linux文件系统详解
From:http://soysauce93.blog.51cto.com/7589461/1715655
From:http://blog.csdn.net/new0801/article/details/63687127
Linux 的虚拟文件系统(强烈推荐):http://blog.csdn.net/heikefangxian23/article/details/51579971
鸟哥 Linux 磁盘与文件系统管理:http://linux.vbird.org/linux_basic/0230filesystem.php
一、硬盘物理结构及相关概念
硬盘内部视角实物图
硬盘内部视角逻辑图
扇区、磁道、柱面图
- 磁头(head)数:每个盘片一般有上下两面,分别对应1个磁头,共2个磁头,实现数据的存取
- 磁道(track):当磁盘旋转时,磁头若保持在一个位置上,则每个磁头都会在磁盘表面划出一个圆形轨迹,这些圆形轨迹就叫做磁道,从外边缘的0开始编号,根据磁化方向来存数数据0和1
- 柱面(cylinder):不同盘片的相同编号的磁道构成的圆柱面就被称之为柱面,磁盘的柱面数与一个盘面上的磁道数是相等的
- 扇区(sector):每个磁道都别切分成很多扇形区域,每个磁道的扇区数量相同,每个扇区大小为512字节
- 圆盘(platter):就是硬盘的盘片,为实现大容量,一般都是多个
硬盘的容量=柱面数×磁头数×扇区数×512(字节数)
二、硬盘逻辑结构及相关概念
整体逻辑结构图
MBR(Master Boot Record)
硬盘的0柱面、0磁头、1扇区称为主引导扇区(也叫主引导记录MBR)。它由三个部分组成:硬盘主引导程序(BootLoader)、硬盘分区表DPT(Disk Partition table)和魔数(Magic Number)。
- Boot Loader:主引导程序,启动操作系统的一段代码,占446个字节
- DPT:占64个字节,硬盘中分区有多少以及每一分区的大小都记在其中
- Magic Number:占2个字节,固定为0xAA55或0x55AA,这取决于处理器类型,如果是小端模式处理器(如Intel系列),则该值为0xAA55;如果是大端模式处理器(如Motorola6800),则该值为0x55AA
主分区、扩展分区、逻辑分区示意图
①:主分区+扩展分区<=4
②:扩展分区最多只有一个
③:要么是三主一扩展,要么是四个主分区,那么剩余未分区的空间将无法使用
三、Ext2文件系统逻辑结构
一个分区最开始处是Boot Sector,然后就是多个块组每个块组又可以细分为如下组成部分:
- Super Block:记录此 filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;由于super block很重要 ,在每个 block group都会存一份进行备份.
- GDT:Group Descriptor Table,块组描述符,由很多块组描述符组成,整个分区分成多少个块组就对应有多少个块组描述符。每个块组描述符(Group Descriptor)存储一个块组的描述信息,例如在这个块组中从哪里开始是inode表,从哪里开始是数据块,空闲的inode和数据块还有多少个等等。和超级块类似,块组描述符表在每个块组的开头也都有一份拷贝
- Block Bitmap:块位图就是用来描述整个块组中哪些块已用哪些块空闲的,它本身占一个块,其中的每个bit代表本块组中的一个块,这个bit为1表示该块已用,这个bit为0表示该块空闲可用
- inode Bitmap:和块位图类似,本身占一个块,其中每个bit表示一个inode是否空闲可用
- inode Table:一个文件除了数据需要存储之外,一些描述信息也需要存储,例如文件类型(常规、目录、符号链接等),权限,文件大小,创建/修改/访问时间等,也就是ls-l命令看到的那些信息,这些信息存在inode中而不是数据块中,每个文件都有一个inode,一个块组中的所有inode组成了inode表,inode表占多少个块在格式化时就要决定并写入块组描述符中
- Data Blocks:对于常规文件,文件的数据存储在数据块中,对于目录,该目录下的所有文件名和目录名存储在数据块中,文件名保存在它所在目录的数据块中,除文件名之外,ls -l命令看到的其它信息都保存在该文件的inode中,目录也是一种文件,是一种特殊类型的文件,对于符号链接,如果目标路径名较短则直接保存在inode中以便更快地查找,如果目标路径名较长则分配一个数据块来保存设备文件、FIFO和socket等特殊文件没有数据块,设备文件的主设备号和次设备号保存在inode中
目录文件
注:
①其实文件名和文件类型都是在目录中存放,而文件的其他元数据信息则是在Inode中存放
②文件系统各分区之间物理视角上是并行的,逻辑视角上必须得有上下级关系,所有的文件都必须直接或间接从根开始
Linux 文件系统详解
一、文件系统层次分析
由上而下主要分为用户层、VFS层、文件系统层、缓存层、块设备层、磁盘驱动层、磁盘物理层
用户层:最上面用户层就是我们日常使用的各种程序,需要的接口主要是文件的创建、删除、打开、关闭、写、读等。
VFS层:我们知道Linux分为用户态和内核态,用户态请求硬件资源需要调用System Call通过内核态去实现。用户的这些文件相关操作都有对应的System Call函数接口,接口调用 VFS对应的函数。
文件系统层:不同的文件系统实现了VFS的这些函数,通过指针注册到VFS里面。所以,用户的操作通过VFS转到各种文件系统。文件系统把文件读写命令转化为对磁盘LBA的操作,起了一个翻译和磁盘管理的作用。
缓存层:文件系统底下有缓存,Page Cache,加速性能。对磁盘LBA的读写数据缓存到这里。
块设备层:块设备接口Block Device是用来访问磁盘LBA的层级,读写命令组合之后插入到命令队列,磁盘的驱动从队列读命令执行。Linux设计了电梯算法等对很多LBA的读写进行优化排序,尽量把连续地址放在一起。
磁盘驱动层:磁盘的驱动程序把对LBA的读写命令转化为各自的协议,比如变成ATA命令,SCSI命令,或者是自己硬件可以识别的自定义命令,发送给磁盘控制器。Host Based SSD甚至在块设备层和磁盘驱动层实现了FTL,变成对Flash芯片的操作。
