Python爬取大量数据时防止被封IP
From:http://blog.51cto.com/7200087/2070320
基于scrapy框架的爬虫代理IP设置:https://www.jianshu.com/p/074c36a7948c
Scrapy: 针对特定响应状态码,使用代理重新请求:http://www.cnblogs.com/my8100/p/scrapy_middleware_autoproxy.html
Python爬虫技巧---设置代理IP:https://blog.csdn.net/lammonpeter/article/details/52917264
国内髙匿代理IP网站:http://www.xicidaili.com/nn/
Scrapy配置代理:https://www.jianshu.com/p/b21f94b8591c
Python网络爬虫--Scrapy使用IP代理池:https://www.jianshu.com/p/da94a2a24de8
scrapy设置代理池:https://blog.csdn.net/weixin_40475396/article/details/78241238
scrapy绕过反爬虫:https://www.imooc.com/article/35588
Scrapy学习笔记(7)-定制动态可配置爬虫:http://jinbitou.net/2016/12/05/2244.html
Python scrapy.http.HtmlResponse():https://www.programcreek.com/python/example/71413/scrapy.http.HtmlResponse
scrapy之随机设置请求头和ip代理池中间件:https://www.jianshu.com/p/ca1afe40bba3
在scrapy中使用代理,有两种使用方式
- 使用中间件
- 直接设置Request类的meta参数
方式一:使用中间件
要进行下面两步操作
- 在文件 settings.py 中激活代理中间件
ProxyMiddleware - 在文件 middlewares.py 中实现类
ProxyMiddleware
1.文件 settings.py 中:
# settings.py
DOWNLOADER_MIDDLEWARES = {
'project_name.middlewares.ProxyMiddleware': 100, # 注意修改 project_name
'scrapy.downloadermiddleware.httpproxy.HttpProxyMiddleware': 110,
}说明:
数字100, 110表示中间件先被调用的次序。数字越小,越先被调用。
官网文档:
The integer values you assign to classes in this setting determine the order in which they run: items go through from lower valued to higher valued classes. It’s customary to define these numbers in the 0-1000 range.
2.文件 middlewares.py 看起来像这样:
代理不断变换
- 这里利用网上API 直接get过来。(需要一个APIKEY,免费注册一个账号就有了。这个APIKEY是我自己的,不保证一直有效!)
- 也可以从网上现抓。
- 还可以从本地文件读取
# middlewares.py
import requests
class ProxyMiddleware(object):
def process_request(self, request, spider):
APIKEY = 'f95f08afc952c034cc2ff9c5548d51be'
url = 'https://www.proxicity.io/api/v1/{}/proxy'.format(APIKEY) # 在线API接口
r = requests.get(url)
request.meta['proxy'] = r.json()['curl'] # 协议://IP地址:端口(如 http://5.39.85.100:30059)
return request方式二:直接设置Request类的meta参数
import random
# 事先准备的代理池
proxy_pool = ['http://proxy_ip1:port', 'http://proxy_ip2:port', ..., 'http://proxy_ipn:port']
class MySpider(BaseSpider):
name = "my_spider"
allowed_domains = ["example.com"]
start_urls = [
'http://www.example.com/articals/',
]
def start_requests(self):
for url in self.start_urls:
proxy_addr = random.choice(proxy_pool) # 随机选一个
yield scrapy.Request(url, callback=self.parse, meta={'proxy': proxy_addr}) # 通过meta参数添加代理
def parse(self, response):
# doing parse
延伸阅读
1.阅读官网文档对Request类的描述,我们可以发现除了设置proxy,还可以设置method, headers, cookies, encoding等等:
class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback])
2.官网文档对Request.meta参数可以设置的详细列表:
- dont_redirect
- dont_retry
- handle_httpstatus_list
- handle_httpstatus_all
- dont_merge_cookies (see cookies parameter of Request constructor)
- cookiejar
- dont_cache
- redirect_urls
- bindaddress
- dont_obey_robotstxt
- download_timeout
- download_maxsize
- proxy
如随机设置请求头和代理:
# my_spider.py
import random
# 事先收集准备的代理池
proxy_pool = [
'http://proxy_ip1:port',
'http://proxy_ip2:port',
...,
'http://proxy_ipn:port'
]
# 事先收集准备的 headers
headers_pool = [
{'User-Agent': 'Mozzila 1.0'},
{'User-Agent': 'Mozzila 2.0'},
{'User-Agent': 'Mozzila 3.0'},
