部署hadoop2.7.2 集群 基于zookeeper配置HDFS HA+Federation
注:本文基于官方文档以及其他资料,整合
hadoop1的核心组成是两部分,即HDFS和MapReduce。在hadoop2中变为HDFS和Yarn。新的HDFS中的NameNode不再是只有一个了,可以有多个(目前只支持2个)。每一个都有相同的职能。
两个NameNode
当集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode是处于待命状态的,时刻同步active状态NameNode的数据。一旦active状态的NameNode不能工作,通过手工或者自动切换,standby状态的NameNode就可以转变为active状态的,就可以继续工作了。这就是高可靠。
NameNode发生故障时
2个NameNode的数据其实是实时共享的。新HDFS采用了一种共享机制,JournalNode集群或者NFS进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这里使用JournalNode集群进行数据共享。
实现NameNode的自动切换
需要使用ZooKeeper集群进行选择了。HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。
HDFS Federation
NameNode是核心节点,维护着整个HDFS中的元数据信息,那么其容量是有限的,受制于服务器的内存空间。当NameNode服务器的内存装不下数据后,那么HDFS集群就装不下数据了,寿命也就到头了。因此其扩展性是受限的。HDFS联盟指的是有多个HDFS集群同时工作,那么其容量理论上就不受限了,夸张点说就是无限扩展。
节点分布

配置过程详述
配置文件一共包括6个,分别是hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml和slaves。除了hdfs-site.xml文件在不同集群配置不同外,其余文件在四个节点的配置是完全一样的,可以复制。
zookeeper配置这里略过,有一点要注意就是保证是每台机器的时间同步.
hadoop-env.sh
export HADOOP_PREFIX=/opt/ha/hadoop-2.7.2
export JAVA_HOME=/usr/local/java/jdk1.7.0_80
core-site.xml
默认的HDFS路径。当有多个HDFS集群同时工作时,用户如果不写集群名称,那么默认使用哪个哪就在这里指定!该值来自于hdfs-site.xml中的配置
默认是NameNode、DataNode、JournalNode等存放数据的公共目录
ZooKeeper集群的地址和端口。注意,数量一定是奇数
fs.defaultFS
hdfs://cluster1
hadoop.tmp.dir
/opt/ha/hadoop-2.7.2/data/tmp
io.file.buffer.size
131072
ha.zookeeper.quorum
hadoop:2181,hadoop1:2181,hadoop2:2181;slave1:2181;slave2:2181
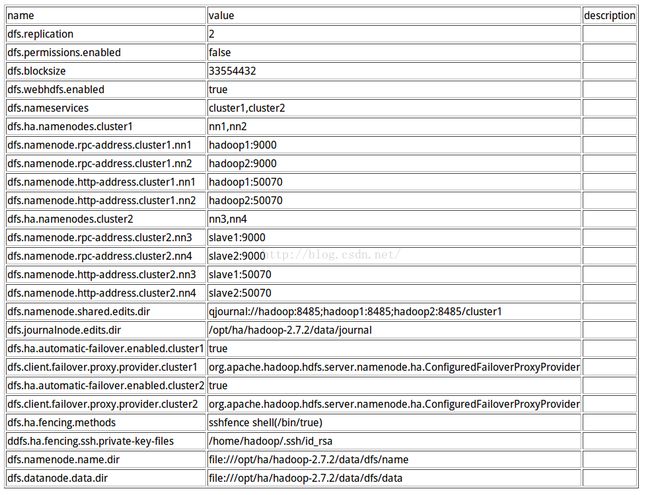
hdfs-site.xml
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
hadoop
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.job.tracker
hdfs://hadoop:9001
true
mapreduce.jobhistory.address
hadoop:10020
mapreduce.jobhistory.webapp.address
hadoop:19888
slaves
hadoop
hadoop1
hadoop2
slave1
slave2启动过程
在所有zk节点启动zookeeperhadoop@hadoop:hadoop-2.7.2$ zkServer.sh start
[hadoop@hadoop1 hadoop-2.7.2]$ bin/hdfs zkfc -formatZK
[hadoop@slave1 hadoop-2.7.2]$ bin/hdfs zkfc -formatZK
[hadoop@slave1 hadoop-2.7.2]$ zkCli.sh
[zk: localhost:2181(CONNECTED) 5] ls /hadoop-ha/cluster
cluster2 cluster1hadoop@hadoop:hadoop-2.7.2$ sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/ha/hadoop-2.7.2/logs/hadoop-hadoop-journalnode-hadoop.out
hadoop@hadoop:hadoop-2.7.2$
在cluster1中的nn1格式化namenode,验证并启动
[hadoop@hadoop1 hadoop-2.7.2]$ bin/hdfs namenode -format -clusterId hadoop1
16/05/19 15:43:01 INFO common.Storage: Storage directory /opt/ha/hadoop-2.7.2/data/dfs/name has been successfully formatted.