磁盘物理层:读写物理数据到磁盘介质。

二、文件系统结构与工作原理(主要以ext4为例)
我们都知道,windows文件系统主要有fat、ntfs等,而linux文件系统则种类多的很,主要有VFS做了一个软件抽象层,向上提供文件操作接口,向下提供标准接口供不同文件系统对接,下面主要就以EXT4文件系统为例,讲解下文件系统结构与工作原理:


上面两个图大体呈现了ext4文件系统的结构,从中也相信能够初步的领悟到文件系统读写的逻辑过程。下面对上图里边的构成元素做个简单的讲解:
引导块:为磁盘分区的第一个块,记录文件系统分区的一些信息,,引导加载当前分区的程序和数据被保存在这个块中。一般占用2kB,
超级块:
超级块用于存储文件系统全局的配置参数(譬如:块大小,总的块数和inode数)和动态信息(譬如:当前空闲块数和inode数),其处于文件系统开始位置的1k处,所占大小为1k。为了系统的健壮性,最初每个块组都有超级块和组描述符表(以下将用GDT)的一个拷贝,但是当文件系统很大时,这样浪费了很多块(尤其是GDT占用的块多),后来采用了一种稀疏的方式来存储这些拷贝,只有块组号是3, 5 ,7的幂的块组(譬如说1,3,5,7,9,25,49…)才备份这个拷贝。通常情况下,只有主拷贝(第0块块组)的超级块信息被文件系统使用,其它拷贝只有在主拷贝被破坏的情况下才使用。
块组描述符:
GDT用于存储块组描述符,其占用一个或者多个数据块,具体取决于文件系统的大小。它主要包含块位图,inode位图和inode表位置,当前空闲块数,inode数以及使用的目录数(用于平衡各个块组目录数),具体定义可以参见ext3_fs.h文件中struct ext3_group_desc。每个块组都对应这样一个描述符,目前该结构占用32个字节,因此对于块大小为4k的文件系统来说,每个块可以存储128个块组描述符。由于GDT对于定位文件系统的元数据非常重要,因此和超级块一样,也对其进行了备份。GDT在每个块组(如果有备份)中内容都是一样的,其所占块数也是相同的。从上面的介绍可以看出块组中的元数据譬如块位图,inode位图,inode表其位置不是固定的,当然默认情况下,文件系统在创建时其位置在每个块组中都是一样的,如图2所示(假设按照稀疏方式存储,且n不是3,5,7的幂)
块组:
每个块组包含一个块位图块,一个 inode 位图块,一个或多个块用于描述 inode 表和用于存储文件数据的数据块,除此之外,还有可能包含超级块和所有块组描述符表(取决于块组号和文件系统创建时使用的参数)。下面将对这些元数据作一些简要介绍。
块位图:
块位图用于描述该块组所管理的块的分配状态。如果某个块对应的位未置位,那么代表该块未分配,可以用于存储数据;否则,代表该块已经用于存储数据或者该块不能够使用(譬如该块物理上不存在)。由于块位图仅占一个块,因此这也就决定了块组的大小。
Inode位图:
Inode位图用于描述该块组所管理的inode的分配状态。我们知道inode是用于描述文件的元数据,每个inode对应文件系统中唯一的一个号,如果inode位图中相应位置位,那么代表该inode已经分配出去;否则可以使用。由于其仅占用一个块,因此这也限制了一个块组中所能够使用的最大inode数量。
Inode表:
Inode表用于存储inode信息。它占用一个或多个块(为了有效的利用空间,多个inode存储在一个块中),其大小取决于文件系统创建时的参数,由于inode位图的限制,决定了其最大所占用的空间。
以上这几个构成元素所处的磁盘块成为文件系统的元数据块,剩余的部分则用来存储真正的文件内容,称为数据块,而数据块其实也包含数据和目录。
了解了文件系统的结构后,接下来我们来看看操作系统是如何读取一个文件的:

大体过程如下:
1、根据文件所在目录的inode信息,找到目录文件对应数据块
2、根据文件名从数据块中找到对应的inode节点信息
3、从文件inode节点信息中找到文件内容所在数据块块号
4、读取数据块内容
到这里,相信很多人会有一个疑问,我们知道一个文件只有一个Inode节点来存放它的属性信息,那么你可能会想如果一个大文件,那它的block一定是多个的,且可能不连续的,那么inode怎么来表示呢,下面的图告诉你答案:

也就是说,如果文件内容太大,对应数据块数量过多,inode节点本身提供的存储空间不够,会使用其他的间接数据块来存储数据块位置信息,最多可以有三级寻址结构。
到这里,应该都已经非常清楚文件读取的过程了,那么下面再抛出两个疑问:
1、文件的拷贝、剪切的底层过程是怎样的?
2、软连接和硬连接分别是如何实现的?
下面来结合stat命令动手操作一下,便知真相:

1)拷贝文件:创建一个新的inode节点,并且拷贝数据块内容

2)剪切文件:同个分区里边mv,inode节点不变,只是更新目录文件对应数据块里边的文件名和inode对应关系;跨分区mv,则跟拷贝一个道理,需要创建新的inode,因为inode节点不同分区是不能共享的。

3)软连接:创建软连接会创建一个新的inode节点,其对应数据块内容存储所链接的文件名信息,这样原文件即便删除了,重新建立一个同名的文件,软连接依然能够生效。
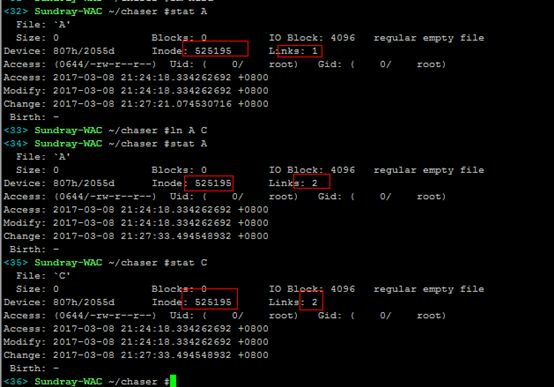
4)硬链接:创建硬链接,并不会新建inode节点,只是links加1,还有再目录文件对应数据块上增加一条文件名和inode对应关系记录;只有将硬链接和原文件都删除之后,文件才会真正删除,即links为0才真正删除。
三、文件顺序读写和随机读写
从前面文章了解了磁盘工作原理之后,也已经明白了为什么文件随机读写速度会比顺序读写差很多,这个问题在windows里边更加明显,为什么呢?究其原因主要与文件系统工作机制有关,fat和ntfs文件系统设计上,每个文件所处的位置相对连续甚至紧靠在一起,这样没有为每个文件留下足够的扩展空间,因此容易产生磁盘碎片,用过windows系统的应该也知道,windows磁盘分区特别提供了磁盘碎片整理的高级功能。如下图:
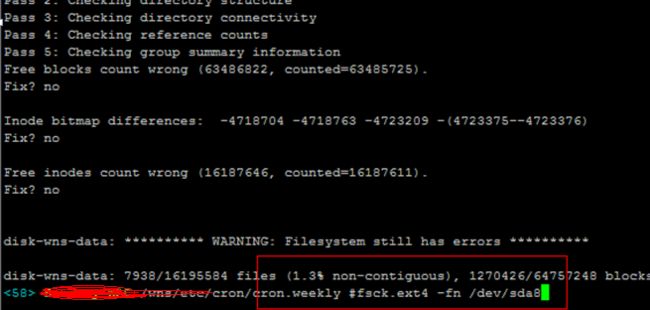
那回过来,看看linux 文件系统ext4,都说linux不需要考虑磁盘碎片,究竟是怎么回事?