{'User-Agent': 'Mozzila 4.0'},
{'User-Agent': 'Chrome 1.0'},
{'User-Agent': 'Chrome 2.0'},
{'User-Agent': 'Chrome 3.0'},
{'User-Agent': 'Chrome 4.0'},
{'User-Agent': 'IE 1.0'},
{'User-Agent': 'IE 2.0'},
{'User-Agent': 'IE 3.0'},
{'User-Agent': 'IE 4.0'},
]
class MySpider(BaseSpider):
name = "my_spider"
allowed_domains = ["example.com"]
start_urls = [
'http://www.example.com/articals/',
]
def start_requests(self):
for url in self.start_urls:
headers = random.choice(headers_pool) # 随机选一个headers
proxy_addr = random.choice(proxy_pool) # 随机选一个代理
yield scrapy.Request(url, callback=self.parse, headers=headers, meta={'proxy': proxy_addr})
def parse(self, response):
# doing parse
记录一个比较完整的通过ip池进行爬虫被禁的处理
scrapy接入IP代理池(代码部分):https://blog.csdn.net/xudailong_blog/article/details/80153387
class HttpProxymiddleware(object):
# 一些异常情况汇总
EXCEPTIONS_TO_CHANGE = (
defer.TimeoutError, TimeoutError, ConnectionRefusedError, ConnectError, ConnectionLost,
TCPTimedOutError, ConnectionDone)
def __init__(self):
# 链接数据库 decode_responses设置取出的编码为str
self.redis = redis.from_url('redis://:你的密码@localhost:6379/0',decode_responses=True)
pass
def process_request(self, request, spider):
#拿出全部key,随机选取一个键值对
keys = self.rds.hkeys("xila_hash")
key = random.choice(keys)
#用eval函数转换为dict
proxy = eval(self.rds.hget("xila_hash",key))
logger.warning("-----------------"+str(proxy)+"试用中------------------------")
#将代理ip 和 key存入mate
request.meta["proxy"] = proxy["ip"]
request.meta["accountText"] = key
def process_response(self, request, response, spider):
http_status = response.status
#根据response的状态判断 ,200的话ip的times +1重新写入数据库,返回response到下一环节
if http_status == 200:
key = request.meta["accountText"]
proxy = eval(self.rds.hget("xila_hash",key))
proxy["times"] = proxy["times"] + 1
self.rds.hset("xila_hash",key,proxy)
return response
#403有可能是因为user-agent不可用引起,和代理ip无关,返回请求即可
elif http_status == 403:
logging.warning("#########################403重新请求中############################")
return request.replace(dont_filter=True)
#其他情况姑且被判定ip不可用,times小于10的,删掉,大于等于10的暂时保留
else:
ip = request.meta["proxy"]
key = request.meta["accountText"]
proxy = eval(self.rds.hget("xila_hash", key))
if proxy["times"] < 10:
self.rds.hdel("xila_hash",key)
logging.warning("#################" + ip + "不可用,已经删除########################")
return request.replace(dont_filter=True)
def process_exception(self, request, exception, spider):
#其他一些timeout之类异常判断后的处理,ip不可用删除即可
if isinstance(exception, self.EXCEPTIONS_TO_CHANGE) \
and request.meta.get('proxy', False):
key = request.meta["accountText"]
print("+++++++++++++++++++++++++{}不可用+++将被删除++++++++++++++++++++++++".format(key))
proxy = eval(self.rds.hget("xila_hash", key))
if proxy["times"] < 10:
self.rds.hdel("xila_hash", key)
logger.debug("Proxy {}链接出错{}.".format(request.meta['proxy'], exception))
return request.replace(dont_filter=True)
Scrapy 扩展中间件: 针对特定响应状态码,使用代理重新请求
0.参考
https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#module-scrapy.downloadermiddlewares.redirect
https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#module-scrapy.downloadermiddlewares.httpproxy
1.主要实现
