k8s架构以及相关概念普及
k8s架构以及相关概念普及
- 为什么要使用k8s
- 了解openstack
- 了解docker
- k8s存在的意义
- k8s的架构解析
- 基本概念
- Master节点组成详解
- Node节点组成详解
- 命令运行流程
为什么要使用k8s
了解openstack
在k8s和容器docker出来之前,最火的技术莫过于开源云平台openstack了,那么openstack做了什么事情呢?利用虚拟化技术实现资源的弹性使用,如果你是做开发的,你肯定知道数据库连接池,谁需要谁就拿走连接,用完了就换回去。同理,云平台无非就是把计算、存储、网络这三种资源进行了池化,进而希望达到弹性使用的目的。(弹性就是想啥时要都有,想要多少都行)。
openstack实际上就是利用虚拟化技术(例如KVM)等对服务器集群进行管理,管理的目标就是要达到两个方面的灵活性。哪两个方面呢?比如有个人需要一台很小很小的电脑,只有一个CPU,1G内存,10G的硬盘,一兆的带宽,你能给他吗?像这种这么小规格的电脑,现在随便一个笔记本电脑都比这个配置强了,家里随便拉一个宽带都要100M。然而如果去一个云计算的平台上,他要想要这个资源的时候,只要一点就有了。
所以说它就能达到两个方面灵活性:
- 第一个方面就是想什么时候要就什么时候要,比如需要的时候一点就出来了,这个叫做时间灵活性。
- 第二个方面就是想要多少呢就有多少,比如需要一个很小很小的电脑,可以满足,比如需要一个特别大的空间,以云盘为例,似乎云盘给每个人分配的空间动不动就就很大很大,随时上传随时有空间,永远用不完,这个叫做空间灵活性。
空间灵活性和时间灵活性,就是常说的云计算的弹性。
全部内容可以参考另一篇博客:为什么需要云计算
了解docker
首先,云计算是为了解决计算、网络、存储这三种资源的弹性问题,但是它遗留了两个问题:
- 应用的扩展问题。例如我开发一个电商应用,平时的时候10台机器能扛的住,双十一的时候需要100台才能抗的住。那怎么办?云计算平台可以实现一点90台新机器就出来了,但是机器是空的啊,上面什么应用都没安装,还需要人工登到每台机器上去一台一台的部署,非常麻烦。
- 迁移性问题。软件往往是需要不断的在不同的环境里面安装的,例如开发人员自己会安装一套,测试人员会安装一套,线上环境也会安装一套。然而软件的安装是非常复杂的,牵扯到权限问题,配置问题,文件路径问题等,一不小心就会出错,出错了软件的行为就不对了,你上网买东西,用银行支付都可能出错,造成大麻烦。
鉴于以上的两种问题,有人提出了比KVM更加轻量级的虚拟化技术,希望能够解决上述的问题:
- 应用的弹性扩展
- 应用的迁移
docker被人拿到台面上来,docker主要依赖于两个技术,分别是cgroup和namespace,这两个技术保证了容器的隔离性。
docker和KVM的对比:
- 容器撇下os。容器里面是不安装操作系统的,因为一个操作系统就很大了,并且os的运行也是非常占用系统资源的,容器与宿主机共用一个内核,容器之间的迁移不带内核。
- 容器撇下应用运行产生的本地数据。这些数据如果在容器里面,容器会变得很大,影响容器在不同环境之间的迁移。不同的环境指的是开发、测试、运维上线这几种环境的不同。这些数据在不同的环境是没有意义的,因此这些数据一般放在容器之外的设备上。
- 所有容器都是与宿主机共用内核的,容器与容器之间的隔离性就会差很多。而虚拟机的隔离性就要好很多,虚拟机运转依靠的是虚拟化技术模拟出了cpu,内存,硬盘,网络等。而容器都是使用宿主机的。
- 容器里面是不存放数据的,容器里面的数据会随着容器的生命周期而消失,如果想要持久化的存储,必须要依靠外部的存储设备。
详情参考:为什么需要容器
k8s存在的意义
docker如果一直跑单机,自然不需要k8s。可是万一你想在一个集群中跑k8s呢?那你就不得不面对两个问题:
- 跨主机的容器之间的通信问题
- 容器的调度和管理问题(编排)
k8s的发展就依赖于这股全民皆容器的浪潮当中,k8s是容器的编排工具,所谓编排,就是对容器进行管理,从端口暴露到外网,负载均衡,服务注册与发现,应用的编排与弹性伸缩,滚动更新,灰度发布等等。这些内容都交由k8s去实现。
同时,k8s可以说是最好的微服务载体,把一个非常大的单体应用分解为很多小的互相连接的微服务,一个微服务副本后面可能需要多个实例的支撑。副本的数量可以根据系统的负载进行动态的调整,每个微服务独立开发,升级,扩展。最后,k8s具有非常强大的横向扩展能力,这个能力能够帮助企业从几个结点的集群,平滑的扩展到几百个结点的集群,大大增强了系统的弹性。
k8s的架构解析
基本概念
- pod
Pod是Kubernetes创建或部署的最小/最简单的基本单位,一个Pod代表集群上正在运行的一个进程。一个pod里面可以包含多个容器。这多个容器共享Pod的ip地址。