主要是因为Linux的文件系统会将文件分散在整个磁盘,在文件之间留有大量的自由空间,而不是像Windows那样将文件一个接一个的放置。当一个文件被编辑了并且变大了,一般都会有足够的自由空间来保存文件。如果碎片真的产生了,文件系统就会尝试在日常使用中将文件移动来减少碎片,所以不需要专门的碎片整理程序。但是,如果磁盘空间占用已经快满了,那碎片是不可避免的,文件系统的设计本来就是用来满足正常情况下使用的。如果磁盘空间不够,那要么就是数据冗余了,要么就该换容量更大的磁盘。你可以使用fsck命令来检测一下一个Linux文件系统的碎片化程度,只需要在输出中查看非连续i节点个数(non-contiguous inodes)就可以了。
四、读取、创建、删除、复制、剪切过程
1、读取文件:例如/etc/httpd/httpd.conf
首先根是自引用的,也就是根的Inode号是已知的,再根据Inode Table可以知道根的Inode号对应的Block号,然后找到对应的block,block里面有个目录项,也即Dentry,每个目录项记录了根下所有直接子目录的Inode与文件名的对应关系(也包括文件类型等),例如var对应的Inode号为2883585,etc对应的Inode号为1507329等等,此时找到etc文件对应的Inode号,再通过查找Inode Table可以得知etc文件对应的Block,再通过读取Block里面的Dentry可以得知httpd文件对应的Inode,再查找Inode Table可以查到httpd文件对应的Block,再在对应的Block里面查询Dentry可以得知httpd.conf文件对应的Inode号,再次查询Inode Table可以找到对应的Block,于是数据就可以读取了
2、创建文件:例如/etc/testfile.txt
想要创建一个文件,首先得先给这个文件分配Inode和Block。首先扫描Inode Bitmap查找空闲Inode,再去Inode Table中写入想要创建文件的元数据,例如权限、属主属组、大小、时间戳、以及这个Inode对应所占据的Block。然后再找到根的Inode,找到根对应的Block,里面Dentry记录了etc及其对应的Inode,再通过Inode Table找到etc文件对应的Block,于是在Dentry里面添加一条记录,testfile.txt与其对应的Inode号,文件类型等信息。到此一个文件便创建了。
3、删除文件:例如/etc/fstab
删除文件直接上级目录(etc)里面的那条Dentry记录,Inode Bitmap里面把文件(fstab)原先对应的Inode号标记为未使用,Block Bitmap中把文件(fstab)原先对应的Block标记为未使用。删除文件本身并没有删除文件所对应的Block和Inode,也就是说Block上的数据并没有被抹除,除非后面向其Block中覆盖数据
4、复制文件
复制文件本质就是新建一个文件,并填充源文件数据的过程,详细可参考上面的创建和读取文件过程
5、剪切文件
在同一个分区下,剪切速度非常快,这是因为其本质也只是将Dentry记录换一个目录而已,所以根本就不涉及什么耗时的操作。而跨分区剪切文件的过程其实就是在另外一个分区上创建一个新文件,并复制,复制完成之后再删除原先分区上数据的一个过程。
五、软连接与硬链接联系与区别
软连接(符号链接)与硬链接联系
- 软连接本质:在Inode Table中本该存储Block号信息的地方存储了一个路径,如:/etc/httpd/httpd.conf,所以软连接文件的大小都是其对应的文件路径的字符个数
- 硬链接本质:Inode号相同的文件彼此都可称为硬链接,只是再另外一个目录中添加的Dentry记录为同一个Inode而已
ln - make links between files # 给文件创建链接
SYNOPSIS
ln [-s -v] SRC DEST
-s:创建软链接
-v:显示创建详细过程
[root@soysauce test]# ll /etc/rc.sysinit # 权限为777,并且大小为所指向的字符个数
lrwxrwxrwx. 1 root root 15 Aug 28 10:32 /etc/rc.sysinit -> rc.d/rc.sysinit
[root@soysauce test]# ln -s inittab inittab_soft # 创建软连接
[root@soysauce test]# ln inittab inittab_hard # 创建硬链接
[root@soysauce test]# ll -i
total 8
265301 -rw-r--r-- 2 root root 884 Nov 23 13:25 inittab
265301 -rw-r--r-- 2 root root 884 Nov 23 13:25 inittab_hard # 硬链接inode号与源文件相同
265310 lrwxrwxrwx 1 root root 7 Nov 23 13:55 inittab_soft -> inittab
[root@soysauce test]# ll -i
total 8
265301 -rw-r--r-- 2 root root 884 Nov 23 13:25 inittab # 此时硬链接次数都为2
265301 -rw-r--r-- 2 root root 884 Nov 23 13:25 inittab_hard
265310 lrwxrwxrwx 1 root root 7 Nov 23 13:55 inittab_soft -> inittab
[root@soysauce test]# rm -f inittab # 删除源文件
[root@soysauce test]# ll -i
total 4
265301 -rw-r--r-- 1 root root 884 Nov 23 13:25 inittab_hard # 此时硬链接次数变为了1
265310 lrwxrwxrwx 1 root root 7 Nov 23 13:55 inittab_soft -> inittab # 此时软连接也一直在闪烁
[root@soysauce test]# head -3 inittab_hard # 因为篇幅原因,顾只查看3行
# inittab is only used by upstart for the default runlevel.
#
# ADDING OTHER CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.软连接(符号链接)与硬链接区别
- 硬链接
①只能对文件创建,不能应用于目录
②不能跨文件系统
③创建硬链接会增加文件被链接的次数
④硬链接次数为1时,再删除就是彻底删除了
⑤删除源文件不会影响链接文件 - 软链接:
①可应用于目录
②可以跨文件系统
③不会增加被链接文件的链接次数
④其大小为指定的路径所包含的字符个数
⑤删除源文件会影响链接文件
硬链接与复制的区别
互为硬链接的两文件inode号肯定是相同的,对应的block号也是相同的;而复制的文件inode号和block号也肯定不相同,只是block里面存储的数据是一样而已
六、虚拟文件系统
引言
Linux 中允许众多不同的文件系统共存,如 ext2, ext3, vfat 等。通过使用同一套文件 I/O 系统 调用即可对 Linux 中的任意文件进行操作而无需考虑其所在的具体文件系统格式;更进一步,对文件的 操作可以跨文件系统而执行。如图 1 所示,我们可以使用 cp 命令从 vfat 文件系统格式的硬盘拷贝数据到 ext3 文件系统格式的硬盘;而这样的操作涉及到两个不同的文件系统。

“一切皆是文件”是 Unix/Linux 的基本哲学之一。不仅普通的文件,目录、字符设备、块设备、 套接字等在 Unix/Linux 中都是以文件被对待;它们虽然类型不同,但是对其提供的却是同一套操作界面。

而虚拟文件系统正是实现上述两点 Linux 特性的关键所在。虚拟文件系统(Virtual File System, 简称 VFS), 是 Linux 内核中的一个软件层,用于给用户空间的程序提供文件系统接口;同时,它也提供了内核中的一个 抽象功能,允许不同的文件系统共存。系统中所有的文件系统不但依赖 VFS 共存,而且也依靠 VFS 协同工作。
为了能够支持各种实际文件系统,VFS 定义了所有文件系统都支持的基本的、概念上的接口和数据 结构;同时实际文件系统也提供 VFS 所期望的抽象接口和数据结构,将自身的诸如文件、目录等概念在形式 上与VFS的定义保持一致。换句话说,一个实际的文件系统想要被 Linux 支持,就必须提供一个符合VFS标准 的接口,才能与 VFS 协同工作。实际文件系统在统一的接口和数据结构下隐藏了具体的实现细节,所以在VFS 层和内核的其他部分看来,所有文件系统都是相同的。图3显示了VFS在内核中与实际的文件系统的协同关系。

我们已经知道,正是由于在内核中引入了VFS,跨文件系统的文件操作才能实现,“一切皆是文件” 的口号才能承诺。而为什么引入了VFS,就能实现这两个特性呢?在接下来,我们将以这样的一个思路来切入 文章的正题:我们将先简要介绍下用以描述VFS模型的一些数据结构,总结出这些数据结构相互间的关系;然后 选择两个具有代表性的文件I/O操作sys_open()和sys_read()来详细说明内核是如何借助VFS和具体的文件系统打 交道以实现跨文件系统的文件操作和承诺“一切皆是文件”的口号。
虚拟文件系统又称虚拟文件系统转换(Virual Filesystem Switch ,简称VFS)。说它虚拟,是因为它所有的数据结构都是在运行以后才建立,并在卸载时删除,而在磁盘上并没有存储这些数据结构,显然如果只有VFS,系统是无法工作的,因为它的这些数据结构不能凭空而来,只有与实际的文件系统,如Ext2、Minix、MSDOS、VFAT等相结合,才能开始工作,所以VFS并不是一个真正的文件系统。与VFS相对,我们称Ext2、Minix、MSDOS等为具体文件系统。
VFS与内核其它子系统之间关系
