ELK 系统 搭建
ELK 简介
ELK 是一般被称作日志分析系统,是三款开源软件的简称。通常在业务服务上线后我们会部署一套 ELK 系统,
方便我们通过图形化界面直接查找日志,快速找到问题源并帮助解决问题。
当然了任何东西都会有他的两面性的,ELK 自然也不理外啦~~~
优势:统一查询入口,多维度查询与统计,适合团队;
缺点:不适合业务前期,需要额外的硬件资源。
ELK 系统架构图

工作流程
- Filebeat 定时监控并收集每个服务的日志信息;
- Logstash 把格式化日志信息发送到 ES 中进行存储,同时发送到监控预警服务进行处理;
- 监控中心处理日志内容,配置相应策略通过邮件或者即时通讯方式告知开发人员;
- Kibana 结合 ES 提供的搜索功能进行查询,使用 Kibana 自带的图表功能进行统计。
开始搭建:
- elasticsearch 搭建: 参考我之前的Elasticsearch 搭建流程
- Filebeat 搭建
2.1. 下载源文件
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.3-x86_64.rpm
2.2 解压
tar -zxvf filebeat-6.2.3-linux-x86_64.tar.gz
2.3. 进入解压后的文件夹,配置 filebeat.yml
filebeat.prospectors:
- type: log
enabled: true # 开关
paths: # 日志文件路径,可以用用通配符
- /var/log/xxx-info.log #
#- c:\programdata\elasticsearch\logs\* 如果是windows服务器,用这个路径
multiline: # 日志多行处理,列如java的堆栈信息
pattern: ^\d{4} # 匹配前缀为数字开头,如果不是日期,该行日志接到上一行后尾
negate: true
match: after
fields: # 自定义属性,用于 Logstash 中
service_name: customer # 产生日志的服务名
log_type: info # 日志文件类型
server_id: ip-address # 服务器ip地址
scan_frequency: 50 #扫描间隔,单位为秒;设置太小会引起filebeat频繁扫描文件,导致cpu占用百分比过高
- type: log
enabled: true
paths:
- /var/log/customer-error.log
multiline:
pattern: ^\d{4}
negate: true
match: after
fields:
service_name: customer
log_type: error
server_id: 127.0.0.1
scan_frequency: 60
output.logstash: # 输出到logstash的安装位置,以及监听的端口
hosts: ["129.1.7.203:5043"]
启动 filebeat 的命令为:./filebeat -e -c filebeat.yml
可能会有同学好奇,问什么要使用Filebeat 采集日志信息,再输送到logstash 中
为什么使用 Filebeat 而不是直接使用 Logstash 来收集日志?原因有以下几点。
1. Filebeat 更加的轻量级,Logstash 占用更多的系统资源,如果在每个服务器上部署 Logstash,
有时候会影响到业务服务,导致服务响应缓慢;
2. Filebeat 能够记录文件状态,文件状态记录在文件中(~FILEBEAT_HOME/data/registry)。
此状态可以记住 harvesters 收集文件的偏移量,重启后 prospectors 能知道每个日志文件的记录状态
再进行收集文件;
3. Filebeat 保证至少有一次输出,因为 Filebeat 将每个事件的传递状态保存在文件中。在没有得到接收方
确认时,会尝试一直发送,直到得到回应。
传输:将日志数据传送给中央处理系统
3. logstash 搭建
Logstash 监控 Beats 源并且将 Beats 的数据进行过滤处理,Logstash 的优势是有非常丰富的插件提供使用。Logstash 的工作模式如下: 一张图片说明 (!-_-)
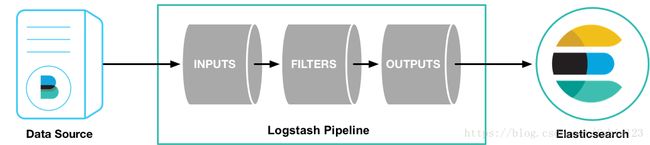
logstash通过管道pipeline进行传输,必选的两个组件是输入input和输出output,还有个可选过滤器filter
logstash将数据流中等每一条数据称之为一个event,即读取每一行数据的行为叫做事件
#输入
input {
...
}
# 过滤器
filter {
...
}
# 输出
output {
...
