推荐系统——(论文阅读笔记)YouTube推荐中的深层神经网络
这篇文章是阅读YouTube的《Deep Neural Networks for YouTube Recommendations》后的一点总结,这篇文章值得详细阅读,因此将其中的核心点整理出来。
文章的重点
- 1、总结推荐系统的架构
- 2、如何利用深度模型做召回
- 3、如何利用深度模型做Ranking
1、推荐系统的架构
在本文中,推荐系统的架构与其他的推荐架构极为类似,都是由两个部分组成:1、候选集生成;2、ranking。详细的架构如下图所示:

这样的一种漏斗模型在很多地方都会使用到,漏斗模型如下图所示:

在上述的架构中,两个部分对应的功能为:
- 候选集生成模块(Candidate Generation)负责从百万的视频数据集中知道到几百个与用户相关的待推荐视频;
- Ranking模块负责从候选集生成模块产生的待推荐列表中再选择几十个视频,用于展示给用户。
同时,上述的架构也是一种分层的架构,这样,在候选集生成部分就可以加入不同的挖掘方法挖掘出的相关视频。
2、候选集生成模块
2.1、问题建模
对于候选集的生成模块,需要从视频集中选择出与用户相关的视频。本文中作者提出将其看成一个极多分类问题(extreme multiclass classification problem):
基于特定的用户 U U U和上下文 C C C,在时间 t t t将指定的视频 w t w_t wt准确地划分到第 i i i类中,其中 i ∈ V i\in V i∈V。
P ( w t = i ∣ U , C ) = e v i u ∑ j ∈ V e v j u P\left ( w_t=i\mid U,C \right )=\frac{e^{v_iu}}{\sum _{j\in V}e^{v_ju}} P(wt=i∣U,C)=∑j∈Vevjueviu
其中, u ∈ R N u\in \mathbb{R}^N u∈RN表示的是用户和上下文组合的向量; v j ∈ R N v_j\in \mathbb{R}^N vj∈RN表示视频 j j j的向量。
极多分类的高效训练:
假设存在百万个类别时,训练这样的极多分类问题时显得异常困难。
解决的方法——负类采样(sample negative classes): 通过采样找到数千个负类。
2.2、神经网络的结构
召回训练的神经网络结构如下图所示:
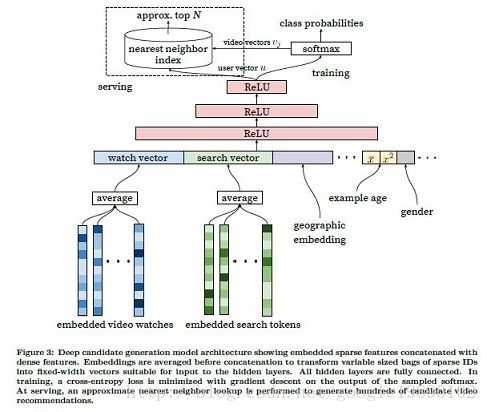
在上面的神经网络的结构中,包含了两个阶段,分别为训练阶段和服务阶段:
- 训练部分会得到两个部分的数据:视频的embedding v j v_j vj和用户的embedding u u u
- 服务阶段直接使用上述的两个embedding,两个向量的相似度的方法在这里都可以使用。
2.3、召回神经网络的训练
对于服务阶段使用到的相似向量的计算方法不在本文的讨论范围内,在这里着重讨论该神经网络的训练。
2.3.1、训练数据
从上面的神经网络的结构中可以看出,神经网络的训练数据主要包括如下的几个部分:
- 用户观看的视频(video watches)。将用户观看过的视频初始化为向量,假设有 n n n个观看记录,需要将这 n n n个记录压缩成一个向量,方法主要有:求均值,求和,按位取max。在本文的实验中,求均值的效果最好。在训练的过程中,视频的向量与模型的参数一同参与训练,具体过程可以参见词向量的训练。
- 用户的搜索记录(search tokens)。处理方法与用户观看的视频一致。
- 人口统计学的特征(demographic features)。如用户的地理位置,设备需要embedding,而如用户性别,登录状态以及年龄这样的二进制和连续的特征只需归一化到 [ 0 , 1 ] \left [ 0,1 \right ] [0,1]便可以直接作为输入。
3、Ranking模块
Ranking部分是从候选集中进行进一步的优选,除了上述的候选集生成方法,Ranking部分可以融入更多的其他的候选集。
3.1、问题建模
本文作者在这个部分没有使用点击率作为问题的目标,而是使用了观看时长(watch time)。因为如果使用点击率,用户可能并没有完成观看,使用观看时长,可以更好地捕捉用户的参与(原文的意思是说:会存在“clickbait”)。在神经网络的最后一层使用的方法二分类的Logistic Regression,训练样本为:
- 正例:展示的视频被点击
- 负例:展示的视频未被点击
正例同时伴随着用户观看的总时长。为了能够预测用户的期望观看时长,使用的是加权Logistic Regression(Weighted Logistic Regression)。
在加权Logistic Regression中,正样本的权重是video观看的时长,负样本的权重是单位权重。此时,Logistic Regression输出的odds为:
∑ T i N − k \frac{\sum T_i}{N-k} N−k∑Ti
正样本的权重/负样本的权重
其中, N N N表示的是训练样本的数目, k k k表示的是正样本的数目, T i T_i Ti表示的是第 i i i个展示被观看的时长。
假设正例的展示比较小(这与实际情况一致,多数为负样本),学习到的概率近似为 E [ T ] ( 1 + P ) E\left [ T \right ]\left ( 1+P \right ) E[T](1+P),其中, P P P表示的是点击率, E [ T ] E\left [ T \right ] E[T]表示的是展示的期望观看时长,由于 P P P非常小,所以上述的结果近似于 E [ T ] E\left [ T \right ] E[T],即期望观看时长。
在预测时,使用指数函数 e x e^x ex作为最终的激活函数来表示概率。
3.2、Ranking模块的神经网络架构
Ranking部分的神经网络架构与候选集生成部分的神经网络的架构模型类似,如下图所示:
3.3、Ranking神经网络的训练
在本文中,作者将特征划分为离散型的类别特征和连续特征,此时的难点是如何生成有用的特征。
3.3.1、离散型类别特征的Embedding
对于离散型的类别特征,处理的方法与召回部分一致——embedding。在候选集生成过程中,已经生成了每一个ID视频对应的embedding,将该embedding存在一张表里面,可以供上述的impression,last watched共享。
3.3.2、连续特征的正则化
与基于决策树的组合方法相比,神经网络对于输入的伸缩和分布很敏感。对连续特征的合理正则化对于神经网络的收敛只管重要。
如果 x x x服从任意分布,且其概率密度函数为 f ( x ) f\left ( x \right ) f(x),则利用累计分布函数:
x ~ = ∫ − ∞ x d f \tilde{x}=\int_{-\infty }^{x}df x~=∫−∞xdf
则 x ~ \tilde{x} x~为 [ 0 , 1 ) \left [ 0,1 \right ) [0,1)上的均匀分布。
除了上述的 x ~ \tilde{x} x~,还有 x ~ 2 \tilde{x}^2 x~2和 x ~ \sqrt{\tilde{x}} x~。