VFS提供一个统一的接口(实际上就是file_operatoin数据结构),一个具体文件系统要想被Linux支持,就必须按照这个接口编写自己的操作函数,而将自己的细节对内核其它子系统隐藏起来。因而,对内核其它子系统以及运行在操作系统之上的用户程序而言,所有的文件系统都是一样的。实际上,要支持一个新的文件系统,主要任务就是编写这些接口函数。
概括说来,VFS主要有以下几个作用:
- 对具体文件系统的数据结构进行抽象,以一种统一的数据结构进行管理。
- 接受用户层的系统调用 ,例如write、open、stat、link等等。
- 支持多种具体文件系统之间相互访问。
- 接受内核其他子系统的操作请求,特别是内存管理子系统
注:以上内容都是摘自深入分析Linux内核源码第8章第一节VFS概述
VFS数据结构
一些基本概念
从本质上讲,文件系统是特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。为了描述 这个结构,Linux引入了一些基本概念:
文件 一组在逻辑上具有完整意义的信息项的系列。在Linux中,除了普通文件,其他诸如目录、设备、套接字等 也以文件被对待。总之,“一切皆文件”。
目录 目录好比一个文件夹,用来容纳相关文件。因为目录可以包含子目录,所以目录是可以层层嵌套,形成 文件路径。在Linux中,目录也是以一种特殊文件被对待的,所以用于文件的操作同样也可以用在目录上。
目录项 在一个文件路径中,路径中的每一部分都被称为目录项;如路径/home/source/helloworld.c中,目录 /, home, source和文件 helloworld.c都是一个目录项。
索引节点 用于存储文件的元数据的一个数据结构。文件的元数据,也就是文件的相关信息,和文件本身是两个不同 的概念。它包含的是诸如文件的大小、拥有者、创建时间、磁盘位置等和文件相关的信息。
超级块 用于存储文件系统的控制信息的数据结构。描述文件系统的状态、文件系统类型、大小、区块数、索引节 点数等,存放于磁盘的特定扇区中。
如上的几个概念在磁盘中的位置关系如图所示。

关于文件系统的三个易混淆的概念:
创建 以某种方式格式化磁盘的过程就是在其之上建立一个文件系统的过程。创建文现系统时,会在磁盘的特定位置写入 关于该文件系统的控制信息。
注册 向内核报到,声明自己能被内核支持。一般在编译内核的时侯注册;也可以加载模块的方式手动注册。注册过程实 际上是将表示各实际文件系统的数据结构struct file_system_type 实例化。
安装 也就是我们熟悉的mount操作,将文件系统加入到Linux的根文件系统的目录树结构上;这样文件系统才能被访问。
VFS数据结构
VFS依靠四个主要的数据结构和一些辅助的数据结构来描述其结构信息,这些数据结构表现得就像是对象; 每个主要对象中都包含由操作函数表构成的操作对象,这些操作对象描述了内核针对这几个主要的对象可以进行的操作。
超级块对象
存储一个已安装的文件系统的控制信息,代表一个已安装的文件系统;每次一个实际的文件系统被安装时, 内核会从磁盘的特定位置读取一些控制信息来填充内存中的超级块对象。一个安装实例和一个超级块对象一一对应。 超级块通过其结构中的一个域s_type记录它所属的文件系统类型。
根据第三部分追踪源代码的需要,以下是对该超级块结构的部分相关成员域的描述,(如下同):
超级块
struct super_block { //超级块数据结构
struct list_head s_list; /*指向超级块链表的指针*/
……
struct file_system_type *s_type; /*文件系统类型*/
struct super_operations *s_op; /*超级块方法*/
……
struct list_head s_instances; /*该类型文件系统*/
……
};
struct super_operations { //超级块方法
……
//该函数在给定的超级块下创建并初始化一个新的索引节点对象
struct inode *(*alloc_inode)(struct super_block *sb);
……
//该函数从磁盘上读取索引节点,并动态填充内存中对应的索引节点对象的剩余部分
void (*read_inode) (struct inode *);
……
};索引节点对象
索引节点对象存储了文件的相关信息,代表了存储设备上的一个实际的物理文件。当一个 文件首次被访问时,内核会在内存中组装相应的索引节点对象,以便向内核提供对一个文件进行操 作时所必需的全部信息;这些信息一部分存储在磁盘特定位置,另外一部分是在加载时动态填充的。
索引节点
struct inode {//索引节点结构
……
struct inode_operations *i_op; /*索引节点操作表*/
struct file_operations *i_fop; /*该索引节点对应文件的文件操作集*/
struct super_block *i_sb; /*相关的超级块*/
……
};
struct inode_operations { //索引节点方法
……
//该函数为dentry对象所对应的文件创建一个新的索引节点,主要是由open()系统调用来调用
int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
//在特定目录中寻找dentry对象所对应的索引节点
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
……
};目录项对象
引入目录项的概念主要是出于方便查找文件的目的。一个路径的各个组成部分,不管是目录还是 普通的文件,都是一个目录项对象。如,在路径/home/source/test.c中,目录 /, home, source和文件 test.c都对应一个目录项对象。不同于前面的两个对象,目录项对象没有对应的磁盘数据结构,VFS在遍 历路径名的过程中现场将它们逐个地解析成目录项对象。
目录项
struct dentry {//目录项结构
……
struct inode *d_inode; /*相关的索引节点*/
struct dentry *d_parent; /*父目录的目录项对象*/
struct qstr d_name; /*目录项的名字*/
……
struct list_head d_subdirs; /*子目录*/
……
struct dentry_operations *d_op; /*目录项操作表*/
struct super_block *d_sb; /*文件超级块*/
……
};
struct dentry_operations {
//判断目录项是否有效;
int (*d_revalidate)(struct dentry *, struct nameidata *);
//为目录项生成散列值;
int (*d_hash) (struct dentry *, struct qstr *);
……
};文件对象
文件对象是已打开的文件在内存中的表示,主要用于建立进程和磁盘上的文件的对应关系。它由sys_open() 现场创建,由sys_close()销毁。文件对象和物理文件的关系有点像进程和程序的关系一样。当我们站在用户空间来看 待VFS,我们像是只需与文件对象打交道,而无须关心超级块,索引节点或目录项。因为多个进程可以同时打开和操作 同一个文件,所以同一个文件也可能存在多个对应的文件对象。文件对象仅仅在进程观点上代表已经打开的文件,它 反过来指向目录项对象(反过来指向索引节点)。一个文件对应的文件对象可能不是惟一的,但是其对应的索引节点和 目录项对象无疑是惟一的。
文件对象
struct file {
……
struct list_head f_list; /*文件对象链表*/
struct dentry *f_dentry; /*相关目录项对象*/
struct vfsmount *f_vfsmnt; /*相关的安装文件系统*/
struct file_operations *f_op; /*文件操作表*/
……
};
struct file_operations {
……
//文件读操作
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
……
//文件写操作
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
……
int (*readdir) (struct file *, void *, filldir_t);
……
//文件打开操作
int (*open) (struct inode *, struct file *);
……
};其他VFS对象
和文件系统相关
根据文件系统所在的物理介质和数据在物理介质上的组织方式来区分不同的文件系统类型的。 file_system_type结构用于描述具体的文件系统的类型信息。被Linux支持的文件系统,都有且仅有一 个file_system_type结构而不管它有零个或多个实例被安装到系统中。
而与此对应的是每当一个文件系统被实际安装,就有一个vfsmount结构体被创建,这个结构体对应一个安装点。
和文件系统相关
struct file_system_type {
const char *name; /*文件系统的名字*/
struct subsystem subsys; /*sysfs子系统对象*/
int fs_flags; /*文件系统类型标志*/
/*在文件系统被安装时,从磁盘中读取超级块,在内存中组装超级块对象*/
struct super_block *(*get_sb) (struct file_system_type*,
int, const char*, void *);
void (*kill_sb) (struct super_block *); /*终止访问超级块*/
struct module *owner; /*文件系统模块*/
struct file_system_type * next; /*链表中的下一个文件系统类型*/
struct list_head fs_supers; /*具有同一种文件系统类型的超级块对象链表*/
};
struct vfsmount
{
