spark mlib系列2
前言
随着大数据时代的到来,数据当中挖取金子的工作越来越有吸引力。利用Spark在内存迭代运算、机器学习领域强悍性能的优势,使用spark处理数据挖掘问题就显得很有实际价值。这篇文章给大家分享一个spark MLlib 的推荐实战例子。我将会分享怎样用spark MLlib做一个电影评分的推荐系统。使用到的算法是user-based协同过滤。如果对Spark MLlib不太了解的,请阅读我的上一篇博客。
推荐系统的对比
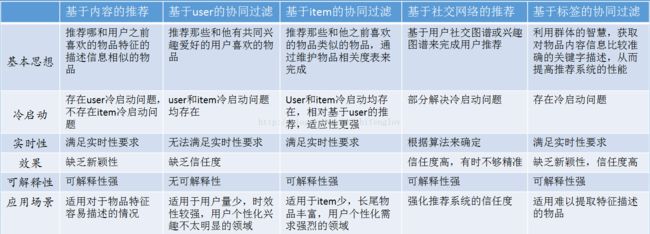
应该说,自从Amazone公布了协同过滤算法后,在推荐系统领域,它就占据了很重要的地位。不像传统的内容推荐,协同过滤不需要考虑物品的属性问题,用户的行为,行业问题等,只需要建立用户与物品的关联关系即可,可以物品之间更多的内在关系,类似于经典的啤酒与尿不湿的营销案例。所以,讲到推荐必须要首先分享协同过滤。
Spark MLlib中的协同过滤
协同过滤常被应用于推荐系统。这些技术旨在补充用户-商品关联矩阵中所缺失的部分。MLlib当前支持基于模型的协同过滤,其中用户和商品通过一小组隐语义因子进行表达,并且这些因子也用于预测缺失的元素。为此,我们实现了交替最小二乘法(ALS) 来学习这些隐性语义因子。在 MLlib 中的实现有如下的参数:
numBlocks 是用于并行化计算的分块个数 (设置为-1为自动配置)。
rank 是模型中隐语义因子的个数。
iterations 是迭代的次数。
lambda 是ALS的正则化参数。
implicitPrefs 决定了是用显性反馈ALS的版本还是用适用隐性反馈数据集的版本。
alpha 是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准。
隐性反馈 vs 显性反馈
基于矩阵分解的协同过滤的标准方法一般将用户商品矩阵中的元素作为用户对商品的显性偏好。
在许多的现实生活中的很多场景中,我们常常只能接触到隐性的反馈(例如游览,点击,购买,喜欢,分享等等)在 MLlib 中所用到的处理这种数据的方法来源于文献: Collaborative Filtering for Implicit Feedback Datasets。 本质上,这个方法将数据作为二元偏好值和偏好强度的一个结合,而不是对评分矩阵直接进行建模。因此,评价就不是与用户对商品的显性评分而是和所观察到的用户偏好强度关联了起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。
目前可用的协同过滤的算法:
- ALS
数据准备
数据准备,MoiveLens的数据集,有100k到10m的数据都有。我们这里选择100k的数据。
对下载的数据解压之后,会出现很多文件,我们需要使用u.data和u.user文件。详细的数据说明可以参见README。
u.data是用户对电影评分的数据,也是训练集。数据分别表示userId,moiveId,评分rate,时间戳。如下图所示

u.user是用户的个人信息数据,用以推荐使用,分别表示userId,age,sex,job,zip code。我们只使用userId即可。如下图所示

实现的功能
这里有10w条用户对电影的评分,从1-5分,1分表示差劲,5分表示非常好看。根据用户对电影的喜好,给用户推荐可能感兴趣的电影。
实现思路
代码实现如下:
1、加载u.data数据到rating RDD中
2、对rating RDD的数据进行分解,只需要userId,moiveId,rating
3、使用rating RDD训练ALS模型
4、使用ALS模型为u.user中的用户进行电影推荐,数据保存到HBase中
5、评估模型的均方差
代码
-
package com.ml.recommender -
import org.apache.spark.SparkContext._ -
import org.apache.spark.SparkConf -
import org.apache.spark.mllib.recommendation._ -
import org.apache.spark.rdd.{ PairRDDFunctions, RDD } -
import org.apache.spark.SparkContext -
import scala.collection.mutable.HashMap -
import java.util.List -
import java.util.ArrayList -
import scopt.OptionParser -
import com.ml.util.HbaseUtil -
/** -
* moivelens 电影推荐 -
* -
*/ -
object MoiveRecommender { -
val numRecommender = 10 -
case class Params( -
input: String = null, -
numIterations: Int = 20, -
lambda: Double = 1.0, -
rank: Int = 10, -
numUserBlocks: Int = -1, -
numProductBlocks: Int = -1, -
implicitPrefs: Boolean = false, -
userDataInput: String = null) -
def main(args: Array[String]) { -
val defaultParams = Params() -
val parser = new OptionParser[Params]("MoiveRecommender") { -
head("MoiveRecommender: an example app for ALS on MovieLens data.") -
opt[Int]("rank") -
.text(s"rank, default: ${defaultParams.rank}}") -
.action((x, c) => c.copy(rank = x)) -
opt[Int]("numIterations") -
