Python练手爬虫系列No.1 知乎福利收藏夹图片批量下载
前言
学习总是要有动力的,我最开始学习爬虫也是看着崔大的爬虫新手系列Python爬虫学习系列教程-静觅,收获很大,但是除了爬爬糗百、百度文库,总得有些动力让你的学习变成一个主动行为吧。好吧,直接步入正题,常年混知乎,自然知道知乎已经是互联网的一大内容输出地了,至于什么内容就仁者见仁智者见智了。而包含的各种已经建立好的收藏夹则是种类丰富多彩。比如今天就用这个收藏夹来做一个图片爬虫吧~
说明一下,后面我写的爬虫都将主要使用python3的代码,毕竟要紧跟时代

分析结构
首先要说明的是,选择收藏夹而不是问题作为开始,是因为收藏夹的浏览不需要登录,比较简单,作为开篇还是比较合适的
我们的目的是抓取收藏夹内的图片,而收藏夹是以收藏夹-答案流-答案的形式组成的,所以爬虫肯定分为两部分。
- 第一步,自动翻页批量抓取收藏夹内所有的答案链接url
- 第二步,对答案url进行遍历,对每一个答案进行一次抓取,获得包含的所有图片url,并且将图片下载到本地
还是比较简单的,我们就直接开始吧。第一步自然是研究下网页结构

![]()
收藏夹的翻页完全可以通过发送url进行,那么我们就直接做实验
一、获取所有答案的链接URL
1.抓取网页源码
使用python自带的urllib.request库
import urllib.request
page = 1
root_url = 'https://www.zhihu.com/collection/52598162?page=' + str(page)
request = urllib.request.Request(root_url )
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')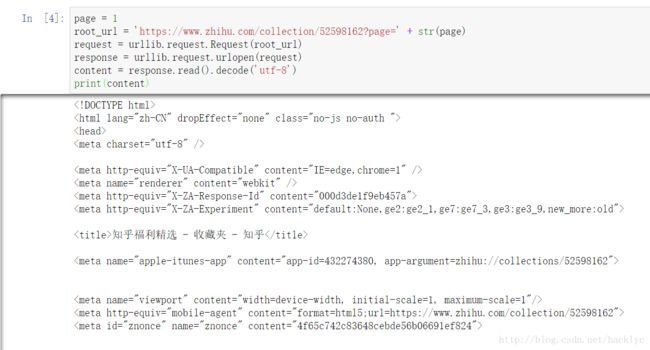
测试一下,可以看到,没有问题,直接获取了这一页的所有源码。
2.筛选源码内url数据
下面需要从源代码中抓取我们需要的url,url的状态是什么呢?

这时候我们就可以使用大名鼎鼎的美丽汤库了,beautifulsoup,可以按照结构来获取数据
from bs4 import Beautifulsoup
soup = BeautifulSoup(content, 'html.parser')
url_tems = soup.find_all('a', class_="toggle-expand")

可以看到,这里的url_tems并不是我们需要的数据,因此后面还需要通过.get(‘herf’)来得到url
url_sets = []
for url in url_tems:
full_url = urllib.request.urljoin('https://www.zhihu.com', url.get('href'))
url_sets.append(full_url)这样,我们就获得了完整的url信息。
3.获取收藏夹的最大页码
同时我们还需要获得最下面最大的页面页码才知道该需要抓取到什么时候。


我们可以通过获取这些数字,然后通过max函数取出最大值,代码见下方
page_soup = soup.find_all('a',href = re.compile(r'\?page=\d+'))
page_digit = set()
for page in page_soup:
test = page.get_text()
if test.isdigit():
page_digit.add(test)
max_page =int(max(page_digit))page.get_text()即找出来的所有文本,包含1,2,3,4,32,下一页。通过isdigit()判断,就能筛选出数字。在通过一个max()函数,就可以去的最大的数字。这样就能得到收藏夹的总页数。
4.组合在一起
这里前面的代码略,直接放循环抓取的部分
geturl()代指前面的代码
def geturls_set():
page = 1
urls_set = []
while True:
root_url = 'https://www.zhihu.com/collection/52598162?page=' + str(page)
urls = geturl(root_url)
urls_set.extend(urls)
if page == max_num:
break
page += 1
return urls_set二、抓取答案数据

打开一篇答案,查看源码,看到
data-original=”https://pic4.zhimg.com/v2-5b96b2cd9dc1b6a430b54e9e272a1acb_r.jpg”
正式我们想要的图片,于是乎,一闭眼一睁眼,代码写出来了
先用class定位,在用.get()提取属性
image_url_tem = soup.find_all('img', class_="origin_image zh-lightbox-thumb lazy")
for url_tem in image_url_tem:
image_urls.add(url_tem.get('data-original'))image_urls就是一篇文章所有的图片url(以列表形式保存)
三、下载图片
urllib.request.urlretrieve这个函数可以直接下载图片。一个循环,搞定~
def downloadPic(self,image_urls):
count = 1
path = os.getcwd()
os.makedirs(str(path)+'\\beauty')
for url in self.image_urls :
try:
urllib.request.urlretrieve(image_urls,str(path)+'\\beauty\\%s.png'%count)
except:
print("链接失效")
print("正在下载第%d张图片"%count)
count = count +1
print("已经下载完毕,共下载%d张图片"%count)
print("Enjoy it!")
JUST ENJOY IT!
四、组合代码
主要功能模块都已经放好了~
组合代码放在github上了,下载zhihu_favorite_img.py就可以使用了
https://github.com/hAcKlyc/zhihu_imagecrawler