实际爬虫过程中如果请求过于频繁,通常会被临时重定向到登录页面即302,甚至是提示禁止访问即403,因此可以对这些响应执行一次代理请求:
(1) 参考原生 redirect.py 模块,满足 dont_redirect 或 handle_httpstatus_list 等条件时,直接传递 response
(2) 不满足条件(1),如果响应状态码为 302 或 403,使用代理重新发起请求
(3) 使用代理后,如果响应状态码仍为 302 或 403,直接丢弃
2.代码实现
保存至 /site-packages/my_middlewares.py
from w3lib.url import safe_url_string
from six.moves.urllib.parse import urljoin
from scrapy.exceptions import IgnoreRequest
class MyAutoProxyDownloaderMiddleware(object):
def __init__(self, settings):
self.proxy_status = settings.get(‘PROXY_STATUS‘, [302, 403])
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html?highlight=proxy#module-scrapy.downloadermiddlewares.httpproxy
self.proxy_config = settings.get(‘PROXY_CONFIG‘, ‘http://username:password@some_proxy_server:port‘)
@classmethod
def from_crawler(cls, crawler):
return cls(
settings = crawler.settings
)
# See /site-packages/scrapy/downloadermiddlewares/redirect.py
def process_response(self, request, response, spider):
if (request.meta.get(‘dont_redirect‘, False) or
response.status in getattr(spider, ‘handle_httpstatus_list‘, []) or
response.status in request.meta.get(‘handle_httpstatus_list‘, []) or
request.meta.get(‘handle_httpstatus_all‘, False)):
return response
if response.status in self.proxy_status:
if ‘Location‘ in response.headers:
location = safe_url_string(response.headers[‘location‘])
redirected_url = urljoin(request.url, location)
else:
redirected_url = ‘‘
# AutoProxy for first time
if not request.meta.get(‘auto_proxy‘):
request.meta.update({‘auto_proxy‘: True, ‘proxy‘: self.proxy_config})
new_request = request.replace(meta=request.meta, dont_filter=True)
new_request.priority = request.priority + 2
spider.log(‘Will AutoProxy for <{} {}> {}‘.format(
response.status, request.url, redirected_url))
return new_request
# IgnoreRequest for second time
else:
spider.logger.warn(‘Ignoring response <{} {}>: HTTP status code still in {} after AutoProxy‘.format(
response.status, request.url, self.proxy_status))
raise IgnoreRequest
return response
3.调用方法
(1) 项目 settings.py 添加代码,注意必须在默认的 RedirectMiddleware 和 HttpProxyMiddleware 之间。
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# ‘scrapy.downloadermiddlewares.redirect.RedirectMiddleware‘: 600,
‘my_middlewares.MyAutoProxyDownloaderMiddleware‘: 601,
# ‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware‘: 750,
}
PROXY_STATUS = [302, 403]
PROXY_CONFIG = ‘http://username:password@some_proxy_server:port‘
4.运行结果
2018-07-18 18:42:35 [scrapy.core.engine] DEBUG: Crawled (200)
代理服务器 log:
squid [18/Jul/2018:18:42:53 +0800] "GET http://httpbin.org/status/302 HTTP/1.1" 302 310 "-" "Mozilla/5.0" TCP_MISS:HIER_DIRECT
squid [18/Jul/2018:18:42:54 +0800] "CONNECT httpbin.org:443 HTTP/1.1" 200 3560 "-" "-" TCP_TUNNEL:HIER_DIRECT
Python爬虫技巧之设置代理IP
在学习Python爬虫的时候,经常会遇见所要爬取的网站采取了反爬取技术,高强度、高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封,这里讲述一个爬虫技巧,设置代理IP。
(一)配置环境
- 安装requests库
- 安装bs4库
- 安装lxml库
(二)代码展示
IP地址取自国内髙匿代理IP网站:http://www.xicidaili.com/nn/
仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text, 'lxml')
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
if __name__ == '__main__':