struct list_head mnt_hash; /*散列表*/
struct vfsmount *mnt_parent; /*父文件系统*/
struct dentry *mnt_mountpoint; /*安装点的目录项对象*/
struct dentry *mnt_root; /*该文件系统的根目录项对象*/
struct super_block *mnt_sb; /*该文件系统的超级块*/
struct list_head mnt_mounts; /*子文件系统链表*/
struct list_head mnt_child; /*子文件系统链表*/
atomic_t mnt_count; /*使用计数*/
int mnt_flags; /*安装标志*/
char *mnt_devname; /*设备文件名*/
struct list_head mnt_list; /*描述符链表*/
struct list_head mnt_fslink; /*具体文件系统的到期列表*/
struct namespace *mnt_namespace; /*相关的名字空间*/
};和进程相关
打开的文件集
struct files_struct {//打开的文件集
atomic_t count; /*结构的使用计数*/
……
int max_fds; /*文件对象数的上限*/
int max_fdset; /*文件描述符的上限*/
int next_fd; /*下一个文件描述符*/
struct file ** fd; /*全部文件对象数组*/
……
};
struct fs_struct {//建立进程与文件系统的关系
atomic_t count; /*结构的使用计数*/
rwlock_t lock; /*保护该结构体的锁*/
int umask; /*默认的文件访问权限*/
struct dentry * root; /*根目录的目录项对象*/
struct dentry * pwd; /*当前工作目录的目录项对象*/
struct dentry * altroot; /*可供选择的根目录的目录项对象*/
struct vfsmount * rootmnt; /*根目录的安装点对象*/
struct vfsmount * pwdmnt; /*pwd的安装点对象*/
struct vfsmount * altrootmnt;/*可供选择的根目录的安装点对象*/
};和路径查找相关
辅助查找
struct nameidata {
struct dentry *dentry; /*目录项对象的地址*/
struct vfsmount *mnt; /*安装点的数据*/
struct qstr last; /*路径中的最后一个component*/
unsigned int flags; /*查找标识*/
int last_type; /*路径中的最后一个component的类型*/
unsigned depth; /*当前symbolic link的嵌套深度,不能大于6*/
char *saved_names[MAX_NESTED_LINKS + 1];/
/*和嵌套symbolic link 相关的pathname*/
union {
struct open_intent open; /*说明文件该如何访问*/
} intent; /*专用数据*/
};对象间的联系
如上的数据结构并不是孤立存在的。正是通过它们的有机联系,VFS才能正常工作。如下的几张图是对它们之间的联系的描述。
如图5所示,被Linux支持的文件系统,都有且仅有一个file_system_type结构而不管它有零个或多个实例被安装到系统 中。每安装一个文件系统,就对应有一个超级块和安装点。超级块通过它的一个域s_type指向其对应的具体的文件系统类型。具体的 文件系统通过file_system_type中的一个域fs_supers链接具有同一种文件类型的超级块。同一种文件系统类型的超级块通过域s_instances链 接。
超级块、安装点和具体的文件系统的关系

从图可知:进程通过task_struct中的一个域files_struct files来了解它当前所打开的文件对象;而我们通常所说的文件 描述符其实是进程打开的文件对象数组的索引值。文件对象通过域f_dentry找到它对应的dentry对象,再由dentry对象的域d_inode找 到它对应的索引结点,这样就建立了文件对象与实际的物理文件的关联。最后,还有一点很重要的是, 文件对象所对应的文件操作函数 列表是通过索引结点的域i_fop得到的。图6对第三部分源码的理解起到很大的作用。
进程与超级块、文件、索引结点、目录项的关系

基于VFS的文件I/O
到目前为止,文章主要都是从理论上来讲述VFS的运行机制;接下来我们将深入源代码层中,通过阐述两个具有代表性的系统 调用sys_open()和sys_read()来更好地理解VFS向具体文件系统提供的接口机制。由于本文更关注的是文件操作的整个流程体制,所以我 们在追踪源代码时,对一些细节性的处理不予关心。又由于篇幅所限,只列出相关代码。本文中的源代码来自于linux-2.6.17内核版本。
在深入sys_open()和sys_read()之前,我们先概览下调用sys_read()的上下文。图7描述了从用户空间的read()调用到数据从 磁盘读出的整个流程。当在用户应用程序调用文件I/O read()操作时,系统调用sys_read()被激发,sys_read()找到文件所在的具体文件 系统,把控制权传给该文件系统,最后由具体文件系统与物理介质交互,从介质中读出数据。
从物理介质读数据的过程

解决问题
跨文件系统的文件操作的基本原理
到此,我们也就能够解释在Linux中为什么能够跨文件系统地操作文件了。举个例子,将vfat格式的磁盘上的一个文件a.txt拷贝到ext3格式的磁 盘上,命名为b.txt。这包含两个过程,对a.txt进行读操作,对b.txt进行写操作。读写操作前,需要先打开文件。由前面的分析可知,打开文件 时,VFS会知道该文件对应的文件系统格式,以后操作该文件时,VFS会调用其对应的实际文件系统的操作方法。所以,VFS调用vfat的读文件方法将 a.txt的数据读入内存;在将a.txt在内存中的数据映射到b.txt对应的内存空间后,VFS调用ext3的写文件方法将b.txt写入磁盘;从而 实现了最终的跨文件系统的复制操作。
“一切皆是文件”的实现根本”
不论是普通的文件,还是特殊的目录、设备等,VFS都将它们同等看待成文件,通过同一套文件操作界面来对它们进行操作。操作文件时需先打开;打开文件 时,VFS会知道该文件对应的文件系统格式;当VFS把控制权传给实际的文件系统时,实际的文件系统再做出具体区分,对不同的文件类型执行不同的操作。这 也就是“一切皆是文件”的根本所在。
总结
VFS即虚拟文件系统是Linux文件系统中的一个抽象软件层;因为它的支持,众多不同的实际文件系统才能在Linux中共存,跨文件系统操作才能实现。 VFS借助它四个主要的数据结构即超级块、索引节点、目录项和文件对象以及一些辅助的数据结构,向Linux中不管是普通的文件还是目录、设备、套接字等 都提供同样的操作界面,如打开、读写、关闭等。只有当把控制权传给实际的文件系统时,实际的文件系统才会做出区分,对不同的文件类型执行不同的操作。由此 可见,正是有了VFS的存在,跨文件系统操作才能执行,Unix/Linux中的“一切皆是文件”的口号才能够得以实现。
七、文件系统管理相关命令
相关命令
fdisk # Linux分区表操作工具软件
mke2fs # 创建ext2/ext3/ext4文件系统
blkid # 定位或打印块设备属性信息
e2lable # 改变ext2/ext3/ext4文件系统的卷标
tune2fs # 调整文件系统参数信息
dumpe2fs # 显示文件系统超级块信息和块组描述符
fsck # 检查并修复Linux文件系统
e2fsck # 检查并修复ext系列文件系统
mount # 挂载文件系统
fuser # 报告进程使用的文件或是网络套接字
free # 显示系统中已用的和未用的内存总和
du # 报告磁盘空间使用情况
df # 报告文件系统磁盘空间的使用情况
dd # 复制文件并对原文件进行转化和格式化处理
mknod # 创建块设备文件或字符设备文件 1、fdisk
fdisk - Partition table manipulator for Linux # Linux分区表操作工具软件
SYNOPSIS
fdisk [-uc] [-b sectorsize] [-C cyls] [-H heads] [-S sects] device
交互式命令
m:显示帮助信息
p: 显示当前硬件的分区,包括没保存的改动
n: 创建新分区,e: 扩展分区,p: 主分区
d: 删除一个分区
w: 保存退出
q: 不保存退出
t: 修改分区类型,L: 查看所有支持的分区类型
l: 显示所有支持的分区类型
[root@soysauce ~]# fdisk /dev/sdb
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): p # 显示所有的分区
Disk /dev/sdb: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x84c99918
Device Boot Start End Blocks Id System
/dev/sdb1 1 262 2104483+ 83 Linux
Command (m for help): n # 新建一个分区
Command action
e extended
p primary partition (1-4)
p # 建立主分区
Partition number (1-4): 2 # 指定分区号
First cylinder (263-2610, default 263): # 分区起始柱面,默认即可
Using default value 263
Last cylinder, +cylinders or +size{K,M,G} (263-2610, default 2610): +3G # 分区结束柱面,可直接指定大小
