如何用基于resnet的Unet进行图像分割 基于Pytorch-0.5版本
1、关于Unet
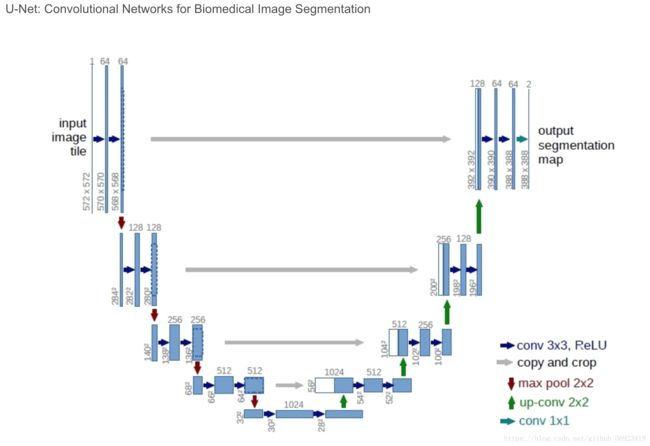
Unet主要用于医学图像的很多论文中,以及Kaggle竞赛和一些其他竞赛中“少类别”的图像分割。从我做实验的经验来说,像VOC这种类别比较多的分割任务,不容易收敛,效果较为差。
2、Resnet34
我们的encode部分选择resnet34,decode部分为每一个block制作三层卷积,其中每个的第二层为upsample(bilinear/deconv)
#基本的block
class DecoderBlock(nn.Module):
def __init__(self,
in_channels=512,
n_filters=256,
kernel_size=3,
is_deconv=False,
):
super().__init__()
if kernel_size == 3:
conv_padding = 1
elif kernel_size == 1:
conv_padding = 0
# B, C, H, W -> B, C/4, H, W
self.conv1 = nn.Conv2d(in_channels,
in_channels // 4,
kernel_size,
padding=1,bias=False)
self.norm1 = nn.BatchNorm2d(in_channels // 4)
self.relu1 = nonlinearity(inplace=True)
# B, C/4, H, W -> B, C/4, H, W
if is_deconv == True:
self.deconv2 = nn.ConvTranspose2d(in_channels // 4,
in_channels // 4,
3,
stride=2,
padding=1,
output_padding=conv_padding,bias=False)
else:
self.deconv2 = nn.Upsample(scale_factor=2,**up_kwargs)
self.norm2 = nn.BatchNorm2d(in_channels // 4)
self.relu2 = nonlinearity(inplace=True)
# B, C/4, H, W -> B, C, H, W
self.conv3 = nn.Conv2d(in_channels // 4,
n_filters,
kernel_size,
padding=conv_padding,bias=False)
self.norm3 = nn.BatchNorm2d(n_filters)
self.relu3 = nonlinearity(inplace=True)
def forward(self, x):
x = self.conv1(x)
x = self.norm1(x)
x = self.relu1(x)
x = self.deconv2(x)
x = self.norm2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.norm3(x)
x = self.relu3(x)
return x
class BasicConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes,
kernel_size=kernel_size, stride=stride,
padding=padding, bias=False) # verify bias false
self.bn = nn.BatchNorm2d(out_planes,
eps=0.001, # value found in tensorflow
momentum=0.1, # default pytorch value
affine=True)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
接下来,就是模型代码了。
class ResNet34Unet(nn.Module):
def __init__(self,
num_classes,
num_channels=3,
is_deconv=False,
decoder_kernel_size=3,
):
super().__init__()
self.mean = (0.485, 0.456, 0.406)
self.std = (0.229, 0.224, 0.225)
filters = [64, 128, 256, 512]
resnet = models.resnet34(pretrained=True)
self.base_size=512
self.crop_size=512
self._up_kwargs={'mode': 'bilinear', 'align_corners': True}
# self.firstconv = resnet.conv1
# assert num_channels == 3, "num channels not used now. to use changle first conv layer to support num channels other then 3"
# try to use 8-channels as first input
if num_channels == 3:
self.firstconv = resnet.conv1
else:
self.firstconv = nn.Conv2d(num_channels, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3),bias=False)
self.firstbn = resnet.bn1
self.firstrelu = resnet.relu
self.firstmaxpool = resnet.maxpool
self.encoder1 = resnet.layer1
self.encoder2 = resnet.layer2
self.encoder3 = resnet.layer3
self.encoder4 = resnet.layer4
# Decoder
self.center = DecoderBlock(in_channels=filters[3],
n_filters=filters[3],
kernel_size=decoder_kernel_size,
is_deconv=is_deconv)
self.decoder4 = DecoderBlock(in_channels=filters[3] + filters[2],
n_filters=filters[2],
kernel_size=decoder_kernel_size,
is_deconv=is_deconv)
self.decoder3 = DecoderBlock(in_channels=filters[2] + filters[1],
n_filters=filters[1],
kernel_size=decoder_kernel_size,
is_deconv=is_deconv)
self.decoder2 = DecoderBlock(in_channels=filters[1] + filters[0],
n_filters=filters[0],
kernel_size=decoder_kernel_size,
is_deconv=is_deconv)
self.decoder1 = DecoderBlock(in_channels=filters[0] + filters[0],
n_filters=filters[0],
kernel_size=decoder_kernel_size,
is_deconv=is_deconv)
self.finalconv = nn.Sequential(nn.Conv2d(filters[0], 32, 3, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Dropout2d(0.1, False),
nn.Conv2d(32, num_classes, 1))
def require_encoder_grad(self, requires_grad):
blocks = [self.firstconv,
self.encoder1,
self.encoder2,
self.encoder3,
self.encoder4]
for block in blocks:
for p in block.parameters():
p.requires_grad = requires_grad
def forward(self, x):
# stem
x = self.firstconv(x)
x = self.firstbn(x)
x = self.firstrelu(x)
x_ = self.firstmaxpool(x)
# Encoder
e1 = self.encoder1(x_)
e2 = self.encoder2(e1)
e3 = self.encoder3(e2)
e4 = self.encoder4(e3)
center = self.center(e4)
d4 = self.decoder4(torch.cat([center, e3], 1))
d3 = self.decoder3(torch.cat([d4, e2], 1))
d2 = self.decoder2(torch.cat([d3, e1], 1))
d1 = self.decoder1(torch.cat([d2, x], 1))
f= self.finalconv(d1)
return tuple([f])