程中,当然会按照综合评估情况首选一种,我这里主要是强调这种兼容接口的预先考虑,降低对单一技术的依赖。
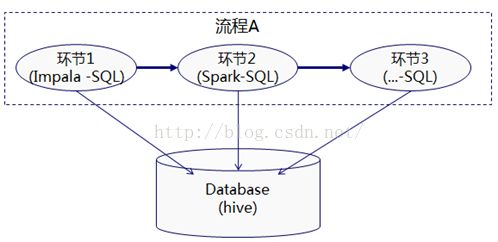
这里我主要是验证下parquet格式,这是一种压缩后的列存储格式,可以提高性能,在某些组件中是官方推荐的,比如我们之前大量使用的Impala,既然跟普通的文本方式相比稍显特殊,那就要考察其在不同组件之间的兼容性了。早期的版本我们验证过,跟spark不兼容,无法直接读取。
我下面尝试在新版本下做下验证,主要是验证其在Impala与Spark之间的兼容性。
二、 步骤
测试环境:CDH5.4.0(由原来的CDH5.3.0升上来的),Impala2.2.0,spark.1.5.2
注意这里的测试用例在其它更高版本全新安装的集群环境下并未出现问题,是兼容的,请注意甄别。
#创建测试TXT格式的表
create table tst_1( date_id string, idstring, city_id string )
row format delimited fields terminated by ',' stored as textfile;
模拟一些表数据,形成文件/data/testfile/tbs_1.txt
20150210,2121,222221
20150210,1221,333313
20150211,1321,433333
#上传至表目录
hdfs dfs -put /data/testfile/tbs_1.txt/user/hive/warehouse/tst_1
#可以查询到记录
select * fromtst_1 ;
############################################################################################
#在spark中创建parquet表,看impala中是否可以访问
create table par_crt_spark stored asparquet as select * from tst_1 ;
#在Impala中创建parquet表,看Spark中是否可以访问
create table par_crt_impala stored asparquet as select * from tst_1 ;
好,这个时候问题就来了,
Error:java.lang.RuntimeException: java.lang.ClassNotFoundException:parquet.hive.DeprecatedParquetInputFormat
找了一圈也没有发现JAR包方面的问题。更奇怪的是,我让同事在其它集群上做相同的测试,发现没有这个问题,区别是他的集群是CDH 5.4.7,且是全新安装的,我只能暂时怀疑是升级过程带出的问题,如果真要去排查要花点时间。这里我想着先找个解决的办法。
通过desc formatted 比对了下生成表的格式:
这里是spark-sql下创建的parquet表格式:
SerDe Library: | org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat: | org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat: | org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
这里是Impala下创建的parquet表格式:
SerDe Library: | parquet.hive.serde.ParquetHiveSerDe
InputFormat: | parquet.hive.DeprecatedParquetInputFormat
OutputFormat: | parquet.hive.DeprecatedParquetOutputFormat
明显看得到区别,看起来我在Impala上产生的表的格式默认还去使用了老的过期的parquet格式,而导致在spark下不能正确识别。很自然的想到,能不能通过手动修改成一致的再去看是否能识别。
下面这个命令是在hive下执行,其实在spark beline下也是可以运行的。
##############################################################################
ALTER TABLE par_crt_impala SET FILEFORMAT
INPUTFORMAT"org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat"
OUTPUTFORMAT"org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat"
SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
;
##############################################################################
之后,再去查看表信息,发现格式修改成预期的了,后再转去spark-sql中查询,可以正确操作了。
上面算是一种折中的解决途径,至于对有无重大的功能影响目前没有深入去验证。
补:该问题在升级至5.4.7后不存在,创建的parquet格式的表默认格式是对。