16/05/19 15:43:01 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
16/05/19 15:43:01 INFO util.ExitUtil: Exiting with status 0
16/05/19 15:43:01 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop1/192.168.2.10
************************************************************/
[hadoop@hadoop1 hadoop-2.7.2]$ ls data/dfs/name/current/
fsimage_0000000000000000000 seen_txid
fsimage_0000000000000000000.md5 VERSION
[hadoop@hadoop1 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/ha/hadoop-2.7.2/logs/hadoop-hadoop-namenode-hadoop1.out
[hadoop@hadoop1 hadoop-2.7.2]$ jps
9551 NameNode
9423 JournalNode
9627 Jps
9039 QuorumPeerMain
http://hadoop1:50070查看

cluster1中另一个节点同步数据格式化,并启动
[hadoop@hadoop2 hadoop-2.7.2]$ bin/hdfs namenode -bootstrapStandby
......
16/05/19 15:48:27 INFO common.Storage: Storage directory /opt/ha/hadoop-2.7.2/data/dfs/name has been successfully formatted.
16/05/19 15:48:27 INFO namenode.TransferFsImage: Opening connection to http://hadoop1:50070/imagetransfer?getimage=1&txid=0&storageInfo=-63:1280767544:0:hadoop1
16/05/19 15:48:28 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds
16/05/19 15:48:28 INFO namenode.TransferFsImage: Transfer took 0.00s at 0.00 KB/s
16/05/19 15:48:28 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 353 bytes.
16/05/19 15:48:28 INFO util.ExitUtil: Exiting with status 0
16/05/19 15:48:28 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop2/192.168.2.11
************************************************************/
[hadoop@hadoop2 hadoop-2.7.2]$ ls data/dfs/name/current/
fsimage_0000000000000000000 seen_txid
fsimage_0000000000000000000.md5 VERSION
[hadoop@hadoop2 hadoop-2.7.2]$
[hadoop@hadoop2 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/ha/hadoop-2.7.2/logs/hadoop-hadoop-namenode-hadoop2.out
[hadoop@hadoop2 hadoop-2.7.2]$ jps
7196 Jps
6980 JournalNode
7120 NameNode
6854 QuorumPeerMain
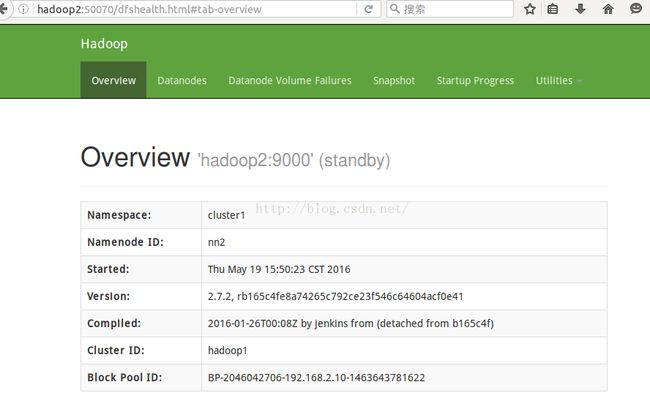
使用以上步骤同是启动cluster2的两个namenode;这里省略
然后启动所有的datanode和(必须也在hadoop节点上启动)yarn
[hadoop@hadoop1 hadoop-2.7.2]$ sbin/hadoop-daemons.sh start datanode
hadoop1: starting datanode, logging to /opt/ha/hadoop-2.7.2/logs/hadoop-hadoop-datanode-hadoop1.out
slave2: starting datanode, logging to /opt/ha/hadoop-2.7.2/logs/hadoop-hadoop-datanode-slave2.out
hadoop2: starting datanode, logging to /opt/ha/hadoop-2.7.2/logs/hadoop-hadoop-datanode-hadoop2.out
slave1: starting datanode, logging to /opt/ha/hadoop-2.7.2/logs/hadoop-hadoop-datanode-slave1.out
hadoop: starting datanode, logging to /opt/ha/hadoop-2.7.2/logs/hadoop-hadoop-datanode-hadoop.out
hadoop@hadoop:hadoop-2.7.2$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/ha/hadoop-2.7.2/logs/yarn-hadoop-resourcemanager-hadoop.out
hadoop2: starting nodemanager, logging to /opt/ha/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop2.out
