六:Spark集群安装和部署
写在前面:
1.我的系统配置:
(1) 安装一个虚拟机:三个ubuntu16.04系统;
(2) Master节点:内存分配2g;Slave1节点:内存分配512MB;Slave2节点:内存分配512MB;
2. 安装路径:
(1) Hadoop2.6.5:/usr/local/;
(2) Spark2.6.0:/usr/local/;
(3) Scala2.11.7:/usr/;
(4) Jdk 1.8.0_151:/usr/lib/jvm/。
一:hadoop集群部署
spark集群是基于hadoop集群来进行部署的,至于为什么本人也没有进行深入的研究,目前知识知道spark文件需要用到hadoop的hdfs系统进行存储。
注:。无特殊说明所有的命令都是在~(也就是:home/hadoop)目录下执行。
1. 首先要创建hadoop用户(也可以不创建)
(1) 创建用户:sudo useradd -m hadoop -s /bin/bash;
(2) 密码设置:sudo passwd 【你想要设置的密码】;
(3) 切换到hadoop用户:su hadoop。
2. ssh无密码登录
(1) 更新apt(后面会用到apt进行软件的安装):
(2) 安装vim:sudo apt-get install vim;
(3) 安装SSh server:sudo apt-get install openssh-server;
(4) 登录本机:ssh localhost。首次登录会有(yes/no)?的提示输入:yes;然后会有输入密码的提示:上面创建hadoop用户时设置的密码;
(5)生成密钥并加入授权:
~$ exit(//退出ssh localhost);
~$ cd ~/.ssh(//没有该目录,执行一次:ssh localhost);
~$ ssh-keygen -t rsa (//有提示按回车即可);
~$ cat ./id_rsa.pub >> ./authorized_keys( //加入授权)。
再次用 ssh localhost 登陆时已经不需要输入密码:


3. 安装、配置JDK
安装如下:

jdk环境变量配置(下图中其他的环境变量不用理会这是我之前配置的,到后面就会明白其他环境变量的用途):

4. 安装hadoop2.6.5
(1) hadoop2.6.5下载连接:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.6.5/
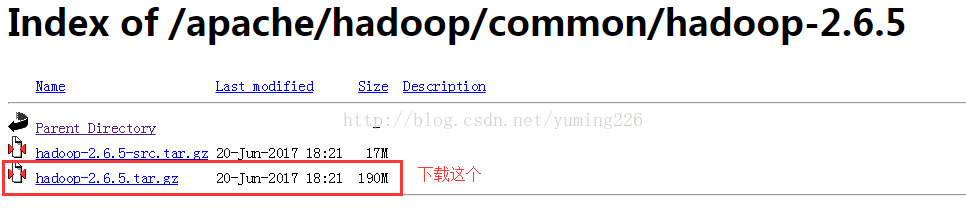
(2) 安装hadoop2.6.5
首先将hadoop2.6.5解压缩,然后移到/usr/local目录下(若没有该目录者建立该目录),并将解压的文件夹取名为hadoop:

修改主机名(另外两个节点也时同样的配置):sudo vim /etc/hostname;
配置主机名与IP地址之间的映射:


用ping命令查看是否配置成功:ping Slave1 -c 4;ping Slave2 -c 4

5. ssh无密码登录设置(由于上面修改了主机名因此需要重新设置)
(1) 参考2节的(5)部分;
(2) 将公匙传输到其他两个节点上(由于其他原因本人在Slave1节点上进行了操作,读者一点要在Mater节点上进行操作,其中[email protected]读者要换成你的从节点的Ip地址)

接着就是在节点上将ssh加入授权:
~$ mkdir ~/.ssh
~$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
~$ rm ~/id_rsa.pub
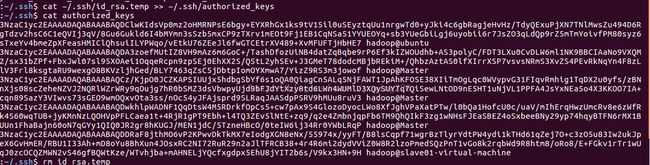
用 ssh 【从节点IP地址】登陆时已经不需要输入密码:

(3) 配置hadoop的环境变量如下图(图中的其他的环境变量也可以添加上到后面就不用添加了):

最后执行:source ~/.bashrc 使配置的环境变量生效。
6. 配置分布式环境
(1) 首先进入 /usr/locl/hadoop/etc/hadoop 目录下:

(2) 配置slaves文件(可能会不存在slaves文件,需要把以slaves-开头的文件用mv或cp命令重命名为slaves) ,配置如下:

