Deep Neural Networks for YouTube Recommendations
《YouTube深度神经网络推荐系统》
目的:利用深度神经网络做YouTube视频推荐。
论文信息:google的YouTube团队在推荐系统上DNN方面的尝试,发表在16年9月的RecSys会议。
一,Contribution:
1)详细描述了一个候选集生成模型和一个深度排序模型,开始用deep learning做YouTube视频推荐。
2)提供了一些从设计、迭代和维护庞大用户量的推荐系统中得到的实战经验和见解。
二,实验:
首先:考虑实际需求:
l 规模大:传统无法满足。
l 新鲜度:对新视频作出及时和合适的反馈。
l 噪音:YouTube上的历史用户行为由于稀疏性和各种不可观察的外部因素而不可预测。 我们很少能获得基本真实的用户满意度,更多的是隐式反馈噪声信号。
其次,本文实验数据集:论文不做公开。
实验环境:TensorFlow
2.1本文模型overview:

我们的推荐系统的整体结构如图2所示。该系统由两个神经网络组成:一个用于候选集的生成,一个用于排序。

蓝色的是两个深度网络:
第一个是候选集生成网络,输入:用户的YouTube活动历史记录中的事件(用户U和上下文C的条件下,对用户在t时刻的一次观看Wt)就是一个样本。输出:从大型语料库中检索一小部分(数百个)视频,这些检索出的视频通常高精度的与用户相关。
第二个是排序网络,会对每个Vedio建模丰富的用户物品特征,依据desire的目标函数对每一个视频打分,然后rank by score。
在开发过程中,我们广泛使用了度量指标(精度,召回率,ranking loss等)来指导我们系统的迭代改进。
2.2 候选集生成
1,问题建模
embedding其实就是把一个ID类特征或者离散特征映射成一个n维向量,而这个向量初始化后,在训练过程中和模型的权重一样是作为一个变量来训练的。
业务目标:用户u看过一些视频后,我们需要预测用户下一个要看的视频是100万分类中的哪一个分类?这是个典型的多分类问题,但是类别的数目非常大。
 ……(1)
……(1)
从公式可以看出这是个使用了softmax输出层的多分类题.softmax层的输入就是vi*u,其中u代表a high-dimensional“embedding”of the
考虑训练数据,使用隐式反馈来训练这个,只取完成了了观看的事件作为样本.一条训练数据可以描 述为(u1,c1,5)(用户u1在上下文c1的情况下观看了类别为5的视频)。
在服务的时候,我们需要计算最有可能的N个类(视频),以便选择前N个呈现给用户。在数十毫秒的严格服务延迟下对数百万项目进行评分,需要在类别数量量上有近似线性时间的评分方案。以前的YouTube系统依赖于哈希[24],这里里描述的分类器使用类似的方法。由于softmax 输出层的校准可能性在服务时间是不需要的,因此得分问题可以简化为点积空间中的最近邻点搜索.(把user vector和video vector用某种计算快速地做类似KNN的计算就得到了候选集).
2, 模型架构

底层对video watches和search tokens(当然很稀疏)做embedding,也包括一些其他特征的embedding,形成一个比较dense的特征向量量,代表(用户特征与上下文特征)。
所以DNN的目标就是在用户信息和上下文信息为输入条件下学习用户的embedding向量,学到u就可以计算vi*u,于是就可以通过softmax输出(1)。
embedding通过正常的梯度下降反向传播更新与所有其他模型参数一同学习。
更加详细的候选集生成过程论文不做公开。
3,特征embedding
1)首先是将用户观看过的视频id列表做embedding、取embedding向量的平均值,得到观看embedding向量。
2)同时把用户搜索过的视频id列表也做如上的embedding,得到搜索embedding向量。
3)用户的人口统计学属性做embedding得到特征向量。
4)一些非多值类的特征如性别,还有数值类特征直接做神经网络的输入。
5)还有一些数值类特征,可以利用经验知识,对其进行变换。如对年龄特征进行平方操作,然后作为新的特征。
4,结果对比


可以看出,特征选取较多时,并且模型深度在四层时,可以得到较好的结果。
5,几点启发经验
启发经验一

上图反映了加入视频上传时间这个特征后的模型拟合能力。
分析一下原因:我们之前的推荐器产生的语料库的多项分布将反映在几周的训练窗口中的平均观看可能性,而用户往往喜欢比较新的视频。为了纠正这一点,将训练样本的年龄作为一个特征。在推荐系统提供服务的时候,这个特征设置为零(或绝对值比较小的负数),以反映模型正在训练窗口的末端进行预测。
启发经验二
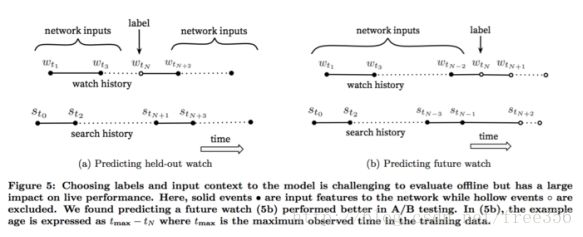
上图反映不同于传统协同过滤的方式(a),我们是从用户的历史视频观看记录中随机拿出来一个作为正样本,然后只用这个视频之前的历史观看记录作为输入(5b)。
分析一下原因:视频的自然消费模式通常导致非常不对称的共同观看概率。 剧集系列通常是顺序地观看,并且用户经常是先发现最广泛流行的流派的艺术家的视频,然后才专注于较小众的。因此,我们发现预测用户的下一个观看视频的效果要好得多,而不是预测随机推出的视频。
启发经验三
本论文对于不同种类输入数据的艺术式处理方式,如可以把离散化数据做连续化处理等,可见上文。
2.3 排序

样本根据展现了是否点击分为正负样本,建模预测用户的观看时长,为此使用加权逻辑回归技术。
模型是基于交叉熵损失函数的逻辑回归模型训练的,用观看时长对正样本做了加权,负样本都用单位权重(即不加权)拟合逻辑回归的函数(Wx+b),然后线上的时候根据e^(f)来预测观看时间,根据这个排名就好。
1,实验结果
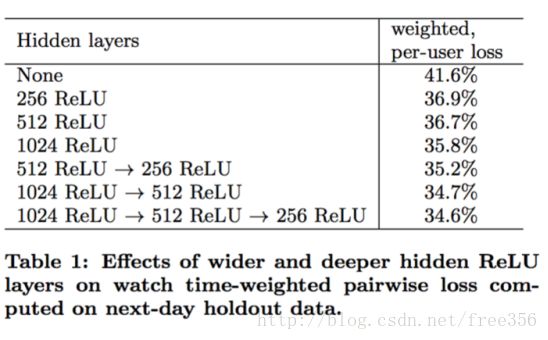
由上图可以看出,当模型两层时,已经可以较低误差。
更多细节内容如关于特征embedding详见附加文档《20180124_算法学习_Word2Vec》。