url = 'http://www.xicidaili.com/nn/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
ip_list = get_ip_list(url, headers=headers)
proxies = get_random_ip(ip_list)
print(proxies)- 数get_ip_list(url, headers)传入url和headers,最后返回一个IP列表,列表的元素类似42.84.226.65:8888格式,这个列表包括国内髙匿代理IP网站首页所有IP地址和端口。
- 函数get_random_ip(ip_list)传入第一个函数得到的列表,返回一个随机的proxies,这个proxies可以传入到requests的get方法中,这样就可以做到每次运行都使用不同的IP访问被爬取的网站,有效地避免了真实IP被封的风险。proxies的格式是一个字典:{‘http’: ‘http://42.84.226.65:8888‘}。
(三)代理IP的使用
运行上面的代码会得到一个随机的proxies,把它直接传入requests的get方法中即可。
web_data = requests.get(url, headers=headers, proxies=proxies)
爬取猪八戒网信息
继续老套路,这两天我爬取了猪八戒上的一些数据 网址是:http://task.zbj.com/t-ppsj/p1s5.html,可能是由于爬取的数据量有点多吧,结果我的IP被封了,需要自己手动来验证解封ip,但这显然阻止了我爬取更多的数据了。
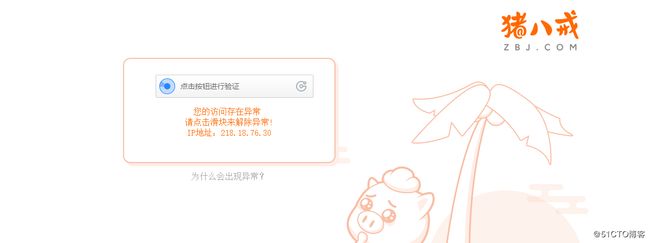
下面是我写的爬取猪八戒的被封IP的代码
# coding=utf-8
import requests
from lxml import etree
def getUrl():
for i in range(33):
url = 'http://task.zbj.com/t-ppsj/p{}s5.html'.format(i+1)
spiderPage(url)
def spiderPage(url):
if url is None:
return None
htmlText = requests.get(url).text
selector = etree.HTML(htmlText)
tds = selector.xpath('//*[@class="tab-switch tab-progress"]/table/tr')
try:
for td in tds:
price = td.xpath('./td/p/em/text()')
href = td.xpath('./td/p/a/@href')
title = td.xpath('./td/p/a/text()')
subTitle = td.xpath('./td/p/text()')
deadline = td.xpath('./td/span/text()')
price = price[0] if len(price)>0 else '' # python的三目运算 :为真时的结果 if 判定条件 else 为假时的结果
title = title[0] if len(title)>0 else ''
href = href[0] if len(href)>0 else ''
subTitle = subTitle[0] if len(subTitle)>0 else ''
deadline = deadline[0] if len(deadline)>0 else ''
print price,title,href,subTitle,deadline
print '---------------------------------------------------------------------------------------'
spiderDetail(href)
except:
print '出错'
def spiderDetail(url):
if url is None:
return None
try:
htmlText = requests.get(url).text
selector = etree.HTML(htmlText)
aboutHref = selector.xpath('//*[@id="utopia_widget_10"]/div[1]/div/div/div/p[1]/a/@href')
price = selector.xpath('//*[@id="utopia_widget_10"]/div[1]/div/div/div/p[1]/text()')
title = selector.xpath('//*[@id="utopia_widget_10"]/div[1]/div/div/h2/text()')
contentDetail = selector.xpath('//*[@id="utopia_widget_10"]/div[2]/div/div[1]/div[1]/text()')
publishDate = selector.xpath('//*[@id="utopia_widget_10"]/div[2]/div/div[1]/p/text()')
aboutHref = aboutHref[0] if len(aboutHref) > 0 else '' # python的三目运算 :为真时的结果 if 判定条件 else 为假时的结果
price = price[0] if len(price) > 0 else ''
title = title[0] if len(title) > 0 else ''
contentDetail = contentDetail[0] if len(contentDetail) > 0 else ''
publishDate = publishDate[0] if len(publishDate) > 0 else ''
print aboutHref,price,title,contentDetail,publishDate
except:
print '出错'
if '_main_':
getUrl()
我发现代码运行完后,后面有几页数据没有被爬取,我再也没有办法去访问猪八戒网站了,等过了一段时间才能去访问他们的网站,这就很尴尬了,我得防止被封IP
如何防止爬取数据的时候被网站封IP这里有一些套路.查了一些套路
1.修改请求头
之前的爬虫代码没有添加头部,这里我添加了头部,模拟成浏览器去访问网站
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4295.400'
headers = {'User-Agent': user_agent}
htmlText = requests.get(url, headers=headers, proxies=proxies).text
2.采用代理IP
当自己的ip被网站封了之后,只能采用代理ip的方式进行爬取,所以每次爬取的时候尽量用代理ip来爬取,封了代理还有代理。
