词法分析器 Java完整代码版
想了解更多内容,移步至编译原理专栏
这学期选修了编译原理,用的是電子工业出版社出版的《编译原理(第4版)》
最近做了第一次实验词法分析器,是教材后面的附录c.1的内容,根据下面的图创建词法分析器
课本给出了C语言版本的词法分析器,但是看着挺蛋疼的,感觉C语言的指针很烦,于是做了一个Java版本的,说简单也挺简单的(其实大部分是把C语言版本的代码直接复制过来)哈哈。
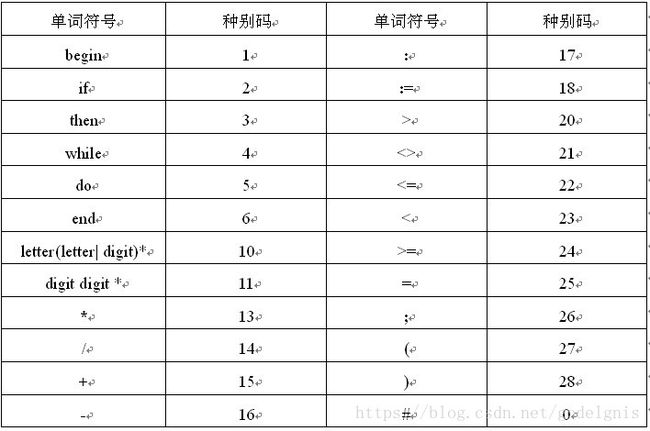
老师的实验要求是

所以对书上的代码输入输出的代码进行修改,另外,书上代码中的种别码与上面的表格不是对应的,所以也要进行修改
废话不多说,直接上代码
package codescanner;
public class Word {
private int typenum; //种别码
private String word; //扫描得到的词
public int getTypenum() {
return typenum;
}
public void setTypenum(int typenum) {
this.typenum = typenum;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
}
public class CodeScanner {
private static String _KEY_WORD_END = "end string of string";
private int charNum = 0;
private Word word;
private char[] input = new char[255];
private char[] token = new char[255];
private int p_input=0;
private int p_token=0;
private char ch;
private String[] rwtab = {"begin","if","then","while","do","end","",_KEY_WORD_END};
public CodeScanner(char[] input) {
this.input = input;
}
/**
* 取下一个字符
* @return
*/
public char m_getch() {
if(p_input < input.length) {
ch = input[p_input];
p_input++;
}
return ch;
}
/**
* 如果是标识符或者空白符就取下一个字符
*/
public void getbc() {
while((ch == ' ' || ch == '\t') && p_input < input.length) {
ch=input[p_input];
p_input++;
}
}
/**
* 把当前字符和原有字符串连接
*/
public void concat() {
token[p_token] = ch;
p_token++;
token[p_token] = '\0';
}
public boolean letter() {
if(ch>='a'&&ch<='z'||ch>='A'&&ch<='Z')
return true;
else
return false;
}
public boolean digit() {
if(ch>='0'&&ch<='9')
return true;
else
return false;
}
/**
* 回退一个字符
*/
public void retract() {
p_input--;
}
/**
* 将token中的数字串转换成二进制值表示
* @return
*/
public String dtb() {
int num = token[0] - 48;
for(int i = 1; i < p_token; i++) {
num = num * 10 + token[i] - 48;
}
StringBuilder result = new StringBuilder();
while(num>0) {
int r = num % 2;
int s = num / 2;
result.append(r);
num = s;
}
return result.reverse().toString();
}
/**
* 查看token中的字符串是否是关键字,是的话返回关键字种别编码,否则返回10
* @return
*/
public int reserve() {
int i=0;
while(rwtab[i].compareTo(_KEY_WORD_END)!=0) {
if(rwtab[i].compareTo(new String(token).trim()) == 0) {
return i+1;
}
i++;
}
return 10;
}
/**
* 能够识别换行,单行注释和多行注释的
* 换行的种别码设置成30
* 多行注释的种别码设置成31
* @return
*/
public Word scan() {
token = new char[255];
Word myWord = new Word();
myWord.setTypenum(10);
myWord.setWord("");
p_token=0;
m_getch();
getbc();
if(letter()) {
while(letter()||digit()) {
concat();
m_getch();
}
retract();
myWord.setTypenum(reserve());
myWord.setWord(new String(token).trim());
return myWord;
}else if(digit()) {
while(digit()) {
concat();
m_getch();
}
retract();
myWord.setTypenum(11);
myWord.setWord(new String(token).trim()); //输出token中的数字串字符形式
// myWord.setWord(dtb()); //输出token中的数字串10进制值的二进制字符串形式
return myWord;
}
else
switch (ch) {
case '=':
myWord.setTypenum(25);
myWord.setWord("=");
return myWord;
case '+':
myWord.setTypenum(13);
myWord.setWord("+");
return myWord;
case '-':
myWord.setTypenum(14);
myWord.setWord("-");
return myWord;
case '*':
myWord.setTypenum(15);
myWord.setWord("*");
return myWord;
case '/':
m_getch();
//识别单行注释
if (ch == '/') {
while(m_getch() != '\n');
myWord.setTypenum(30);
myWord.setWord("\\n");
return myWord;
}
//识别多行注释
if(ch=='*') {
String string = "";
while(true) {
if (ch == '*') {
if (m_getch() == '/') {
myWord.setTypenum(31);