hadoop1: starting nodemanager, logging to /opt/ha/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop1.out
slave2: starting nodemanager, logging to /opt/ha/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-slave2.out
hadoop: starting nodemanager, logging to /opt/ha/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop.out
slave1: starting nodemanager, logging to /opt/ha/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-slave1.out
hadoop@hadoop:hadoop-2.7.2$ jps
19384 JournalNode
19013 QuorumPeerMain
20649 Jps
20241 ResourceManager
20396 NodeManager
19815 DataNode
[hadoop@hadoop1 hadoop-2.7.2]$ jps
10091 NodeManager
9551 NameNode
9822 DataNode
9423 JournalNode
10232 Jps
9039 QuorumPeerMain
[hadoop@hadoop2 hadoop-2.7.2]$ jps
7450 NodeManager
7295 DataNode
6980 JournalNode
7120 NameNode
6854 QuorumPeerMain
7580 Jps
[hadoop@slave1 hadoop-2.7.2]$ jps
3706 DataNode
3988 Jps
3374 JournalNode
3591 NameNode
3860 NodeManager
3184 QuorumPeerMain
[hadoop@slave2 hadoop-2.7.2]$ jps
3023 QuorumPeerMain
3643 NodeManager
3782 Jps
3177 JournalNode
3497 DataNode
3383 NameNod

所有namenode节点启动zkfc
[hadoop@hadoop1 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start zkfc
starting zkfc, logging to /opt/ha/hadoop-2.7.2/logs/hadoop-hadoop-zkfc-hadoop1.out
[hadoop@hadoop1 hadoop-2.7.2]$ jps
10665 DFSZKFailoverController
9551 NameNode
9822 DataNode
9423 JournalNode
10739 Jps
9039 QuorumPeerMain
10483 NodeManager
上传文件测试
[hadoop@hadoop1 hadoop-2.7.2]$ bin/hdfs dfs -mkdir /test
16/05/19 16:09:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop1 hadoop-2.7.2]$ bin/hdfs dfs -put etc/hadoop/*.xml /test
16/05/19 16:09:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
#在slave1中查看
[hadoop@slave1 hadoop-2.7.2]$ bin/hdfs dfs -ls -R /
16/05/19 16:11:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
drwxr-xr-x - hadoop supergroup 0 2016-05-19 16:09 /test
-rw-r--r-- 2 hadoop supergroup 4436 2016-05-19 16:09 /test/capacity-scheduler.xml
-rw-r--r-- 2 hadoop supergroup 1185 2016-05-19 16:09 /test/core-site.xml
-rw-r--r-- 2 hadoop supergroup 9683 2016-05-19 16:09 /test/hadoop-policy.xml
-rw-r--r-- 2 hadoop supergroup 3814 2016-05-19 16:09 /test/hdfs-site.xml
-rw-r--r-- 2 hadoop supergroup 620 2016-05-19 16:09 /test/httpfs-site.xml
-rw-r--r-- 2 hadoop supergroup 3518 2016-05-19 16:09 /test/kms-acls.xml
-rw-r--r-- 2 hadoop supergroup 5511 2016-05-19 16:09 /test/kms-site.xml
-rw-r--r-- 2 hadoop supergroup 1170 2016-05-19 16:09 /test/mapred-site.xml
-rw-r--r-- 2 hadoop supergroup 1777 2016-05-19 16:09 /test/yarn-site.xml
[hadoop@slave1 hadoop-2.7.2]$
[hadoop@hadoop1 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /test /out
16/05/19 16:15:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/05/19 16:15:26 INFO client.RMProxy: Connecting to ResourceManager at hadoop/192.168.2.3:8032