.text(s"number of iterations, default: ${defaultParams.numIterations}") -
.action((x, c) => c.copy(numIterations = x)) -
opt[Double]("lambda") -
.text(s"lambda (smoothing constant), default: ${defaultParams.lambda}") -
.action((x, c) => c.copy(lambda = x)) -
opt[Int]("numUserBlocks") -
.text(s"number of user blocks, default: ${defaultParams.numUserBlocks} (auto)") -
.action((x, c) => c.copy(numUserBlocks = x)) -
opt[Int]("numProductBlocks") -
.text(s"number of product blocks, default: ${defaultParams.numProductBlocks} (auto)") -
.action((x, c) => c.copy(numProductBlocks = x)) -
opt[Unit]("implicitPrefs") -
.text("use implicit preference") -
.action((_, c) => c.copy(implicitPrefs = true)) -
opt[String]("userDataInput") -
.required() -
.text("use data input path") -
.action((x, c) => c.copy(userDataInput = x)) -
arg[String]("") -
.required() -
.text("input paths to a MovieLens dataset of ratings") -
.action((x, c) => c.copy(input = x)) -
note( -
""" -
|For example, the following command runs this app on a synthetic dataset: -
| -
| bin/spark-submit --class com.zachary.ml.MoiveRecommender \ -
| examples/target/scala-*/spark-examples-*.jar \ -
| --rank 5 --numIterations 20 --lambda 1.0 \ -
| data/mllib/u.data -
""".stripMargin) -
} -
parser.parse(args, defaultParams).map { params => -
run(params) -
} getOrElse { -
System.exit(1) -
} -
} -
def run(params: Params) { -
//本地运行模式,读取本地的spark主目录 -
var conf = new SparkConf().setAppName("Moive Recommendation") -
.setSparkHome("D:\\work\\hadoop_lib\\spark-1.1.0-bin-hadoop2.4\\spark-1.1.0-bin-hadoop2.4") -
conf.setMaster("local[*]") -
//集群运行模式,读取spark集群的环境变量 -
//var conf = new SparkConf().setAppName("Moive Recommendation") -
val context = new SparkContext(conf) -
//加载数据 -
val data = context.textFile(params.input) -
/** -
* *MovieLens ratings are on a scale of 1-5: -
* 5: Must see -
* 4: Will enjoy -
* 3: It's okay -
* 2: Fairly bad -
* 1: Awful -
*/ -
val ratings = data.map(_.split("\t") match { -
case Array(user, item, rate, time) => Rating(user.toInt, item.toInt, rate.toDouble) -
}) -
//使用ALS建立推荐模型 -
//也可以使用简单模式 val model = ALS.train(ratings, ranking, numIterations) -
val model = new ALS() -
.setRank(params.rank) -
.setIterations(params.numIterations) -
.setLambda(params.lambda) -
.setImplicitPrefs(params.implicitPrefs) -
.setUserBlocks(params.numUserBlocks) -
.setProductBlocks(params.numProductBlocks) -
.run(ratings) -
predictMoive(params, context, model) -
evaluateMode(ratings, model) -
//clean up -
context.stop() -
} -
/** -
* 模型评估 -
*/ -
private def evaluateMode(ratings: RDD[Rating], model: MatrixFactorizationModel) { -
//使用训练数据训练模型 -
val usersProducets = ratings.map(r => r match { -
case Rating(user, product, rate) => (user, product) -
}) -
//预测数据 -