Command (m for help): t # 修改分区类型
Partition number (1-4): 2
Hex code (type L to list codes): L # 输入t之后是L选项,如果直接查看则是l
0 Empty 24 NEC DOS 81 Minix / old Lin bf Solaris
1 FAT12 39 Plan 9 82 Linux swap / So c1 DRDOS/sec (FAT-
2 XENIX root 3c PartitionMagic 83 Linux c4 DRDOS/sec (FAT-
3 XENIX usr 40 Venix 80286 84 OS/2 hidden C: c6 DRDOS/sec (FAT-
4 FAT16 <32M 41 PPC PReP Boot 85 Linux extended c7 Syrinx
5 Extended 42 SFS 86 NTFS volume set da Non-FS data
6 FAT16 4d QNX4.x 87 NTFS volume set db CP/M / CTOS / .
7 HPFS/NTFS 4e QNX4.x 2nd part 88 Linux plaintext de Dell Utility
8 AIX 4f QNX4.x 3rd part 8e Linux LVM df BootIt
9 AIX bootable 50 OnTrack DM 93 Amoeba e1 DOS access
a OS/2 Boot Manag 51 OnTrack DM6 Aux 94 Amoeba BBT e3 DOS R/O
b W95 FAT32 52 CP/M 9f BSD/OS e4 SpeedStor
c W95 FAT32 (LBA) 53 OnTrack DM6 Aux a0 IBM Thinkpad hi eb BeOS fs
e W95 FAT16 (LBA) 54 OnTrackDM6 a5 FreeBSD ee GPT
f W95 Ext'd (LBA) 55 EZ-Drive a6 OpenBSD ef EFI (FAT-12/16/
10 OPUS 56 Golden Bow a7 NeXTSTEP f0 Linux/PA-RISC b
11 Hidden FAT12 5c Priam Edisk a8 Darwin UFS f1 SpeedStor
12 Compaq diagnost 61 SpeedStor a9 NetBSD f4 SpeedStor
14 Hidden FAT16 <3 63 GNU HURD or Sys ab Darwin boot f2 DOS secondary
16 Hidden FAT16 64 Novell Netware af HFS / HFS+ fb VMware VMFS
17 Hidden HPFS/NTF 65 Novell Netware b7 BSDI fs fc VMware VMKCORE
18 AST SmartSleep 70 DiskSecure Mult b8 BSDI swap fd Linux raid auto
1b Hidden W95 FAT3 75 PC/IX bb Boot Wizard hid fe LANstep
1c Hidden W95 FAT3 80 Old Minix be Solaris boot ff BBT
1e Hidden W95 FAT1
Hex code (type L to list codes): 82
Changed system type of partition 2 to 82 (Linux swap / Solaris)
Command (m for help): w # 保存退出
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.
[root@soysauce ~]# cat /proc/partitions # 查看当前内核已识别的分区
major minor #blocks name
8 0 20971520 sda
8 1 512000 sda1
8 2 20458496 sda2
8 16 20971520 sdb
8 17 2104483 sdb1
253 0 18423808 dm-0
253 1 2031616 dm-1
[root@soysauce ~]# partx -a /dev/sdb # 通知内核重读分区表信息,RHEL5或者CentOS上一般是partprobe命令
BLKPG: Device or resource busy
error adding partition 1
[root@soysauce ~]# cat /proc/partitions
major minor #blocks name
8 0 20971520 sda
8 1 512000 sda1
8 2 20458496 sda2
8 16 20971520 sdb
8 17 2104483 sdb1
8 18 3156772 sdb2 # 此时sdb2已经读取到了
253 0 18423808 dm-0
253 1 2031616 dm-1
[root@soysauce ~]# mkswap -L MYDATA/dev/sdb2 # 格式化交换分区
Setting up swapspace version 1, size = 3156768 KiB
LABEL=MYDATA, UUID=2f0ca25b-e6f8-45ae-a239-00f5b38f7275
[root@soysauce ~]# free -m
total used free shared buffers cached
Mem: 988 176 812 0 67 37
-/+ buffers/cache: 71 917
Swap: 1983 0 1983 # 此时还未启用刚才创建的那个交换分区
[root@soysauce ~]# swapon /dev/sdb2 # 启用刚刚创建的交换分区
[root@soysauce ~]# free -m
total used free shared buffers cached
Mem: 988 178 810 0 67 37
-/+ buffers/cache: 73 915
Swap: 5066 0 5066 # 此时可以看到已然生效
[root@soysauce ~]# swapoff /dev/sdb2 # 关闭交换分区
[root@soysauce ~]# free -m
total used free shared buffers cached
Mem: 988 176 812 0 67 37
-/+ buffers/cache: 71 917
Swap: 1983 0 1983 # 此时可以看到已然关闭2、mke2fs
mke2fs - create an ext2/ext3/ext4 filesystem # 创建ext2/ext3/ext4文件系统
SYNOPSIS
mke2fs [options] DEVICE
-j:创建ext3类型文件系统
-b BLOCK_SIZE:指定块大小,默认为4096;可用取值为1024、2048或4096
-L LABEL:指定分区卷标
-m #:指定预留给超级用户的块数百分比,默认值为%5
-i #:用于指定为多少字节的空间创建一个inode,默认为8192;应为block的2^n倍
-t FSTYPE:指定文件系统类型
-N #:指定inode个数
-F:强制创建文件系统,不管其是否处于挂载状态
-E:用户指定额外文件系统属性
-q:执行时不显示任何信息,常用于脚本
-c:检查是否有损坏的区块
[root@soysauce ~]# fdisk /dev/sdb # 创建一个分区完整过程
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0x84c99918.
Changes will remain in memory only, until you decide to write them.
After that, of course, the previous content won't be recoverable.
