Deep Learning (Yoshua Bengio, Ian Goodfellow, Aaron Courville) 翻译 Part 2 第6章
http://www.deeplearningbook.org/
第6章 Deep Feedforward Networks
Deep Feedforward Networks也被称为feedforward neural networks或multi-layer perceptrons(MLPs),是十分重要的深度学习模型。Feedforward Networks的目标是拟合一个函数f*,比如一个分类器,
y=f*(x)把输入x映射到类别y,Feedforward Networks定义一个映射函数y=f(x;Θ)然后让Θ学习以得到最好的函数拟合。
这种模型被称为feedforward因为要拟合的函数信息是从 x通过计算输出y 得到的,没有从输出的feedback,如果feedforward neural networks包括feedback连接,那么就会被称为recurrent neural networks(第十章会讲)
feedforward neural networks模型由 有向无环图(DAG) 来表示它由哪些函数组成,比如我们现在有三个函数f1,f2,f3,连接成一个链,来形成f(x)=f3(f2(f1(x))),这种链式结构是最普遍应用的神经网络,在这个例子里,f1被称为网络的第一层,f2被称为网络的第二层,类推。这个链一共的层数就是这个模型的深度,这导致了 深度学习 这个术语的诞生,这个feedforward networks的最后一层叫做输出层,在神经网络的训练中,我们使f(x)趋近于f*(x),训练数据的每个取样x有一个标签使y≈f*(x)。
中间的hidden layers的维数决定模型的宽度,与其把layer想象为 向量->向量的函数,我们更可以想象layer为由很多单元组成的来表示 向量->张量 的函数。最好认为feedforward networks是一个函数拟合机。
为了拓展线性模型不能表示x的非线性函数,我们可以把线性模型应用于x的转换输入Φ(x),这里Φ(x)是一个非线性转换,然后问题就归结于Φ是怎样的:
1,一种选择是我们选一个普遍的Φ,比如 基于RBF模型的无限维Φ,如果Φ有足够的维数,我们就能有足够的能力拟合训练集,但是对于测试集的表现很差。
2,另一种选择是我们人工写Φ,这样的话,需要人们对每个不同的任务要有不同的写法。
3,深度学习的策略是来让Φ学习,这样,我们有一个模型y=f(x,Θ,w)=Φ(x,Θ)^T w , 我们现在有一个参数Θ我们能通过很多函数让Θ学习,而参数w可以让Φ(x)映射为想要的结果,这是深度学习的一个例子,Φ就是那个hidden layer。 这样,我们在Φ(x,Θ)的表示中,找最优的Θ,我们可以使用很多类型的Φ(x,Θ),使它应用更加普遍。
feedforward networks介绍了hidden layer,这让我们需要选择激活函数,我们也需要设计网络的层数,各层具体如何连接,每层多少个单元,我们介绍back-propagation算法,来计算这个函数的梯度。
6.1 例子:learning XOR
XOR函数,即exclusive or是一个二元运算操作,x1和x2,只有在这两个数其中一个为1另一个为0的时候,输出是1,其他情况输出是0。
这个XOR函数也就是提供了这个我们要拟合的f*(x),我们的模型有一个函数y=f(x;Θ) ,我们的学习算法就是要改变Θ使f接近f*
在这个例子里,我们不会考虑统计上的事,我们只想让网络在这四个点输出正确的结果,X={ [0,0]^T , [0,1]^T , [1,0]^T , [1,1]^T }我们就用这四个点进行训练。
我们可以把这个问题用回归问题来解决,用一个 均方误差(MSE)损失函数 。我们以后会看到其他更合适的拟合二元操作的模型。

