KinectFusion 中的 ICP 算法 GPU 代码解读
简介
本篇博客介绍 KinectFusion 中的 ICP 算法的代码,代码实现是 PCL 工程 pcl_gpu_kinfu_large_scale 工程中的文件 estimate_combined.cu。
ICP 算法实现用 GPU 做并行计算可以极大的提高运算效率。
GPU 极小化 ICP 算法中的目标函数
KinectFusion 中 ICP 采用极小化点到平面的距离,计算两帧之间的位姿变换,ICP 算法理论介绍见博客:
http://blog.csdn.net/fuxingyin/article/details/51425721
ICP 算法通过求解 Cx=b 计算两帧之间的位姿变换,其中 C 和 b 的表达式为:
C=∑i=1k(pi×nin1)((pi×ni)⊤n⊤i).
b=∑i=1k((pi×ni)τ, ni)τ⋅((pi−qi)τ⋅ni)
其中 pi 是 current 点云, qi 是 previous 点云, ni 是 previous 点云法向量, pi 和 qi 是匹配点,极小化目标函数前寻找匹配点的操作也在 GPU 中进行。
上式中对于每个点的累加操作采用 GPU 做并行计算。
代码结构
GPU 和 CPU 接口:
// Rcurr 和 tcurr 是估计的当前帧的位姿
// vmap_curr 和 nmap_curr 由当前帧的深度图像计算得到的点云
// Rprev_inv 和 tprev 上一帧相机的位姿 Intr 深度相机内参
// vmap_g_prev 和 nmap_g_prev 上一帧通过光线投影计算得到的点坐标和法向量
// distThres 和 angleThres 投影算法计算匹配点时的阈值
// gbuf 和 mbuf GPU 中开辟的显存,存储累积和
// matrixA_host 和 vectorB_host GPU 累加之后最终的输出
void
estimateCombined (const Mat33& Rcurr, const float3& tcurr,
const MapArr& vmap_curr, const MapArr& nmap_curr,
const Mat33& Rprev_inv, const float3& tprev, const Intr& intr,
const MapArr& vmap_g_prev, const MapArr& nmap_g_prev,
float distThres, float angleThres,
DeviceArray2D& gbuf, DeviceArray& mbuf,
float_type* matrixA_host, float_type* vectorB_host)
{ 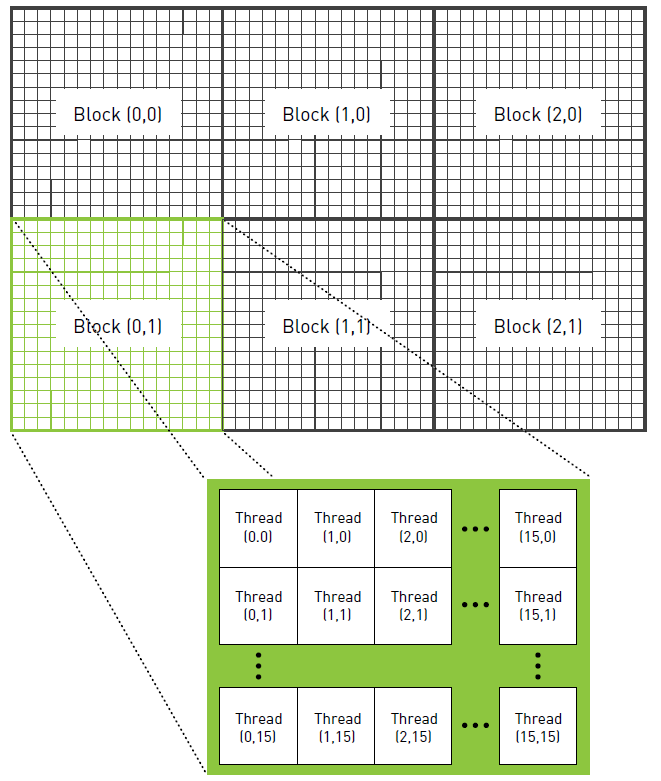
GPU 并行计算分配核心分配
如上图 GPU 线程的框架结构,可以把 GPU 分成 grid.x 乘以 grid.y 个 block, 每个 block 中有 block.x 乘以 block.y 个线程,每个线程的计算独立。
// 采用 grid.x 乘以 grid.y 个 block,
// 每个 block 中有 block.x 乘以 block.y 个线程,
dim3 block (Combined::CTA_SIZE_X, Combined::CTA_SIZE_Y);
dim3 grid (1, 1, 1);
// rows 和 cols 分别是图像行和列的维度
grid.x = divUp (cols, block.x);
grid.y = divUp (rows, block.y);
// 上述操作刚好分配了 rows 乘以 cols 个线程,每个线程处理图像中的单个像素点,
combinedKernel<<>>(cs); // 第一次在 GPU 中做累加,每个 block 的累加结果存储到 gbuf 对应的显存位置
mbuf.create (TranformReduction::TOTAL);
if (gbuf.rows () != TranformReduction::TOTAL || gbuf.cols () < (int)(grid.x * grid.y))
gbuf.create (TranformReduction::TOTAL, grid.x * grid.y);
cs.gbuf = gbuf;
combinedKernel<<>>(cs);
cudaSafeCall ( cudaGetLastError () );
cudaSafeCall(cudaDeviceSynchronize()); // 第一次做累加实现
struct Combined
{
enum
{
CTA_SIZE_X = ESTIMATE_COMBINED_CUDA_GRID_X,
CTA_SIZE_Y = ESTIMATE_COMBINED_CUDA_GRID_Y,
CTA_SIZE = CTA_SIZE_X * CTA_SIZE_Y
};
Mat33 Rcurr;
float3 tcurr;
PtrStep<float> vmap_curr;
PtrStep<float> nmap_curr;
Mat33 Rprev_inv;
float3 tprev;
Intr intr;
PtrStep<float> vmap_g_prev;
PtrStep<float> nmap_g_prev;
float distThres;
float angleThres;
int cols;
int rows;
mutable PtrStep gbuf;
__device__ __forceinline__ bool
search (int x, int y, float3& n, float3& d, float3& s) const