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): n # 新建一个分区
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1 # 自己选择分区号,1-4中选
First cylinder (1-2610, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-2610, default 2610): +2G
Command (m for help): w # 保存创建的分区并退出
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
[root@soysauce ~]# cat /proc/partitions # 查看当前内核已经读取到的分区信息
major minor #blocks name
8 0 20971520 sda
8 1 512000 sda1
8 2 20458496 sda2
8 16 20971520 sdb
8 17 2104483 sdb1 # 我这里内核已经读取到了sdb1,而在CentOS5上可能需要执行prartprobe命令
253 0 18423808 dm-0
253 1 2031616 dm-1
[root@soysauce ~]# mke2fs -j /dev/sdb1 # 创建ext3格式的文件系统
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
131648 inodes, 526120 blocks
26306 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=541065216
17 block groups
32768 blocks per group, 32768 fragments per group
7744 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 24 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@soysauce ~]# mke2fs -t ext4 /dev/sdb1 # 创建ext4格式的文件系统
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
131648 inodes, 526120 blocks
26306 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=541065216
17 block groups
32768 blocks per group, 32768 fragments per group
7744 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 20 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.3、blkid
blkid - command-line utility to locate/print block device attributes # 定位或打印块设备属性信息
SYNOPSIS
blkid [options] [DEVICE]
-s :显示指定信息,默认显示所有信息
-o format:指定显示格式,常用list
[root@soysauce ~]# blkid
/dev/sda1: UUID="7a79d653-e9b7-43f2-a2c1-e41af29b3f5d" TYPE="ext4"
/dev/sda2: UUID="aNiMxY-uTa4-IcVC-1FD7-i2S9-kwnV-lF4BMS" TYPE="LVM2_member"
/dev/mapper/vg_centos6-lv_root: UUID="09b9916a-7424-4be3-9dc8-5222b699ef33" TYPE="ext4"
/dev/mapper/vg_centos6-lv_swap: UUID="2a88de6d-5333-4077-b13e-117bbf60c5d6" TYPE="swap"
[root@soysauce ~]# blkid -o device # 只显示设备名
/dev/sda1
/dev/sda2
/dev/mapper/vg_centos6-lv_root
/dev/mapper/vg_centos6-lv_swap
[root@soysauce ~]# blkid -s UUID /dev/sda1 # 只显示/dev/sda1的UUID
/dev/sda1: UUID="7a79d653-e9b7-43f2-a2c1-e41af29b3f5d" 4、e2lable
e2label - Change the label on an ext2/ext3/ext4 filesystem # 改变ext2/ext3/ext4文件系统的卷标
SYNOPSIS
e2label device [ new-label ]
[root@soysauce ~]# e2label /dev/sdb1 SOYSAUCE # 修改/dev/sdb1卷标
[root@soysauce ~]# e2label /dev/sdb1 # 查看/dev/sdb1卷标
SOYSAUCE5、tune2fs
tune2fs - adjust tunable filesystem parameters on ext2/ext3/ext4 filesystems # 调整文件系统参数信息
SYNOPSIS
tune2fs [options] DEVICE
-j:不损害原有数据,将ext2升级至ext3
-L LABEL:设定或修改卷标
-m #:调整预留百分比
-r #:指定预留块数
-o:设定默认挂载选项,常用的acl
-c #:指定挂载次数达到#次之后进行自检,0或-1表关闭此功能
-C #:指定文件系统已经被挂载的次数
-i #:每挂载使用多少天后进行自检;0或-1表示关闭此功能
-l:显示超级块中的信息
[root@soysauce ~]# tune2fs -j /dev/sdb1 # 无损升级至ext3文件系统
tune2fs 1.41.12 (17-May-2010)
Creating journal inode: done
This filesystem will be automatically checked every 22 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@soysauce ~]# blkid /dev/sdb1
/dev/sdb1: UUID="79d72bb3-9b67-45cd-8e77-2b37349db88c" SEC_TYPE="ext2" TYPE="ext3"
[root@soysauce ~]# tune2fs -m 8 /dev/sdb1 # 调整预留块百分比为%8
tune2fs 1.41.12 (17-May-2010)
Setting reserved blocks percentage to 8% (42089 blocks)
[root@soysauce ~]# tune2fs -l /dev/sdb1 # 查看超级块信息
tune2fs 1.41.12 (17-May-2010)
Filesystem volume name:
Last mounted on:
Filesystem UUID: 79d72bb3-9b67-45cd-8e77-2b37349db88c
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype sparse_super large_file
Filesystem flags: signed_directory_hash
Default mount options: (none)
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 131648
Block count: 526120
Reserved block count: 42089
Free blocks: 500671
Free inodes: 131637
First block: 0
Block size: 4096
Fragment size: 4096
Reserved GDT blocks: 128
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 7744
Inode blocks per group: 484
Filesystem created: Mon Nov 23 20:24:17 2015
Last mount time: n/a
Last write time: Mon Nov 23 20:26:43 2015
Mount count: 0
Maximum mount count: 22
Last checked: Mon Nov 23 20:24:17 2015
Check interval: 15552000 (6 months)
Next check after: Sat May 21 20:24:17 2016
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 98e59dee-37cb-4cf4-96bb-47ab22e61c0d
Journal backup: inode blocks 6、dumpe2fs
dumpe2fs - dump ext2/ext3/ext4 filesystem information # 显示文件系统超级块信息和块组描述符
SYNOPSIS
dumpe2fs [options] DEVICE
-h:查看超级块信息,但不包括GDT(块组描述表)
[root@soysauce ~]# dumpe2fs -h /dev/sdb1 # 查看超级块信息,不显示GDT
dumpe2fs 1.41.12 (17-May-2010)
Filesystem volume name:
Last mounted on:
Filesystem UUID: 79d72bb3-9b67-45cd-8e77-2b37349db88c
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype sparse_super large_file
Filesystem flags: signed_directory_hash
Default mount options: (none)
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 131648
Block count: 526120
Reserved block count: 42089
Free blocks: 500671
Free inodes: 131637
First block: 0
Block size: 4096
Fragment size: 4096
Reserved GDT blocks: 128
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 7744
Inode blocks per group: 484
Filesystem created: Mon Nov 23 20:24:17 2015
Last mount time: n/a
Last write time: Mon Nov 23 20:26:43 2015
Mount count: 0
Maximum mount count: 22
Last checked: Mon Nov 23 20:24:17 2015
Check interval: 15552000 (6 months)
Next check after: Sat May 21 20:24:17 2016
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 98e59dee-37cb-4cf4-96bb-47ab22e61c0d
Journal backup: inode blocks
Journal features: (none)
Journal size: 64M
Journal length: 16384
Journal sequence: 0x00000001
Journal start: 0 7、fsck
fsck - check and repair a Linux file system # 检查并修复Linux文件系统
SYNOPSIS
-a:自动修复
-t FSTYPE:指定文件系统类型,可以不指,但一定不能指错
[root@soysauce ~]# fsck /dev/sdb1 # 我这里文件系统是clean状态,所以没有检查
fsck from util-linux-ng 2.17.2
e2fsck 1.41.12 (17-May-2010)
/dev/sdb1: clean, 11/131648 files, 25449/526120 blocks8、e2fsck
e2fsck - check a Linux ext2/ext3/ext4 file system # 检查并修复ext系列文件系统
SYNOPSIS
e2fsck [options] DEVICE
-f:强制检查
-p:自动修复
[root@soysauce ~]# e2fsck /dev/sdb1
e2fsck 1.41.12 (17-May-2010)
/dev/sdb1: clean, 11/131648 files, 25449/526120 blocks
[root@soysauce ~]# e2fsck -f /dev/sdb1 # 强制检查文件系统
e2fsck 1.41.12 (17-May-2010)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/sdb1: 11/131648 files (0.0% non-contiguous), 25449/526120 blocks9、mount
mount - mount a filesystem # 挂载文件系统
SYNOPSIS
mount [options] [-o options] DEVICE MOUNT_POINT
-a:表示挂载/etc/fstab文件中定义的所有文件系统
-n:默认情况下,mount命令每挂载一个设备,都会把挂载的设备信息保存至/etc/mtab文件;使用—n选项意味着挂载设备时,不把信息写入此文件
-t FSTYPE:指定正在挂载设备上的文件系统的类型;不使用此选项时,mount会调用blkid命令获取对应文件系统的类型
-r:只读挂载,挂载光盘时常用此选项
-w:读写挂载
-o:指定额外的挂载选项,也即指定文件系统启用的属性;
remount:重新挂载当前文件系统
ro:挂载为只读
rw:读写挂载
loop:挂载本地回环设备
挂载:将新的文件系统关联至当前根文件系统
卸载:将某文件系统与当前根文件系统的关联关系预以移除
[root@soysauce ~]# mount # 不带任何参数的mount命令可以显示当前已挂载的文件系统
/dev/mapper/vg_centos6-lv_root on / type ext4 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
tmpfs on /dev/shm type tmpfs (rw)
/dev/sda1 on /boot type ext4 (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
[root@soysauce ~]# mount -o ro /dev/sdb1 /mnt/ # 以只读方式挂载
[root@soysauce ~]# echo "hello" >> /mnt/a.txt
-bash: /mnt/a.txt: Read-only file system # 不能写文件
[root@soysauce ~]# mount -o remount,rw /mnt/ # 以可读写方式重新挂载
[root@soysauce ~]# echo "hello" >> /mnt/a.txt
[root@soysauce ~]# cd /mnt/
[root@soysauce mnt]# ls
a.txt lost+found
[root@soysauce mnt]# cat a.txt # 写入成功
hello
[root@soysauce ~]# cat /etc/fstab
LABEL=/ / ext3 defaults,barrier=0 1 1
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
要挂载的设备 挂载点 文件系统类型 挂载选项 转储频率(每多少天做一次完全备份) 文件系统检测次序(只有根可以为1)10、fuser
fuser - identify processes using files or sockets # 报告进程使用的文件或是网络套接字
SYNOPSIS
fuser [options] DEVICE
-v:查看某文件上正在运行的进程
-k:杀死正在访问某文件的进程
-m:显示访问挂载点的进程
[root@soysauce ~]# mount /dev/sdb1 /mnt/ # 挂载/dev/sdb1至/mnt目录下
[root@soysauce ~]# cd /mnt/ # 切换进/mnt目录
[root@soysauce mnt]# umount /mnt/ # 此时我就站在/mnt目录下,卸载肯定卸不掉
umount: /mnt: device is busy.
