模拟浏览器爬虫
模拟流浪器爬取近义词,并通过BeautifulSoup 和正则将近义词解析出来
import urllib.parse
import urllib.request
from bs4 import BeautifulSoup as bs
url = 'http://jinyici.xpcha.com/'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36'
values = { 'q' : '招供', 'button' : '查询' }
headers = { 'User-Agent' : user_agent }
data = urllib.parse.urlencode(values).encode("utf-8")
req = urllib.request.Request(url, data, headers)
response = urllib.request.urlopen(req)
the_page = response.read()
#print(the_page.decode("utf8"))
content = bs(the_page)
#soup.findAll(name="div", attrs={"class" :"abcd"}
for link in content.find_all('span'):
res = re.sub("[A-Za-z0-9\!\%\[\]\,\。\<\>\(\)\:\=\"\.\_\/\:\-\;\#]", "", str(link))
print(res)
网页查询的结果
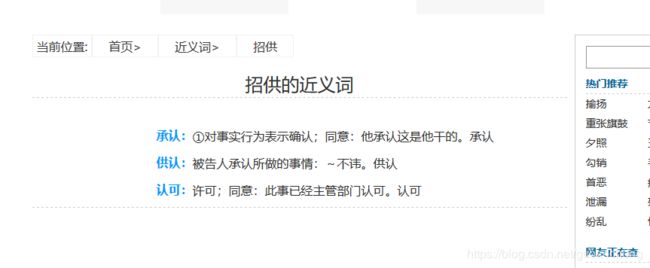
解析后的结果
