SparkStreaming之Offset管理、胖包和瘦包提交
1、Offset管理
Kafka从0.10.x开始Offset偏移量就自从维护在Kafka内部中,看下面代码。
注意,我们使用的是earliest从头开始消费,也就是说如果你的SparkStreaming刚开始启动,那么会从Kafka对应的Topic从第一条数据开始消费到当前。
下面模拟,第一次消费后DStream停止了,但是Kafka依然在生产数据,再次启动DStream会从什么位置消费。
package com.ruozedata.spark
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.{SparkConf, TaskContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DirectKafkaApp {
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setMaster("local[2]").setAppName("SocketWCApp")
val ssc=new StreamingContext(sparkConf,Seconds(10))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "vm01:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "earliest", // latest 最新的 earliest从头开始消费
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("g6spark")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
//PreferBrokers,
Subscribe[String, String](topics, kafkaParams)
)
stream.map(record => record.value).flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
.print()
// offset偏移量管理
stream.foreachRDD{ rdd=>
val offsetRanges=rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreachPartition{ iter =>
val o: OffsetRange=offsetRanges(TaskContext.get.partitionId())
//打印topic,所在分区,offset开始位置,offset结束位置
println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")
}
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) //异步提交offset
}
ssc.start()
ssc.awaitTermination()
}
}
启动Kafka,看博客:https://blog.csdn.net/greenplum_xiaofan/article/details/99224269
然后启动上面的DSstream应用程序,第一次消费Kafka的数据
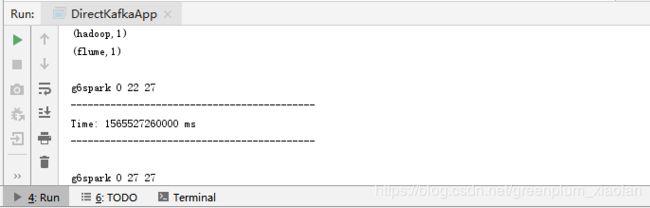
结果如下,可以看到topic=>g6spark,分区=>0,offset读取位置=>22,offset最后位置=>27
