seq2seq+attention入门
前言
本来是要了解attention模型,因为我自己的毕设主要在做分类,借此机会了解一下attention模型,其实之前实习的时候有用过seq2seq模型,现在在博客中补上记录。
1. seq2seq
1.简介
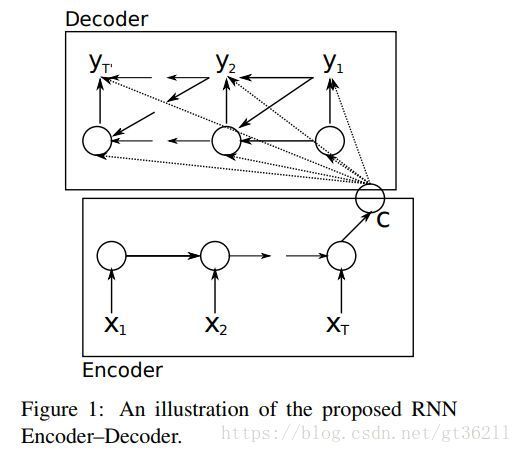
seq2seq的介绍基本都是如下这张图,这种结构首先就是为了解决输出也是一个序列的问题。比如机器翻译,文本摘要等,它们输入的是一段序列,输出的同样也是序列,所以采用了这种encoder+decoder的结构,基本方法就是将输入通过encoder层编码,再进入decoder层解码,每一个时间步预测一个单词。
图虽然看上去很简单,但有些实现起来要注意的地方如果现在不说就会像我刚学的时候那样感觉云里雾里的。
1.首先,图中的c是encoder的最后一个状态,将c看做是整个语句的编码。将这个编码输入decoder的方法,就是让decoder的初始hidden状态为c。平时在用rnn的时候没有设过初始状态,其实初始状态默认是0,是可以设为其他值的。
2.其次从下图我们可以看到,decoder的预测也作为了decoder的输入。这也可以理解,预测的时候我要看一看前面生成的是什么再做判断。后面还会介绍到很多种五花八门的decoder。但是问题是,第一个输入是什么,我预测到什么时候结尾。其实我们decoder的词表多了两个标签,除了词表以外,还有一个开始标签
3.还有一点是实现时让我当时费解的,这个decoder是怎么让它变长预测,还能把上一时间预测的标签放到下一时间的输入。其实很好做,将decoder的时间步设为1,写个循环就可以了。
2.分类
之前说过,decoder的部分有许多方法,encoder的部分大同小异。但是无论是encoder还是decoder,rnn都不是必须的,例如Facebook的fairseq用的是卷积神经网络,我之前做的文本摘要改自Google的attention,里面只用了attention模型。但是这两种没有用rnn,所以失去了词与词之间的序列关系,所以加入了一个位置编码。抛开模型的改动不谈,seq2seq主要有以下几种:
1.
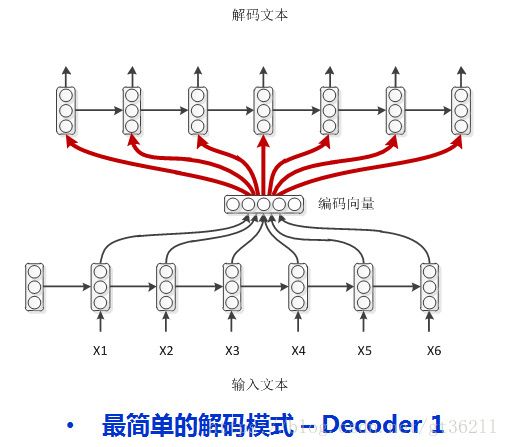
最简单的decoder方式,encoder编码后的编码向量每一步都输入给decoder,注意这时decoder里不需要开始标签了,因为每一步都输入的是编码向量
2.在介绍上面时我们说了,decoder也是一个rnn的结构,那么理所当然会想到用上一时刻的输出来帮助自己预测。注意这里虽然图中画的编码向量指向了decoder的第一时刻输入,但是并不是输入,encoder的编码赋值给了decoder的初始hidden。而decoder的初始标签是
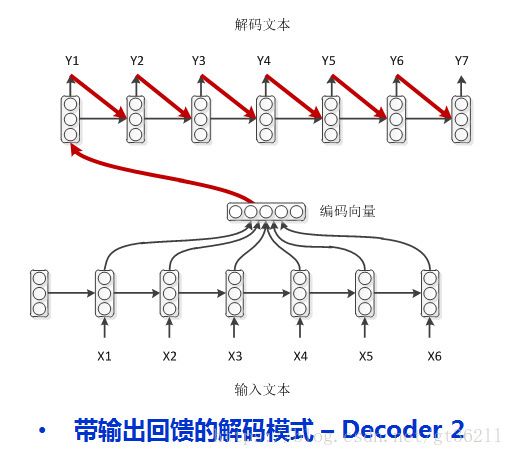
3.这种就更复杂了,可以说是综合了前两种的形式,decoder每一时刻的输入不仅有来自encoder的编码向量,还有上一时刻的输出,同时还有上一时刻的hidden,把能用的信息都用上了
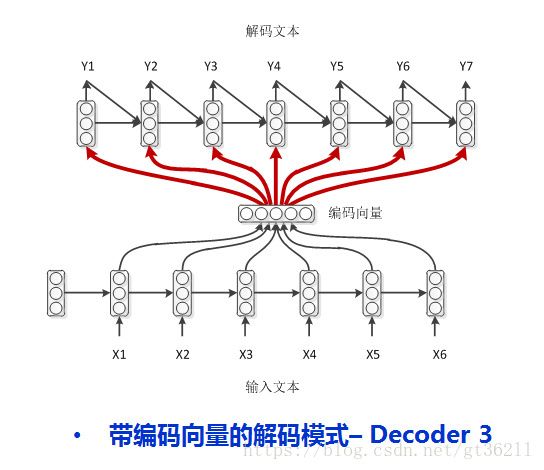
4.终于到了我想要介绍的attention机制了,attention在下面会介绍,这里简单说一下。encoder的rnn每一步都有一个输出的吧,之前我们要么用的是rnn最后一步的hidden,要么将encoder每一步的输出求和加成一个向量。现在我们给每一个output一个权重,最后计算带权求和的向量,好处就是每预测一个词都和原文本的部分最相关,这点在分类中也可以用到,之后会开一篇来介绍。

2. Attention
参考:https://zhuanlan.zhihu.com/p/31547842
attention的来历和效果这里就不再赘述了,主要说一下我实现的时候遇到的一些困难和问题。
1. 首先attention是一个权重向量,那么它是通过什么来生成的呢。attention权重的生成可以说是五花八门了,因为目的就是生成一个和为1的权重向量。比如源语料是10个字,embedding维度为128,那么encoder的output就是(10,28)维的(这里先不考虑batch维),我的attention权重就是(10,1)的十个和为1的数。生成权重主要用当前时刻dcoder的hidden和encoder的outputs来生成权重,生成权重的方式有dot,general和concat,下面给出一段代码来解释:
class Attn(nn.Module):
def __init__(self, method, hidden_size):
super(Attn, self).__init__()
self.method = method
self.hidden_size = hidden_size
if self.method == 'general':
self.attn = nn.Linear(self.hidden_size, hidden_size)
elif self.method == 'concat':
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
self.other = nn.Parameter(torch.FloatTensor(1, hidden_size))
def forward(self, hidden, encoder_outputs):
seq_len = len(encoder_outputs)
# Create variable to store attention energies
attn_energies = Variable(torch.zeros(seq_len)) # B x 1 x S
if USE_CUDA: attn_energies = attn_energies.cuda()
# Calculate energies for each encoder output
for i in range(seq_len):
attn_energies[i] = self.score(hidden, encoder_outputs[i])
# Normalize energies to weights in range 0 to 1, resize to 1 x 1 x seq_len
print(attn_energies)
