python类别变量(class_label)转换为One_Hot的几种方式
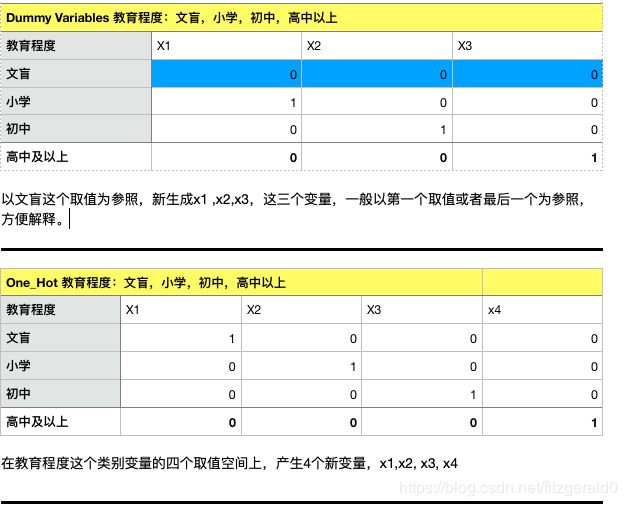
首先解析一下,one_hot (独热)编码,和dummy variable(哑变量)的区别:

在用keras时候,有一个模块写好one_hot转换
from keras.utils import to_categoricaldata = [1, 3, 2, 0, 3, 2, 2, 1, 0, 1]
encoded=to_categorical(data)
print(encoded)则打印出来的结果为:
[[ 0. 1. 0. 0.]
[ 0. 0. 0. 1.]
[ 0. 0. 1. 0.]
[ 1. 0. 0. 0.]
[ 0. 0. 0. 1.]
[ 0. 0. 1. 0.]
[ 0. 0. 1. 0.]
[ 0. 1. 0. 0.]
[ 1. 0. 0. 0.]
[ 0. 1. 0. 0.]]def to_categorical(y, num_classes=None):
y = np.array(y, dtype='int')
input_shape = y.shape
if input_shape and input_shape[-1] == 1 and len(input_shape) > 1:
input_shape = tuple(input_shape[:-1])
y = y.ravel()
if not num_classes:
num_classes = np.max(y) + 1
n = y.shape[0]
categorical = np.zeros((n, num_classes))
categorical[np.arange(n), y] = 1
output_shape = input_shape + (num_classes,)
categorical = np.reshape(categorical, output_shape)
return categorical在sklearn中的one_hot编码
from sklearn import preprocessing
import numpy as np
label = preprocessing.LabelEncoder()
one_hot = preprocessing.OneHotEncoder(sparse = False)
cat_data =([1,3,2],
[2,1,1],
[4,2,2])
print one_hot.fit_transform(cat_data)打印的结果为
[[1. 0. 0. 0. 0. 1. 0. 1.]
[0. 1. 0. 1. 0. 0. 1. 0.]
[0. 0. 1. 0. 1. 0. 0. 1.]]
如果是二分类(二进制)则,还可以用以下方法,定义一个函数
def cat_to_num(data):
categories = unique(data)
features = []
for cat in categories:
binary = (data == cat)
features.append(binary.astype("int"))
return featuresimport numpy as np
cat_data =np.array(['male', 'female', 'male', 'male'])
cat_to_num(cat_data)打印出
[array([0, 1, 0, 0]), array([1, 0, 1, 1])]上文定义的这个转换函数可以是1维的,且可以是字符串
当然在sklearn中也有实现的方法,(二进制 / 二分类编码)
from sklearn.preprocessing import BinarizerBinarizer如果直接调用的话必须是二维矩阵,数值类型,需要设置threshold阈值
import numpy as np
cat_data =np.array([[1,2],
[3,4]])binarizer =Binarizer(threshold=2.1)
binarizer.transform(cat_data)
下面是pandas的dummy variable
import pandas as pd
data_dummy=pd.get_dummies(data)