因为我的topic里面有数据啊,所以第一次启动,肯定读取了以前的数据,这个没关系。
停止DStream程序,Kafka继续生产数据
[hadoop@vm01 bin]$ ./kafka-console-producer.sh \
> --broker-list vm01:9092 \
> --topic g6spark
>hello,spark
>hello,hadoop
>hello,flume
>hello,spark
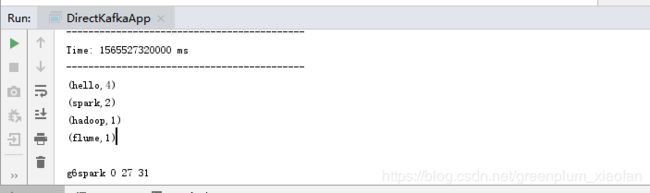
然后再次启动DStream程序,我们可以看到是从offset=27这个位置开始读取的。
2、瘦包和胖包提交
2.1 SparkStreaming执行代码
瘦包:只有源码,没有带依赖的。
胖包:除了源码,还附加开发环境依赖的包。
实际工作中我们肯定是要用瘦包提交的,试想一下如果开发环境和生产环境依赖的包不同,程序肯定会报错;当然也有特殊情况,在缺少小部分依赖的情况下,可以带上这些依赖,或者直接上传过去就行。
package com.ruozedata.spark
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DirectKafkaApp02 {
def main(args: Array[String]): Unit = {
//传递三个参数,做判断
if(args.length !=3){
System.err.println("Usage:DirectKafkaApp " )
System.exit(1)
}
val Array(brokers,topic,groupid)=args
//注释部分,肯定是在spark-submit的时候设置
val sparkConf=new SparkConf()//.setMaster("local[2]").setAppName("SocketWCApp")
val ssc=new StreamingContext(sparkConf,Seconds(10))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupid,
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
//如果多个topic,就使用逗号分隔
val topics = topic.split(",")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.map(record => record.value).flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
}
}
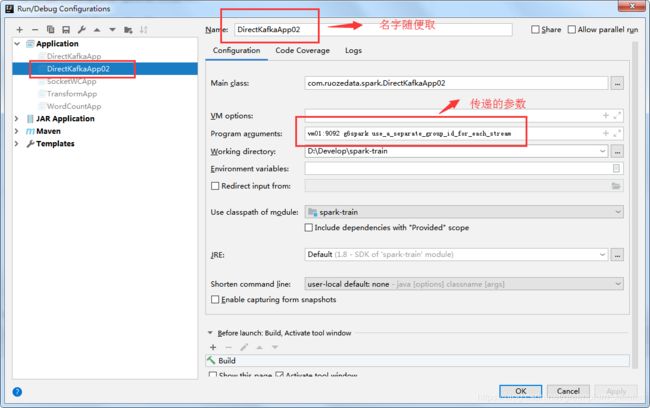
2.2 先本地验证ok,再提交
先开放这一段,//.setMaster(“local[2]”).setAppName(“SocketWCApp”)
#参数
vm01:9092 g6spark use_a_separate_group_id_for_each_stream
启动执行,ok
然后再注释刚才那段,进行下面的操作
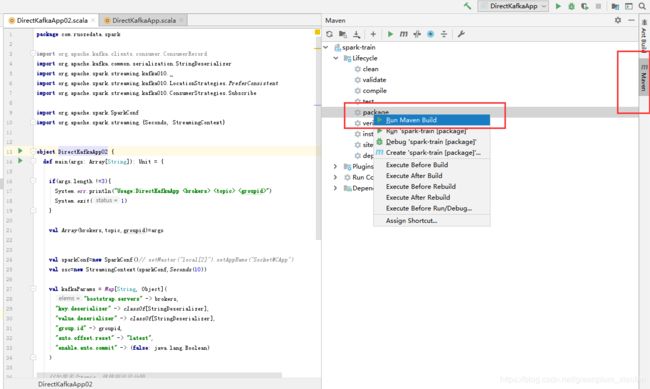
2.3 首先说下瘦包如何打包和提交
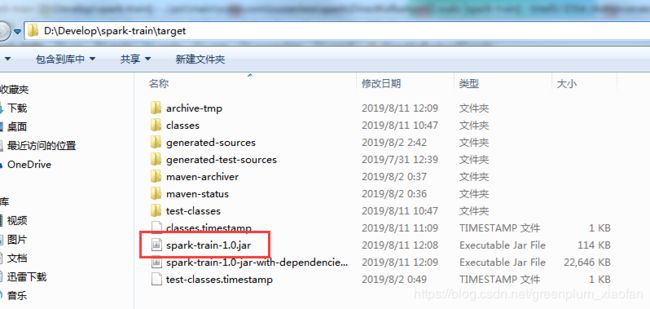
打包:运行后,会生成在你的Project工作空间下。
提交:
[hadoop@vm01 bin]$ cd $SPARK_HOME