(3) core-site.xml文件配置:
fs.defaultFS
hdfs://Master:9000
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
(4)hdfs-site.xml文件配置如下(其中dfs.replicatio的值为从节点的个数,本人的有两个Slave1和Slave2所以其值为2):
dfs.namenode.secondary.http-address
Master:50090
dfs.replication
2
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
(5)mapred-site.xml文件配置(需要将mapred-site.xml.template用mv命令进行重命令)
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
Master:10020
mapreduce.jobhistory.webapp.address
Master:19888
(6) yarn-site.xml文件配置:
yarn.resourcemanager.hostname
Master
yarn.nodemanager.aux-services
mapreduce_shuffle
(7) 将Master上的/usr/local/hadoop文件夹复制到从节点:
~$ cd /usr/local
~$ sudo rm -r ./hadoop/tmp (//删除hadoop临时文件);
~$ sudo rm -r ./hadoop/logs/* (//删除日志文件);
~$ tar -zcf ~/hadoop.master.tar.gz ./hadoop (//先压缩再复制);
~$ cd ~
~$ scp ./hadoop .master.tar.gz Slave1:/home/hadoop
~$ scp ./hadoop.master.tar.gz Slave2:/home/hadoop
再在个从节点上执行:
~$ sudo rm -r /usr/local/hadoop (//如果存在则删除);
~$ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local (// 解压到/usr/local目录下);
~$ sudo chown -R hadoop /usr/local/hadoop (//修改权限);
首次启动Master节点需要格式化NameNode,之后就不需要了:
~$ hadfs namenode -format
(8)hadoop启动:~$ start-all.sh

7. scala-2.11.7的下载、安装和配置见:
http://blog.csdn.net/weixin_36394852/article/details/75948991
二: Spark集群配置
1. Spakr下载与安装
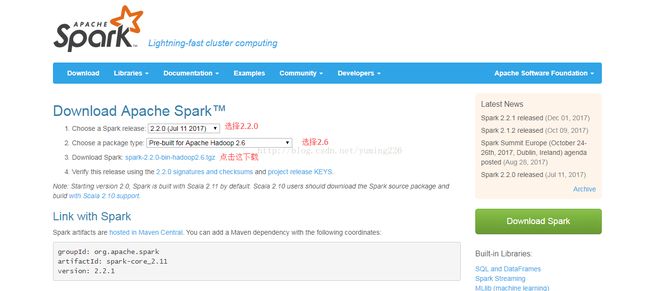
(1) 将spark压缩包解压并把文件夹重名为spark可参考hadoop这部分的操作(spark的路径为/usr/local/spark)

(2)spark环境变量进行配置如下红方框内部分:
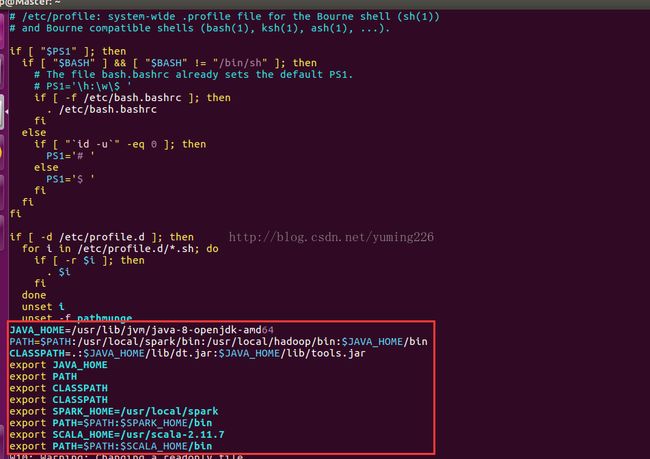
(3) 配置spark-env.sh和slaves
首先进入:/usr/local/spark/conf 如下:

需要将:spark-env.sh.template修改为spark-env.sh:
配置如下:
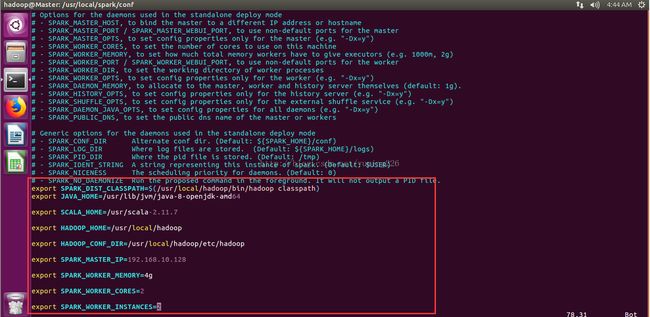
修改slaves如下:
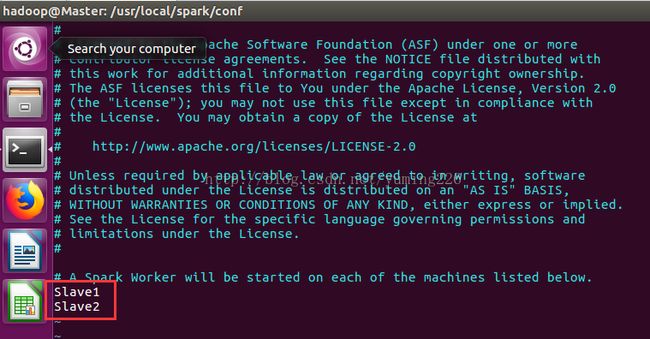
(4) 将配置同步到从节点:
(1) rsync -av /usr/local/spark/ Slave1:/usr/local/spark/
(2) rsync -av /usr/local/spark/ Slave2:/usr/local/spark/
2. 启动spark集群
(1) 启动hadoop集群:~$ start-all.sh
(2) 启动spark集群:

(3) 启动成功的标志:

如果你做到了这里而且得到了上述的结果那么就恭喜你,你的spark集群搭建成功了。
参考连接:
(1) hadoop集群单机安装: http://www.powerxing.com/install-hadoop/
(2) hadoop集群配置: http://www.powerxing.com/install-hadoop-cluster/
(3) spark集群配置: http://blog.csdn.net/weixin_36394852/article/details/76030317