16/05/19 16:15:27 INFO input.FileInputFormat: Total input paths to process : 9
16/05/19 16:15:27 INFO mapreduce.JobSubmitter: number of splits:9
16/05/19 16:15:27 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1463644924165_0001
16/05/19 16:15:27 INFO impl.YarnClientImpl: Submitted application application_1463644924165_0001
16/05/19 16:15:27 INFO mapreduce.Job: The url to track the job: http://hadoop:8088/proxy/application_1463644924165_0001/
16/05/19 16:15:27 INFO mapreduce.Job: Running job: job_1463644924165_0001
16/05/19 16:15:35 INFO mapreduce.Job: Job job_1463644924165_0001 running in uber mode : false
16/05/19 16:15:35 INFO mapreduce.Job: map 0% reduce 0%
16/05/19 16:15:44 INFO mapreduce.Job: map 11% reduce 0%
16/05/19 16:15:59 INFO mapreduce.Job: map 11% reduce 4%
16/05/19 16:16:08 INFO mapreduce.Job: map 22% reduce 4%
16/05/19 16:16:10 INFO mapreduce.Job: map 22% reduce 7%
16/05/19 16:16:22 INFO mapreduce.Job: map 56% reduce 7%
16/05/19 16:16:26 INFO mapreduce.Job: map 100% reduce 67%
16/05/19 16:16:29 INFO mapreduce.Job: map 100% reduce 100%
16/05/19 16:16:29 INFO mapreduce.Job: Job job_1463644924165_0001 completed successfully
16/05/19 16:16:31 INFO mapreduce.Job: Counters: 51
File System Counters
FILE: Number of bytes read=25164
FILE: Number of bytes written=1258111
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=32620
HDFS: Number of bytes written=13523
HDFS: Number of read operations=30
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Killed map tasks=2
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=8
Rack-local map tasks=2
Total time spent by all maps in occupied slots (ms)=381816
Total time spent by all reduces in occupied slots (ms)=42021
Total time spent by all map tasks (ms)=381816
Total time spent by all reduce tasks (ms)=42021
Total vcore-milliseconds taken by all map tasks=381816
Total vcore-milliseconds taken by all reduce tasks=42021
Total megabyte-milliseconds taken by all map tasks=390979584
Total megabyte-milliseconds taken by all reduce tasks=43029504
Map-Reduce Framework
Map input records=963
Map output records=3041
Map output bytes=41311
Map output materialized bytes=25212
Input split bytes=906
Combine input records=3041
Combine output records=1335
Reduce input groups=673
Reduce shuffle bytes=25212
Reduce input records=1335
Reduce output records=673
Spilled Records=2670
Shuffled Maps =9
Failed Shuffles=0
Merged Map outputs=9
GC time elapsed (ms)=43432
CPU time spent (ms)=30760
Physical memory (bytes) snapshot=1813704704
Virtual memory (bytes) snapshot=8836780032
Total committed heap usage (bytes)=1722810368
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=31714
File Output Format Counters
Bytes Written=13523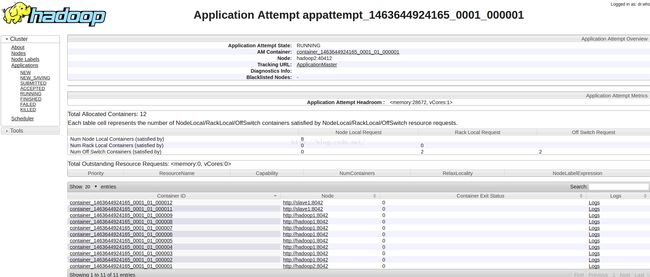
结果
[hadoop@slave1 hadoop-2.7.2]$ bin/hdfs dfs -lsr /out
lsr: DEPRECATED: Please use 'ls -R' instead.