myWord.setWord(string);
return myWord;
}
retract();
}
if (m_getch() == '\n') {
string += "\\n";
}
}
}
retract();
myWord.setTypenum(16);
myWord.setWord("/");
return myWord;
case ':':
m_getch();
if(ch=='=') {
myWord.setTypenum(18);
myWord.setWord(":=");
return myWord;
}
retract();
myWord.setTypenum(17);
myWord.setWord(":");
return myWord;
case '<':
m_getch();
if(ch=='=') {
myWord.setTypenum(22);
myWord.setWord("<=");
return myWord;
}else if (ch == '>') {
myWord.setTypenum(21);
myWord.setWord("<>");
return myWord;
}
retract();
myWord.setTypenum(20);
myWord.setWord("<");
return myWord;
case '>':
m_getch();
if(ch=='=') {
myWord.setTypenum(24);
myWord.setWord(">=");
return myWord;
}
retract();
myWord.setTypenum(23);
myWord.setWord(">");
return myWord;
case ';':
myWord.setTypenum(26);
myWord.setWord(";");
return myWord;
case '(':
myWord.setTypenum(27);
myWord.setWord("(");
return myWord;
case ')':
myWord.setTypenum(28);
myWord.setWord(")");
return myWord;
case '\n':
myWord.setTypenum(30);
myWord.setWord("\\n");
return myWord;
case '#':
myWord.setTypenum(0);
myWord.setWord("#");
return myWord;
default:
concat();
myWord.setTypenum(-1);
myWord.setWord("ERROR INFO: WORD = \"" + new String(token).trim() + "\"");
return myWord;
}
}
}package codescanner;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.util.ArrayList;
import java.util.Scanner;
public class Analyzer {
private File inputFile;
private File outputFile;
private String fileContent;
private ArrayList list = new ArrayList<>();
public Analyzer(String input,String output) {
inputFile = new File(input);
outputFile = new File(output);
}
/**
* 从指定的文件中读取源程序文件内容
* @return
*/
public String getContent() {
StringBuilder stringBuilder = new StringBuilder();
try(Scanner reader = new Scanner(inputFile)) {
while (reader.hasNextLine()) {
String line = reader.nextLine();
stringBuilder.append(line + "\n");
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return fileContent = stringBuilder.toString();
}
/**
* 先将源程序中的注释和换行替换成空串
* 然后扫描程序,在程序结束前将扫描到的词添加到list中
* 最后把扫描结果保存到指定的文件中
*/
public void analyze(String fileContent) {
int over = 1;
Word word = new Word();
//fileContent = fileContent.replaceAll("//.*\n", "") // 去除字符串fileContent中所有的单行注释 与 换行
// .replaceAll("/\\*{1,2}[\\s\\S]*?\\*/", ""); // 去除字符串fileContent中所有的多行注释
//现在不用正则表达式也可以识别换行和单行注释和多行注释了
CodeScanner scanner = new CodeScanner(fileContent.toCharArray());
while (over != 0) {
word = scanner.scan();
// System.out.println("(" + word.getTypenum() + " ," + word.getWord() + ")"); //在控制台输出结果
list.add(word);
over = word.getTypenum();
}
saveResult();
}
/**
* 将结果写入到到指定文件中
* 如果文件不存在,则创建一个新的文件
* 用一个foreach循环将list中的项变成字符串写入到文件中
*/
public void saveResult() {
if (!outputFile.exists())
try {
outputFile.createNewFile();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
try(Writer writer = new FileWriter(outputFile)){
for (Word word : list) {
writer.write("(" + word.getTypenum() + " ," + word.getWord() + ")\n");
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
Analyzer analyzer = new Analyzer("input.txt","output.txt");//输入输出可自己修改,文件放在当前文件夹下,刷新项目就可以看到了
analyzer.analyze(analyzer.getContent());
}
}
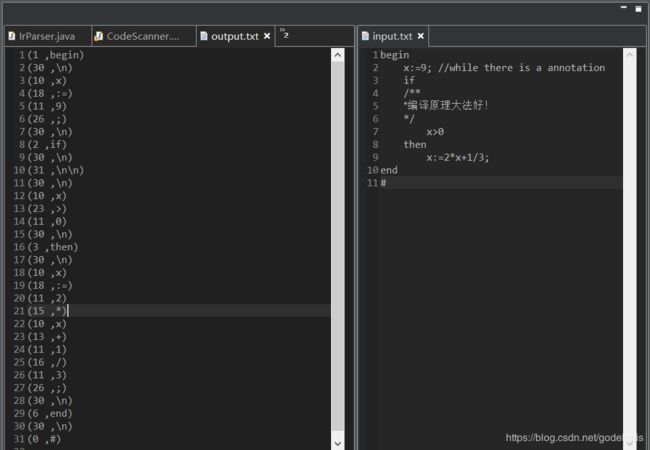
测试数据
begin
x:=9; //while there is a annotation
if
/**
*编译原理大法好!
*/
x>0
then
x:=2*x+1/3;
end
#结果
觉得写得还可以得话,可以给我点个赞呀:)