val predictions = model.predict(usersProducets).map(u => u match { -
case Rating(user, product, rate) => ((user, product), rate) -
}) -
//将真实分数与预测分数进行合并 -
val ratesAndPreds = ratings.map(r => r match { -
case Rating(user, product, rate) => -
((user, product), rate) -
}).join(predictions) -
//计算均方差 -
val MSE = ratesAndPreds.map(r => r match { -
case ((user, product), (r1, r2)) => -
var err = (r1 - r2) -
err * err -
}).mean() -
//打印出均方差值 -
println("Mean Squared Error = " + MSE) -
} -
/** -
* 预测数据并保存到HBase中 -
*/ -
private def predictMoive(params: Params, context: SparkContext, model: MatrixFactorizationModel) { -
var recommenders = new ArrayList[java.util.Map[String, String]](); -
//读取需要进行电影推荐的用户数据 -
val userData = context.textFile(params.userDataInput) -
userData.map(_.split("\\|") match { -
case Array(id, age, sex, job, x) => (id) -
}).collect().foreach(id => { -
//为用户推荐电影 -
var rs = model.recommendProducts(id.toInt, numRecommender) -
var value = "" -
var key = 0 -
//保存推荐数据到hbase中 -
rs.foreach(r => { -
key = r.user -
value = value + r.product + ":" + r.rating + "," -
}) -
//成功,则封装put对象,等待插入到Hbase中 -
if (!value.equals("")) { -
var put = new java.util.HashMap[String, String]() -
put.put("rowKey", key.toString) -
put.put("t:info", value) -
recommenders.add(put) -
} -
}) -
//保存到到HBase的[recommender]表中 -
//recommenders是返回的java的ArrayList,可以自己用Java或者Scala写HBase的操作工具类,这里我就不给出具体的代码了,应该可以很快的写出 -
HbaseUtil.saveListMap("recommender", recommenders) -
} -
}
运行
1、在scala IDE(或者eclipse安装scala插件)运行:
设置工程名,main类等
设置运行参数
--rank 10 --numIterations 40 --lambda 0.01 --userDataInput D:\\ml_data\\data_col\\ml-100k\\ml-100k\\u.user D:\\ml_data\\data_col\\ml-100k\\ml-100k\\u.data
2、在集群中运行如下:
/bin/spark-submit --jars hbase-client-0.98.0.2.1.5.0-695-hadoop2.jar,hbase-common-0.98.0.2.1.5.0-695-hadoop2.jar,hbase-protocol-0.98.0.2.1.5.0-695-hadoop2.jar,htrace-core-2.04.jar,protobuf-java-2.5.0.jar --master yarn-cluster --class com.ml.recommender.MoiveRecommender moive.jar
--rank 10 --numIterations 40 --lambda 0.01 --userDataInput hdfs:/spark_test/u.user hdfs:/spark_test/u.data
注意:
--jars表示项目需要的依赖包
moive.jar表示项目打包的名称
运行结果
均方差如下所示

HBase中推荐数据如下所示

比如 939 用户的推荐电影(格式 moivedID:rating):516:7.574462241760971,1056:6.979575106203245,1278:6.918614235693566,1268:6.914693317049802,1169:6.881813878580957,1316:6.681612000425281,564:6.622223206958775,909:6.597412586878512,51:6.539969654136097,1385:6.503960660826889
优化
1、可以调整这些参数,不断优化结果,使均方差变小。比如iterations越多,lambda较小,均方差会较小,推荐结果较优
numBlocks 是用于并行化计算的分块个数 (设置为-1为自动配置)。
rank 是模型中隐语义因子的个数。
iterations 是迭代的次数。
lambda 是ALS的正则化参数。
implicitPrefs 决定了是用显性反馈ALS的版本还是用适用隐性反馈数据集的版本。
alpha 是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准。
2、可以写一个程序去读取HBase的推荐数据,对外暴露一个rest接口,这样可以更方便展示。