}
3.1. 安装, 同样是下载解压
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.3.tar.gz
tar -zxvf kibana-6.2.3-linux-x86_64.tar.gz
3.2. Logstash 的配置文件 logstash.conf
input { # 指定输入源-beats- filebeat
beats {
host => "localhost"
port => "5043"
}
}
filter { # 日志格式化,使用 grok 插件
if [fields][log_type] == 'error' { # 如果是error类型的日志该怎么处理,在filebeat 的fields中定义
grok { # 使用 grok 插件进行一整条日志信息格式成key-value信息
match => { "message" => "%{TIMESTAMP_ISO8601:logdate} %{LOGLEVEL:loglevel} %{JAVACLASS:class} %{NUMBER:thread} %{JAVALOGMESSAGE:logmsg}" } # 这里采用的是grok预制的一些正则,":"后面是我们自定义的key
}
date { # 将 kibana 的查询时间改成日志的打印时间,方便之后查询,如果不改的话,kibana会有自己的时间,导致查询不方便
match => ["logdate", "yyyy-MM-dd HH:mm:ss Z", "ISO8601"]
target => "@timestamp"
}
}
if [fields][log_type] == 'info' { # 如果是info类型该怎么格式,这里是重复的,如果有日志格式不一样比如nginx的日志类型,可以在这里自己定义
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:logdate} %{LOGLEVEL:loglevel} %{JAVACLASS:class} %{NUMBER:thread} %{JAVALOGMESSAGE:logmsg}" }
}
date {
match => ["logdate", "yyyy-MM-dd HH:mm:ss Z", "ISO8601"]
target => "@timestamp"
}
}
}
output { # 输出设置
stdout { # 输出到控制台
codec => rubydebug
}
# 输出到elasticsearch,提供给kibana进行搜索
elasticsearch {
hosts => [ "localhost:9200" ]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}" # 在es中存储的索引格式,按照“服务名-日期”进行索引
}
if "ERROR" == [loglevel] { # 如果是ERROR日志单独发一份邮件给管理者,在写了日志处理中心后这里可以去掉,然后交给日志处理中心处理
email {
to => "[email protected]"
via => "smtp"
subject => "WARN: %{[fields][service_name]}项目出现ERROR异常"
htmlbody => "error_message:%{message}\\nhost:%{[fields][service_id]}\\nkibana:http://127.0.0.1:5601"
from => "[email protected]"
address => "smtp.163.com"
username => "[email protected]"
password => "password1234"
}
}
}
Logstash 的输入插件有很多 可参考input插件 ,可以根据实际情况选择不同的输入插件,由于是使用 Filebeat 做日志搜集,这里采用 beats 作为输入源。Logstash 在实际的日志处理中,最主要的作用是做日志的格式化与过滤,它的过滤插件有非常多 可参考ilter插件 ,我们在实际中主要用到的过滤插件是 Grok ,它是一种基于正则的方式来对日志进行格式化和过滤。
Grok 的语法规则是:%{预置正则表达式:自定义属性名称},如:%{TIMESTAMP_ISO8601:logdate}。
前面的 TIMESTAMP_ISO8601 是预置的一些 Grok 表达式。更多预置的 Grok 表达式请访问:
[Grok 预置正则表达式](https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns)。
如果预置 Grok 表达式的不能满足实际需求,可以写自定义的表达式,语法为:(?<自定义属性名称>正则表达式)。
例如,我们在 Java 中有时遇到线程名:DiscoveryClient-InstanceInfoReplicator-0, 这个时候可以自定义表达式为:
(?[A-Za-z0-9-]+[\d]?)。
Grok 在线调试工具为 [Grok Debugger](https://grokdebug.herokuapp.com/)。
在 Logstash 的输出插件中我们指定四个输出位置:控制台、HTTP、Elasticsearch、Email。
控制台:其中控制台输出主要方便最初的调试;
Elasticsearch:输出到 Elasticsearch 是为了作为 Kibana 之后进行搜索和查询的来源;
HTTP:输出到日志处理中心方便我们在日志处理中心做进一步处理,包括通知与告警策略处理;
Email:适合在前期量小的时候,人员能快速响应,在有日志处理中心后,可以去掉 Email 输出。
- Kibana 搭建:
# 下载安装包
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.3-linux-x86_64.tar.gz
#解压
tar -zxvf kibana-6.2.3-linux-x86_64.tar.gz
# 进入解压好的文件目录
cd kibana-6.2.3-linux-x86_64
# 启动
./bin kibana
至此,ELK 系统就简单的搭建起来了。。。
在搭建的过程中会有一些常见的问题,这里简单记录一下解决方案:
1、JVM内存溢出导致的 ES或者Logstash服务启不来,报错 insufficient memory
解决:升级机器的内存和CPU;
或者改elasticSeach和logstash的JVM.option,最大堆内存xmx和初始堆内存xms
2、ES启动报错
seccomp unavailable: CONFIG_SECCOMP not compiled into kernel, CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER are needed
修改elasticsearch.yml 添加一下内容
bootstrap.memory_lock: false 为了避免内存和磁盘之间的swap
bootstrap.system_call_filter: false
3、ERROR: bootstrap checks failed max virtual memory areas vm.max_map_count [65530] is too low, increase to at least
临时设置:sudo sysctl -w vm.max_map_count=262144
永久修改:
修改/etc/sysctl.conf 文件,添加 “vm.max_map_count”设置
并执行:sysctl -p