16/05/19 16:22:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-rw-r--r-- 2 hadoop supergroup 0 2016-05-19 16:16 /out/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 13523 2016-05-19 16:16 /out/part-r-00000
[hadoop@slave1 hadoop-2.7.2]$ 测试故障自动转移
当前情况在网页查看hadoop1和slave1为Active状态,
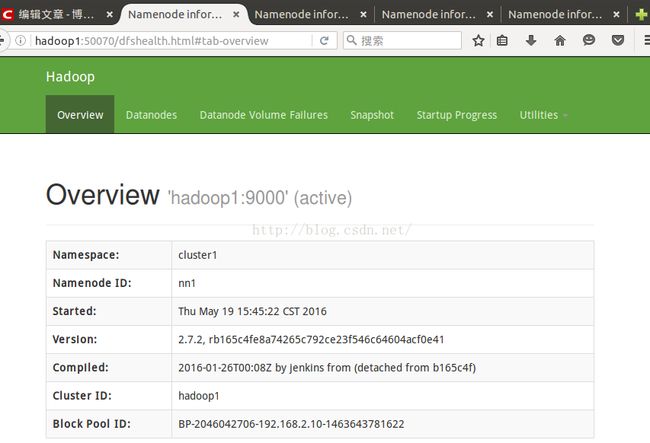
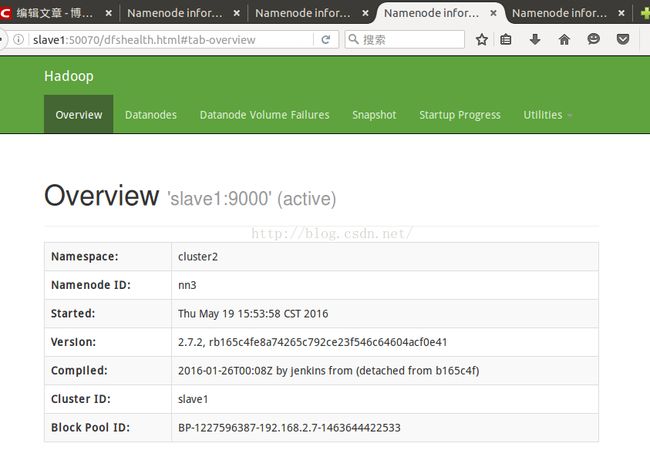
那把这两个namenode关闭,再查看
[hadoop@hadoop1 hadoop-2.7.2]$ jps
10665 DFSZKFailoverController
9551 NameNode
12166 Jps
9822 DataNode
9423 JournalNode
9039 QuorumPeerMain
10483 NodeManager
[hadoop@hadoop1 hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop namenode
stopping namenode
[hadoop@hadoop1 hadoop-2.7.2]$ jps
10665 DFSZKFailoverController
9822 DataNode
9423 JournalNode
12221 Jps
9039 QuorumPeerMain
10483 NodeManager

[hadoop@slave1 hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop namenode
stopping namenode
[hadoop@slave1 hadoop-2.7.2]$ jps
3706 DataNode
3374 JournalNode
4121 NodeManager
5460 Jps
4324 DFSZKFailoverController
3184 QuorumPeerMain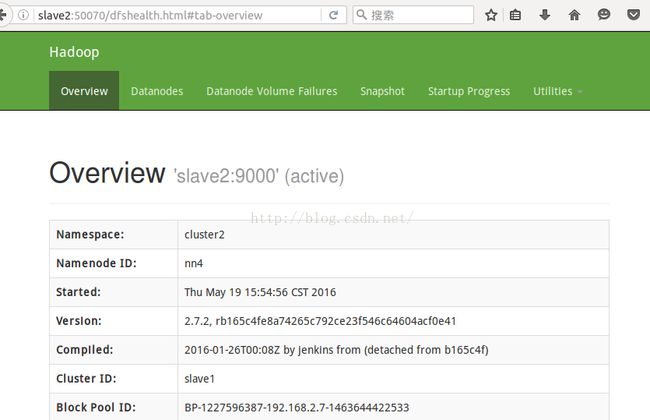
此时Active NN已经分别转移到hadoop2和slave2上了
以上是hadoop2.7.2的HDFS集群HA配置和自动切换、HDFS federation配置、Yarn配置的基本过程,其中大家可以添加其他配置,zookeeper和journalnode也不一定所有节点都启动,只要是奇数个就ok,如果集群数量多,这些及节点均可以单独配置在一个host上
特此纠正错误:
按照上面配置以后,第一次格式化的时候,有一个地方有错误,就是namenode格式化,在连个nameservice下的namenode指定的clusterId不能为两个不同的id,一定要保证为同一个cid,不然会出现一下错误,当时我没注意,后来看datanode的时候才发现有问题,一直不得其解,后来去官网看Federation的说明在发现格式化出错了,如果cid不一样会报错如下
2016-05-20 17:07:48,804 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool (Datanode Uuid unassigned) service to hadoop1/192.168.2.10:9000. Exiting.