{
float3 ncurr;
ncurr.x = nmap_curr.ptr (y)[x];
if (isnan (ncurr.x))
return (false);
float3 vcurr;
vcurr.x = vmap_curr.ptr (y )[x];
vcurr.y = vmap_curr.ptr (y + rows)[x];
vcurr.z = vmap_curr.ptr (y + 2 * rows)[x];
float3 vcurr_g = Rcurr * vcurr + tcurr;
float3 vcurr_cp = Rprev_inv * (vcurr_g - tprev); // prev camera coo space
int2 ukr; //projection
ukr.x = __float2int_rn (vcurr_cp.x * intr.fx / vcurr_cp.z + intr.cx); //4
ukr.y = __float2int_rn (vcurr_cp.y * intr.fy / vcurr_cp.z + intr.cy); //4
if (ukr.x < 0 || ukr.y < 0 || ukr.x >= cols || ukr.y >= rows || vcurr_cp.z < 0)
return (false);
float3 nprev_g;
nprev_g.x = nmap_g_prev.ptr (ukr.y)[ukr.x];
if (isnan (nprev_g.x))
return (false);
float3 vprev_g;
vprev_g.x = vmap_g_prev.ptr (ukr.y )[ukr.x];
vprev_g.y = vmap_g_prev.ptr (ukr.y + rows)[ukr.x];
vprev_g.z = vmap_g_prev.ptr (ukr.y + 2 * rows)[ukr.x];
float dist = norm (vprev_g - vcurr_g);
if (dist > distThres)
return (false);
ncurr.y = nmap_curr.ptr (y + rows)[x];
ncurr.z = nmap_curr.ptr (y + 2 * rows)[x];
float3 ncurr_g = Rcurr * ncurr;
nprev_g.y = nmap_g_prev.ptr (ukr.y + rows)[ukr.x];
nprev_g.z = nmap_g_prev.ptr (ukr.y + 2 * rows)[ukr.x];
float sine = norm (cross (ncurr_g, nprev_g));
if (sine >= angleThres)
return (false);
n = nprev_g;
d = vprev_g;
s = vcurr_g;
return (true);
}
__device__ __forceinline__ void
operator () () const
{
// 计算线程对应的像素坐标,每个线程处理单个像素坐标
int x = threadIdx.x + blockIdx.x * CTA_SIZE_X;
int y = threadIdx.y + blockIdx.y * CTA_SIZE_Y;
float3 n, d, s;
bool found_coresp = false;
// 用投影算法寻找匹配点
if (x < cols && y < rows)
found_coresp = search (x, y, n, d, s);
float row[7];
//如果找到匹配点构建矩阵 A 和 b
if (found_coresp)
{
*(float3*)&row[0] = cross (s, n);
*(float3*)&row[3] = n;
row[6] = dot (n, d - s);
}
else
row[0] = row[1] = row[2] = row[3] = row[4] = row[5] = row[6] = 0.f;
__shared__ float_type smem[CTA_SIZE];
int tid = Block::flattenedThreadId ();
int shift = 0;
for (int i = 0; i < 6; ++i) //rows
{
#pragma unroll
for (int j = i; j < 7; ++j) // cols + b
{
// 线程同步,只有全部的线程都执行到这一步,才能执行后续操作
__syncthreads ();
smem[tid] = row[i] * row[j];
__syncthreads ();
// 将单个 block 中的数据做累加
reduce(smem);
// 如果是 block 中的第一个线程,则将单个 block 中的累加和存到显存中
if (tid == 0)
gbuf.ptr (shift++)[blockIdx.x + gridDim.x * blockIdx.y] = smem[0];
}
}
}
};
// GPU 和 CPU 接口
__global__ void
combinedKernel (const Combined cs)
{
cs (); // 调用函数 operator () () const
} // 第二次做累加,将每个 block 的输出累加
TranformReduction tr;
tr.gbuf = gbuf;
tr.length = grid.x * grid.y;
tr.output = mbuf;