一个Pod封装一个应用容器(也可以有多个容器),存储资源、一个独立的网络IP以及管理控制容器运行方式的策略选项。Pod代表部署的一个单位:Kubernetes中单个应用的实例,它可能由单个容器或多个容器共享组成的资源。
- label
label是k8s中的键值对,用户可以自己设定key和value。某一个对象可以有多个label,同一个lable也可以打给多个对象。因此,通过选择label,就能够选择一组合适的资源对象。当所有的资源都有了label之后,使用label selector就相当于在数据库当中使用where语句,最终能够得到一组相同label的资源。
k8s集群有两种集群角色,一种是Master,一种是Node,Master相当于大脑,控制着整个集群的运转,Node是k8s完成实际工作的节点。
Master节点组成详解
Master节点主要有以下几个组件:
- kube-apiserver:
API Server提供HTTP/HTTPS RESTful API,即Kubernetes API。 API Server是Kubernetes Cluster的前端接口,各种客户端工具(CLI或 UI)以及Kubernetes其他组件可以通过它管理Cluster的各种资源。
- kube-scheduler:
Scheduler负责决定将Pod放在哪个Node上运行。Scheduler在调度 时会充分考虑Cluster的拓扑结构,当前各个节点的负载,以及应用对 高可用、性能、数据亲和性的需求。是一个内部的调度器。
- kube-controller-manager:
Controller Manager负责管理Cluster各种资源,相当于所有资源的控制中心,保证资源处于预期 的状态。Controller Manager由多种controller组成,包括replication controller、endpoints controller、namespace controller、serviceaccounts controller等。
- etcd:
etcd负责保存Kubernetes Cluster的配置信息和各种资源的状态信息。当数据发生变化时,etcd会快速地通知Kubernetes相关组件。相当于一个配置中心,里面包含了所有组件的配置文件。
- Pod网络:
Pod要能够相互通信,Kubernetes Cluster必须部署Pod网络, flannel是其中一个可选方案。calico也是一种网络方案。二者的区别主要在于,flannel是二层overlay网络,而calico是路由转发网络。

整个Master结点的运作过程如上图所示。
- 由API Serve对外提供接口,使得用户能够对所有的资源进行增删改查,也是控制集群的唯一入口。
- Scheduler负责调度任务到哪一个结点上执行。
- Controller则用来控制和管理集群中的所有结点上的资源。
- etcd就是配置中心,里面包含了所有对象的配置文件(k8s中常见的资源的配置都在这里面存放)。
Node节点组成详解
Node节点上一般会运行以下进程:
- kubelet:
kubelet是Node的agent,当Scheduler确定在某个Node上运行Pod 后,会将Pod的具体配置信息(image、volume等)发送给该节点的 kubelet,kubelet根据这些信息创建和运行容器,并向Master报告运行 状态
- kubeproxy:
service在逻辑上代表了后端的多个Pod,外界通过service访问 Pod。service接收到的请求是如何转发到Pod的呢?这就是kube-proxy 要完成的工作.每个Node都会运行kube-proxy服务,它负责将访问service的 TCP/UPD数据流转发到后端的容器。如果有多个副本,kube-proxy会 实现负载均衡.
- Pod网络:
Pod要能够相互通信,Kubernetes Cluster必须部署Pod网络, flannel是其中一个可选方案(二层overlay网络)。calico也是其中一个方案(依靠路由转发实现)

命令运行流程
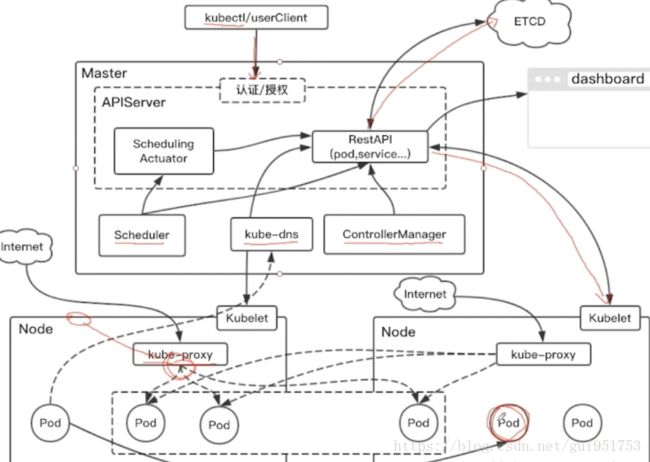
Master结点和Node结点实际的工作流程如上图所示:
- 1.kubectl发送部署请求到API Server
- 2.API Server通知Controller Manager创建一个deployment资源。
- 3.Scheduler执行调度任务,将要创建的任务按照一定的策略调度到相关结点上。
- 4.Node结点上的kubelet负责接收调度任务,通过kubelet在各自的结点上接收并运行pod。
其中etcd会将应用的配置和当前的状态信息保存在etcd当中,当执行kubectl get xxx(某种资源)的时候可以读取etcd当中相关的信息。