[hadoop@vm01 spark-2.4.2-bin-2.6.0-cdh5.7.0]$ cd bin
[hadoop@vm01 bin]$ ./spark-submit \
--master local[2] \
--name kafkaStreaming \
--class com.ruozedata.spark.DirectKafkaApp02 \
--packages org.apache.spark:spark-streaming-kafka-0-10_2.11:2.4.0 \
/home/hadoop/lib/spark-train-1.0.jar \
vm01:9092 g6spark use_a_separate_group_id_for_each_stream
说明:
–name kafkaStreaming \ 名字随便取
–class com.ruozedata.spark.DirectKafkaApp02 \ 要运行的类,全路径的
–packages org.apache.spark:spark-streaming-kafka-0-10_2.11:2.4.0 \ 这个因为集群里面没有Kafka依赖包,所以提交的时候要告诉集群,在哪里下载
/home/hadoop/lib/spark-train-1.0.jar \ 包存房目录
vm01:9092 g6spark use_a_separate_group_id_for_each_stream 传递的三个参数
Kafka生产数据
[hadoop@vm01 bin]$ ./kafka-console-producer.sh \
> --broker-list vm01:9092 \
> --topic g6spark
>hello,spark
>hello,hadoop
>hello,flume
>hello,spark
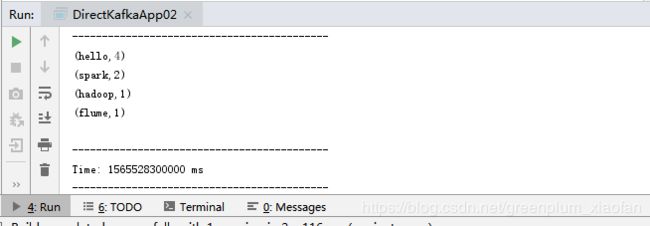
Spark提交端消费到的数据
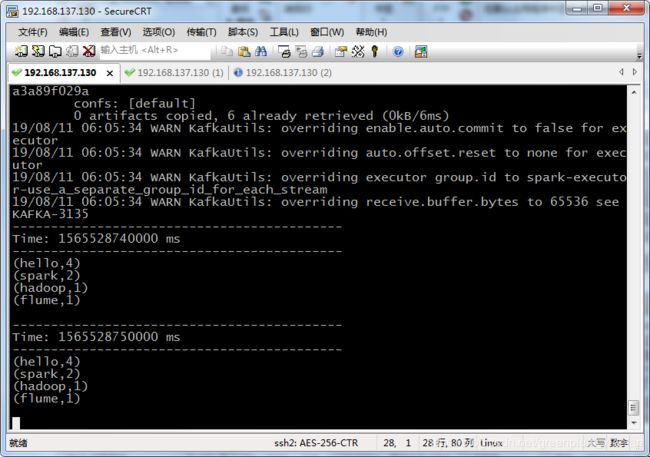
2.4 胖包如何打包和提交
这里有个概念:provided
在pom.xml标记为provided,那么在打包的时候,被标记的依赖是不会打包的,被标记的说明在集群上存在这些依赖。
比如,这个就需要你自己好好去标记了。
org.apache.spark
spark-streaming_2.11
${spark.version}
provided
然后还需要添加一段插件,添加在
org.apache.maven.plugins
maven-assembly-plugin
jar-with-dependencies
然后开始打包
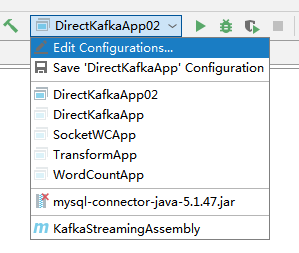
如果你的没有看到Maven,左上角“+”添加,name随便取一个
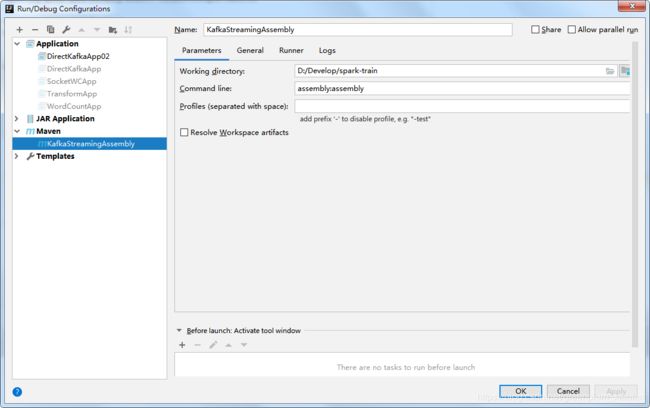
然后运行,打出来的jar包是 spark-train-1.0-jar-with-dependencies.jar
打包之后,就附带上了所有需要的依赖
接下来就是提交,测试和上面的一样了。
[hadoop@vm01 bin]$ ./spark-submit \
--master local[2] \
--name kafkaStreaming \
--class com.ruozedata.spark.DirectKafkaApp02 \
/home/hadoop/lib/spark-train-1.0-jar-with-dependencies.jar \
vm01:9092 g6spark use_a_separate_group_id_for_each_stream