(In some cases useful info about processes that use
the device is found by lsof(8) or fuser(1))
[root@soysauce mnt]# fuser -km /mnt/ # 强行结束正在访问/mnt挂载点的进程,然后直接把我踢下线了...
/mnt/: 1860c
Connection closed by foreign host.
Disconnected from remote host(CentOS6.5) at 22:20:33.
Type `help' to learn how to use Xshell prompt. 11、free
free - Display amount of free and used memory in the system # 显示系统中已用的和未用的内存总和
SYNOPSIS
free [-b | -k | -m] [-o] [-s delay ] [-t] [-l] [-V]
-m:以M为单位来显示
[root@soysauce ~]# free -m
total used free shared buffers cached
Mem: 988 176 812 0 67 37
-/+ buffers/cache: 71 917
Swap: 1983 0 1983
第一行:内存总大小、已使用空间大小、剩余空间大小、共享内存、缓冲数据大小、缓存数据大小
第二行:UsedMem-(buffers+cached)为真实使用空间、FreeMem+(buffers+cached)为真实剩余空间
第三行:总交换分区大小、已使用交换分区大小、剩余交换分区大小12、du
du - estimate file space usage # 报告磁盘空间使用情况
SYNOPSIS
du [OPTION]... [FILE]...
du [OPTION]... --files0-from=F
-s:仅显示总计,只列出最后加总的值
-h:做单位换算的
[root@soysauce ~]# du -sh /root/ # 统计总大小
1.3M /root/
[root@soysauce ~]# du -h /root/ # 统计目录下每单个文件大小
4.0K /root/.pki/nssdb
8.0K /root/.pki
4.0K /root/.ansible/cp
8.0K /root/.ansible
8.0K /root/test
36K /root/.vim/syntax
48K /root/.vim
20K /root/.ssh
136K /root/scripts
1.3M /root/13、df
df - report file system disk space usage # 报告文件系统磁盘空间的使用情况
SYNOPSIS
df [OPTION]... [FILE]...
-a:查看所有的文件系统
-h:做单位换算
-i:显示inode使用情况
-P:以POSIX风格显示
-T:显示文件系统类型
[root@soysauce ~]# df -ihT # 显示Inode使用情况
Filesystem Type Inodes IUsed IFree IUse% Mounted on
/dev/mapper/vg_centos6-lv_root ext4 1.1M 40K 1.1M 4% /
tmpfs tmpfs 124K 1 124K 1% /dev/shm
/dev/sda1 ext4 126K 38 125K 1% /boot
/dev/sdb1 ext3 129K 12 129K 1% /mnt
[root@soysauce ~]# df -hT # 显示磁盘空间使用情况
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/vg_centos6-lv_root ext4 18G 2.3G 15G 14% /
tmpfs tmpfs 495M 0 495M 0% /dev/shm
/dev/sda1 ext4 485M 33M 427M 8% /boot
/dev/sdb1 ext3 2.0G 68M 1.8G 4% /mnt14、dd
dd - convert and copy a file # 复制文件并对原文件进行转化和格式化处理
SYNOPSIS
dd [OPERAND]...
dd OPTION
if=数据来源
of=数据存储目录
bs=#:指定块大小,单位默认为字节,也可以指定M、G等
count=#:指定读取的块数
seek=#:创建数据文件时,跳过的空间大小
[root@soysauce ~]# dd if=/dev/sda of=/root/mbr.back bs=512 count=1 # 备份mbr
1+0 records in
1+0 records out
512 bytes (512 B) copied, 0.000675345 s, 758 kB/s
[root@soysauce ~]# dd if=/dev/zero of=/root/zerofile bs=1M count=1 seek=1023 # 跳过前面1023M,创建一个假的1G文件
1+0 records in
1+0 records out
1048576 bytes (1.0 MB) copied, 0.00649022 s, 162 MB/s
[root@soysauce ~]# ll -h /root/zerofile # ls看到的是假的1G
-rw-r--r-- 1 root root 1.0G Nov 24 11:07 /root/zerofile
[root@soysauce ~]# du -sh /root/zerofile # du看到的是真实的大小,为1M
1.0M /root/zerofile15、mknod
mknod - make block or character special files # 创建块设备文件或字符设备文件
SYNOPSIS
mknod [OPTION]... NAME TYPE [MAJOR MINOR]
-m:设置权限
-Z:设置安全的上下文
[root@soysauce ~]# mknod /dev/mydev b 65 0 # 创建一个主设备号为65 次设备号为0的块设备文件
[root@soysauce ~]# ll /dev/mydev
brw-r--r-- 1 root root 65, 0 Nov 24 11:34 /dev/mydev
[root@soysauce ~]# mknod -m 600 /dev/mysdev b 65 1 # -m指定权限为600
[root@soysauce ~]# ll /dev/mysdev
brw------- 1 root root 65, 1 Nov 24 11:36 /dev/mysdev关于文件系统的就讲这么多,下篇会讲解linux内核提供的一个资源管控机制cgroup,分析其原理及使用过程。
ext4文件系统bug:
http://www.phoronix.com/scan.php?page=news_item&px=MTIxNDQ
ext4文件系统描述:
http://blog.csdn.net/liangchen0322/article/details/50365685
http://blog.csdn.net/fybon/article/details/26243971
hexdump查看磁盘结构信息:
http://www.cnblogs.com/jiangcsu/p/5737659.html