现在我们必须要选择我们的模型,设想我们选择了线性模型,也就是Θ由w和b组成,

我们通过解normal equations,得到了w=0以及b=1/2,这样这个线性模型就会全部输出1/2,为什么会这样?因为线性模型不能拟合XOR函数,
我们于是介绍一个非常简单的feedforward networks,有一层的hidden layer,这一层hidden layer有两个单元,
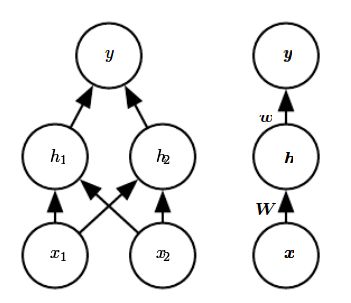

然后应用rectified linear unit(ReLU)作为激活函数



最后的结果就是我们想要的
6.2 Gradient-Based Learning
设计和训练一个神经网络和训练任意其他机器学习的模型区别不大,
线性模型和神经网络最大的不同在于神经网络的非线性会致使最有趣的loss函数变得非凸,这意味着神经网络通常使用迭代性的和基于梯度的优化器来训练,来使cost函数趋近于一个很低的值,(cost和loss是一个意思),而不是使用 解线性方程的方式来训练线性回归模型 或者 训练逻辑回归和SVM用的凸优化算法。凸优化算法可以从任意的初始值收敛(实践中很健壮,但会有数值问题)。随机梯度下降应用于非凸的loss函数,不一定会收敛,而且对初始值敏感。对于feedforward神经网络,把所有权值weight初始化为小的随机值很重要,偏移值biase被初始化为0或者小的正数,对于迭代性的基于梯度的优化算法 用于训练feedforward networks和几乎所有其他深度模型(8.4章会讲)。
对于机器学习模型,为了应用梯度下降我们必须选择一个cost函数,我们必须选择怎样去表示这个模型的输出,我们现在重新考虑一下。
6.2.1Cost 函数
深度神经网络设计的一个重要方面是cost函数的选择。
大多数情况,我们定义一个分布 p(y|x;Θ)以及我们简化最大似然的主体,这意味着我们使用训练数据和模型预测之间的cross-entropy(互熵)作为cost函数。
整个的训练神经网络的cost函数通常会结合主要的正则化的cost函数之一。
6.2.1.1 learning conditional distributions with Maximum Likeihood
大多数现代神经网络是用最大似然训练的,这意味者cost函数就是 负log-likelihood,也就是训练数据和模型分布之间的cross-熵,
这个cost函数我们给出

因为p不同,cost函数则不同。

神经网络设计的一个反复的主题是cost函数的梯度必须足够大,和足够可预测,来作为一个很好的学习算法的指导,负log-likelihood帮助了我们,即很多的输出单元包括一个exp函数,这个exp函数能够在参数是很负值的时候饱和,而log-likelihood的log函数会抵消输出单元的exp.
实践中,一个不经常的cross-熵cost的性质是会有一个大的最大的似然估计,而通常没有一个最小值。对于离散的输出变量,大多数模型不能表示0或1的概率,但是可以强行趋近。逻辑回归就是这样一个例子,对于实数值的输出变量,如果模型能够控制输出分布的密度,那么它就变得可以在高密度赋值给正确的训练数据输出,导致cross-熵接近无限负值,正则化技术可以避免无限制的反馈。
6.2.1.2 learning conditional statistics
与其训练一个全概率的分布p(y|x;Θ),我们更想仅仅训练一个条件统计的y,在输入为x时。
举例来说,我们有一个预测器f(x;Θ)想要预测y的平均值。
我们使用一个足够足够强大的神经网络,我们可以认为这个神经网络能够表示任何f,这样,我们可以把cost函数看作是一个functional而不是function,一个functional可以理解为把function映射为实数的映射,这样我们可以认为训练是选择一个函数而不是一些参数。解一个对于function的优化问题我们使用叫calculus of variations的数学工具,利用这个工具我们能够得到两个结果:
第一个结果:
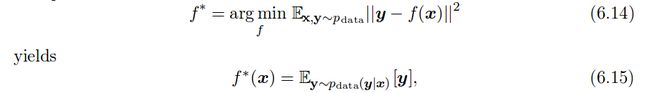
这样我们就能训练一个 从分布里生成取出无限多的样本数据 来最小化MSE cost函数,生成一个函数在每个x能够预测y的最小值
第二个结果:
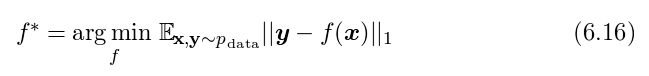
能够预测一个给定x下y的中间值,这个cost函数我们称为mean absolute error。
不幸的是,MSE和mean absolute error在用梯度优化时表现很差,这是一个cross-熵cost函数比 MSE或mean absolute error更流行的原因,即使预估一个全分布p(y|x)没有必要的时候。
6.2.2 Output Units
cost函数的选择和输出单元联系紧密,大多数时候,我们仅仅用 数据分布和模型分布之间的cross-熵,选择如何表示输出决定cross-熵function的样子。
任意类型的神经网络单元作为输出也能作为隐藏单元,在整个第六章我们设想feedforward network提供一组隐藏特征h=f(x;Θ)
6.2.2.1linear units for gaussian output distributions
给特征h,一层线性输出单元输出一个向量y^=W^T h + b
线性输出层也通常用于输出 条件高斯分布的平均值:

