Python3 爬虫(三) -- 爬取豆瓣首页图片
序
前面已经完成了简单网页以及伪装浏览器的学习。下面,实现对豆瓣首页所有图片爬取程序,把图片保存到本地一个路径下。
首先,豆瓣首页部分图片展示
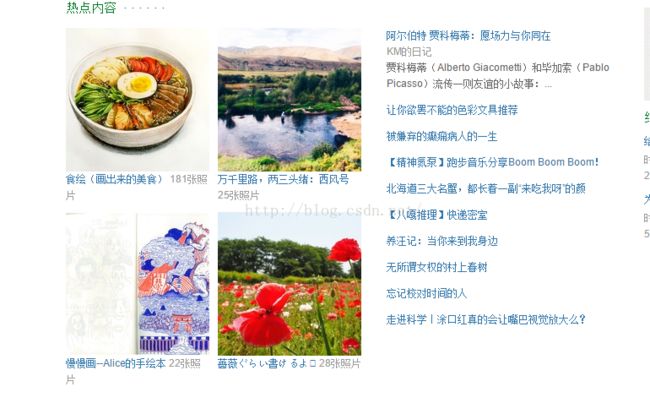
这只是截取的一部分。下面给出,整个爬虫程序。
爬虫程序
这个爬取图片的程序采用伪装浏览器的方式,只不过是加了处理图片的模块。
'''
批量下载豆瓣首页的图片
采用伪装浏览器的方式爬取豆瓣网站首页的图片,保存到指定路径文件夹下
'''
#导入所需的库
import urllib.request,socket,re,sys,os
#定义文件保存路径
targetPath = "E:\\projects\\Spider\\03_dbImages"
def saveFile(path):
#检测当前路径的有效性
if not os.path.isdir(targetPath):
os.mkdir(targetPath)
#设置每个图片的路径
pos = path.rindex('/')
t = os.path.join(targetPath,path[pos+1:])
return t
#用if __name__ == '__main__'来判断是否是在直接运行该.py文件
# 网址
url = "https://www.douban.com/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/51.0.2704.63 Safari/537.36'
}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
for link,t in set(re.findall(r'(https:[^s]*?(jpg|png|gif))', str(data))):
print(link)
try:
urllib.request.urlretrieve(link,saveFile(link))
except:
print('失败')爬取结果
(1)打印出来的信息

(2)爬取的图片列表

可以跟豆瓣首页进行对比。
GitHub代码链接