return F.softmax(attn_energies,dim=0).unsqueeze(0).unsqueeze(0)
def score(self, hidden, encoder_output):
if self.method == 'dot':
energy = hidden.dot(encoder_output)
return energy
elif self.method == 'general':
energy = self.attn(encoder_output)
energy = torch.dot(hidden.view(-1),energy.view(-1))
return energy
elif self.method == 'concat':
energy = self.attn(torch.cat((hidden, encoder_output), 1))
energy = self.other.dot(energy)
return energy
class AttnDecoderRNN(nn.Module):
def __init__(self, attn_model, hidden_size, output_size, n_layers=1, dropout_p=0.1):
super(AttnDecoderRNN, self).__init__()
# Keep parameters for reference
self.attn_model = attn_model
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout_p = dropout_p
# Define layers
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size * 2, hidden_size, n_layers, dropout=dropout_p)
self.out = nn.Linear(hidden_size * 2, output_size)
# Choose attention model
if attn_model != 'none':
self.attn = Attn(attn_model, hidden_size)
def forward(self, word_input, last_context, last_hidden, encoder_outputs):
# Note: we run this one step at a time
# Get the embedding of the current input word (last output word)
word_embedded = self.embedding(word_input).view(1, 1, -1) # S=1 x B x N
# Combine embedded input word and last context, run through RNN
rnn_input = torch.cat((word_embedded, last_context.unsqueeze(0)), 2)
rnn_output, hidden = self.gru(rnn_input, last_hidden)
# Calculate attention from current RNN state and all encoder outputs; apply to encoder outputs
# 这里计算attention权重的时候并不是用的decoder上一时刻的hidden,而是用一个gru将last_hidden和这一时刻decoder的输入连接起来取其output来计算的
attn_weights = self.attn(rnn_output.squeeze(0), encoder_outputs)
context = attn_weights.bmm(encoder_outputs.transpose(0, 1)) # B x 1 x N
# Final output layer (next word prediction) using the RNN hidden state and context vector
rnn_output = rnn_output.squeeze(0) # S=1 x B x N -> B x N
context = context.squeeze(1) # B x S=1 x N -> B x N
output = F.log_softmax(self.out(torch.cat((rnn_output, context), 1)))
# Return final output, hidden state, and attention weights (for visualization)
return output, context, hidden, attn_weightsattention的多样性在这里就能体现出来了,看上面的示例代码,AttnDecoderRNN中计算attention的输入是last_hidden和rnn_input的结合。而在Attn类中,生成权重值的score函数有三种方式,dot就是简单的hidden*encoder_outputs,注意这里是用的dot点乘,就是对应位置元素相乘再求和,所以两个向量点乘的结果是一个数。general将encoder output用一个全连接编码后再和hidden点乘。concat是将hidden和outputs连接后再点乘一个随机生成的向量,看上去好像不合常识,但是这个随机生成的向量只是为了将连接的向量映射成一个数字。总之attention的score函数是非常灵活的,最后能生成权重就可以的。
attention种类
这里再多说一下attention的种类,attention分为soft和hard。soft就像上面那样,所有的encoder outputs都参与了运算。hard attention就是随机采样一些outputs来做attention。
还有global和local之分。global也是所有encoder outputs参与运算。local是根据当前decoder的输入词在encoder中估计出一个位置来,可以看做是soft和hard的结合。
此外还有与众不同的self attention,这个留到之后和attention用于分类一起介绍。