java.io.IOException: Cluster IDs not matched: dn cid=cluster1 but ns cid=CID-91fad4b9-26cf-4c08-8466-1035509f4880; bpid=BP-841114638-192.168.2.10-1463734832788
at org.apache.hadoop.hdfs.server.datanode.DataNode.setClusterId(DataNode.java:717)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1316)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:802)
at java.lang.Thread.run(Thread.java:745)
2016-05-20 17:07:48,804 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool (Datanode Uuid unassigned) service to hadoop2/192.168.2.11:9000. Exiting.
java.io.IOException: Cluster IDs not matched: dn cid=cluster1 but ns cid=CID-91fad4b9-26cf-4c08-8466-1035509f4880; bpid=BP-841114638-192.168.2.10-1463734832788
at org.apache.hadoop.hdfs.server.datanode.DataNode.setClusterId(DataNode.java:717)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1316)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:802)
at java.lang.Thread.run(Thread.java:745) 而且在Web Ui上查看live的datanode也是有异常的,文中hadoop1和slave1的namenode格式化应纠正为以一下方式,齐总cid可以随意指定,只要保证统一即可
[hadoop@hadoop1 hadoop-2.7.2]$ bin/hdfs namenode -format -clusterId 1
16/05/23 12:23:31 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop1/192.168.2.10
STARTUP_MSG: args = [-format, -clusterId, 1]
[hadoop@slave1 hadoop-2.7.2]$ bin/hdfs namenode -format -clusterId 1
16/05/23 12:24:38 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = slave1/192.168.2.7
STARTUP_MSG: args = [-format, -clusterId, 1]
STARTUP_MSG: version = 2.7.2
然后同步standby的namenode,启动后,删除datanode节点下的version文件的目录,重新启datanode就没有报错了