// 第二次做累加,采用 A 和 b 中元素个数和作为 block 的个数
// 每个 block 处理单个元素,每个 block 的线程个数为 512
TransformEstimatorKernel2<<>>(tr);
cudaSafeCall (cudaGetLastError ());
cudaSafeCall (cudaDeviceSynchronize ());
// 将累加结果从 GPU 显存转移到 CPU 内存
float_type host_data[TranformReduction::TOTAL];
mbuf.download (host_data);
// 构建矩阵 A 和 b
int shift = 0;
for (int i = 0; i < 6; ++i) //rows
for (int j = i; j < 7; ++j) // cols + b
{
float_type value = host_data[shift++];
if (j == 6) // vector b
vectorB_host[i] = value;
else
matrixA_host[j * 6 + i] = matrixA_host[i * 6 + j] = value;
}
} // 第二次做累加实现
struct TranformReduction
{
enum
{
CTA_SIZE = 512,
STRIDE = CTA_SIZE,
B = 6, COLS = 6, ROWS = 6, DIAG = 6,
UPPER_DIAG_MAT = (COLS * ROWS - DIAG) / 2 + DIAG,
TOTAL = UPPER_DIAG_MAT + B,
GRID_X = TOTAL
};
PtrStep gbuf;
int length;
mutable float_type* output;
__device__ __forceinline__ void
operator () () const
{
const float_type *beg = gbuf.ptr (blockIdx.x);
const float_type *end = beg + length;
int tid = threadIdx.x;
float_type sum = 0.f;
// 每个线程对 A 或者 b 中的单个元素做累积
for (const float_type *t = beg + tid; t < end; t += STRIDE)
sum += *t;
// 每个 block 中有 CTA_SIZE 个线程
__shared__ float_type smem[CTA_SIZE];
smem[tid] = sum;
__syncthreads ();
// 将每个 block 中的单个元素的值求和
reduce(smem);
// 当在 block 中线程编号为 0 时将累加结果输出
if (tid == 0)
output[blockIdx.x] = smem[0];
}
};
__global__ void
TransformEstimatorKernel2 (const TranformReduction tr)
{
tr ();
} // 单个 block 中的元素做累加
template
static __device__ __forceinline__ void reduce(volatile T* buffer)
{
int tid = Block::flattenedThreadId();
T val = buffer[tid];
if (CTA_SIZE_ >= 1024) { if (tid < 512) buffer[tid] = val = val + buffer[tid + 512]; __syncthreads(); }
if (CTA_SIZE_ >= 512) { if (tid < 256) buffer[tid] = val = val + buffer[tid + 256]; __syncthreads(); }
if (CTA_SIZE_ >= 256) { if (tid < 128) buffer[tid] = val = val + buffer[tid + 128]; __syncthreads(); }
if (CTA_SIZE_ >= 128) { if (tid < 64) buffer[tid] = val = val + buffer[tid + 64]; __syncthreads(); }
// 因为 GPU 并行运算是以 warp 为单位的,每个 warp 中有 32 个线程,
//并且每个线程的操作是严格同步的,当线程个数小于 32 时,GPU 单个线程做累加时不需要再同步
if (tid < 32)
{
if (CTA_SIZE_ >= 64) { buffer[tid] = val = val + buffer[tid + 32]; }
if (CTA_SIZE_ >= 32) { buffer[tid] = val = val + buffer[tid + 16]; }
if (CTA_SIZE_ >= 16) { buffer[tid] = val = val + buffer[tid + 8]; }
if (CTA_SIZE_ >= 8) { buffer[tid] = val = val + buffer[tid + 4]; }
if (CTA_SIZE_ >= 4) { buffer[tid] = val = val + buffer[tid + 2]; }
if (CTA_SIZE_ >= 2) { buffer[tid] = val = val + buffer[tid + 1]; }
}
}