最大化log-likelihood就等同于最小化MSE。
最大似然 也让直接训练高斯协方差成为可能,或者让高斯协方差成为输入function,然而,协方差必须限制为对所有输入为正的矩阵,在线性输出层很难满足这样的限制,所以特别的,输出单元用来满足协方差的输入。
6.2.2.2 sigmoid units for bernoulli output distributions
很多任务要求预测y的一个二元取值,两种类别的分类属于此。
最大似然就是为了定义一个给定x下y的伯努力分布
伯努力分布被定义为仅仅是一个单一的数字,神经网络仅仅需要预测P(y=1|x)
设想我们使用一个线性单元,

这个确实定义了一个合格的条件分布,但是我们不能通过梯度下降很好的训练它,当wh+b出了取值范围的时候,输出的梯度就会为0,如果梯度为0那么就会是错误的,因为训练算法就没法得到改变参数的指导了。
换一种思路,我们就可以用sigmoid输出单元结合最大似然
一个sigmoid输出单元被定义为

这里σ是3.10章提到的sigmoid函数
我们可以把这个sigmoid输出单元看作有两个东西组成,一个是线性层,还有一个是sigmoid激活函数
6.2.2.3softmax units for multinoulli output distributions
multi-noulli和ber-noulli后面是一致的,任何时候我们想要表示一个n的可能值的离散概率分布,我们可能会用softmax函数,
softmax函数最通常被用来作为输出的分类器,很少情况softmax被用来在模型内部(非输出层)使用。
在binary变量,我们希望得到一个单个数字,因为这个数字需要是0或1,而因为我们想要这个数字的对数能够很好的进行log-似然的梯度优化。
为了能够产生一个n个值的离散变量,我们现在需要产生一个向量^y,
^yi=P(y=i|x),我们不仅要求y的每个元素在0和1之间,还要求y的所有元素之和为1,

我们希望能最大化log P(y=i;z)=log softmax(z)i
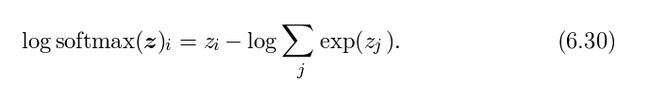
公式6.30右边的第一项表示输入zi总是有一个直接的贡献给cost函数,因为这一项不会saturate,即使zi对于第二项的贡献变得很小,在最大化log-likelihood的时候,第一项会促使zi上升,这时第二项会促使z向量的全部下降,为了得到一些直观的感觉对于第二项(那个求和式),log∑j exp(zj)可近似为max j zj ,这样近似 是基于其他exp(zk)对于max j zj 而言是很小的,这样我们可以直观感觉 -log-likelihood cost function总是会惩罚最不准确的预测,如果正确的答案已经有最大的输入给softmax,那么后面两项就会抵消。