这里我引用了这个博客的一段代码来生成ip地址:http://blog.csdn.net/lammonpeter/article/details/52917264
生成代理ip,大家可以直接把这个代码拿去用
# coding=utf-8
# IP地址取自国内髙匿代理IP网站:http://www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text, 'lxml')
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
if __name__ == '__main__':
url = 'http://www.xicidaili.com/nn/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
ip_list = get_ip_list(url, headers=headers)
proxies = get_random_ip(ip_list)
print(proxies)
好了我用上面的代码给我生成了一批ip地址(有些ip地址可能无效,但只要不封我自己的ip就可以了,哈哈),然后我就可以在我的请求头部添加ip地址
给我们的请求添加代理ip
proxies = {
'http': 'http://124.72.109.183:8118',
'http': 'http://49.85.1.79:31666'
}
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4295.400'
headers = {'User-Agent': user_agent}
htmlText = requests.get(url, headers=headers, timeout=3, proxies=proxies).text
目前知道的就
最后完整代码如下:
# coding=utf-8
import requests
import time
from lxml import etree
def getUrl():
for i in range(33):
url = 'http://task.zbj.com/t-ppsj/p{}s5.html'.format(i+1)
spiderPage(url)
def spiderPage(url):
if url is None:
return None
try:
proxies = {
'http': 'http://221.202.248.52:80',
}
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4295.400'
headers = {'User-Agent': user_agent}
htmlText = requests.get(url, headers=headers,proxies=proxies).text
selector = etree.HTML(htmlText)
tds = selector.xpath('//*[@class="tab-switch tab-progress"]/table/tr')
for td in tds:
price = td.xpath('./td/p/em/text()')
href = td.xpath('./td/p/a/@href')
title = td.xpath('./td/p/a/text()')
subTitle = td.xpath('./td/p/text()')
deadline = td.xpath('./td/span/text()')
price = price[0] if len(price)>0 else '' # python的三目运算 :为真时的结果 if 判定条件 else 为假时的结果
title = title[0] if len(title)>0 else ''
href = href[0] if len(href)>0 else ''
subTitle = subTitle[0] if len(subTitle)>0 else ''
deadline = deadline[0] if len(deadline)>0 else ''
print price,title,href,subTitle,deadline
print '---------------------------------------------------------------------------------------'
spiderDetail(href)
except Exception,e:
print '出错',e.message
def spiderDetail(url):
if url is None:
return None
try:
htmlText = requests.get(url).text
selector = etree.HTML(htmlText)
aboutHref = selector.xpath('//*[@id="utopia_widget_10"]/div[1]/div/div/div/p[1]/a/@href')
price = selector.xpath('//*[@id="utopia_widget_10"]/div[1]/div/div/div/p[1]/text()')
title = selector.xpath('//*[@id="utopia_widget_10"]/div[1]/div/div/h2/text()')
contentDetail = selector.xpath('//*[@id="utopia_widget_10"]/div[2]/div/div[1]/div[1]/text()')
publishDate = selector.xpath('//*[@id="utopia_widget_10"]/div[2]/div/div[1]/p/text()')
aboutHref = aboutHref[0] if len(aboutHref) > 0 else '' # python的三目运算 :为真时的结果 if 判定条件 else 为假时的结果
price = price[0] if len(price) > 0 else ''
title = title[0] if len(title) > 0 else ''
contentDetail = contentDetail[0] if len(contentDetail) > 0 else ''
publishDate = publishDate[0] if len(publishDate) > 0 else ''
print aboutHref,price,title,contentDetail,publishDate
except:
print '出错'
if '_main_':
getUrl()
最后程序完美运行,再也没有出现被封IP的情况。当然防止被封IP肯定不止这些了,这还需要进一步探索!
最后
当然数据我是已经抓取过来了,但是我的数据都没有完美呈现出来,我应该写入execl文件,或者数据库中啊,这样才能方便采用.所以接下来我准备了使用
Python操作execl,mysql,mongoDB