机器学习算法:K近领学习笔记
在所有程序中可以找到jupyter notebook,如果jupyter notebook程序图标消失了,那么也可以在anaconda prompt中输入jupyter notebook启动jupyter notebook。
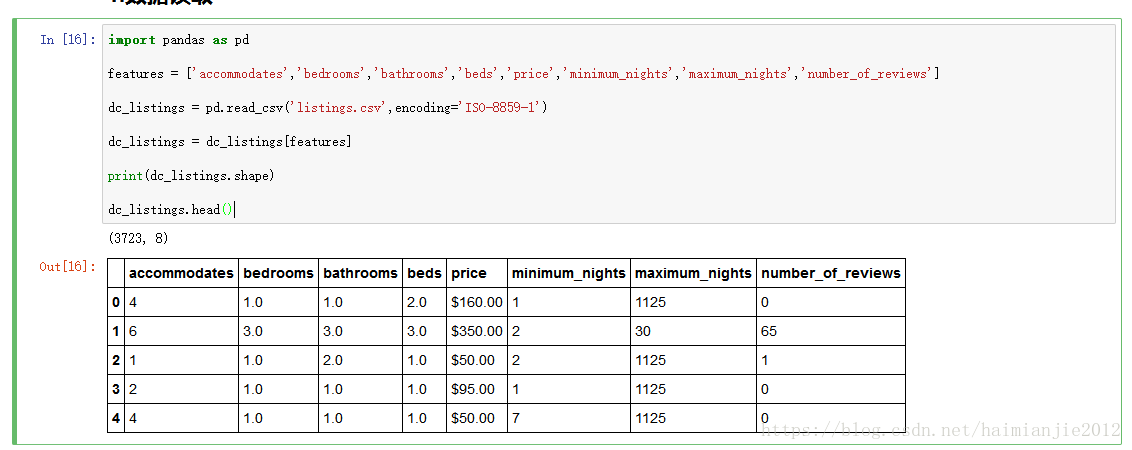
1.运用pandas读取数据
如图可以看到jupyter notebook的工作路径:C:\Users\randongmei201\,将listings.csv文件放在该文件加下,然后读取listings.csv文件
下面是pandas读取listings.csv文件的代码
import pandas as pd
features = ['accommodates','bedrooms','bathrooms','beds','price','minimum_nights','maximum_nights','number_of_reviews']
dc_listings = pd.read_csv('listings.csv',encoding='ISO-8859-1')
dc_listings = dc_listings[features]
print(dc_listings.shape)
dc_listings.head()运行效果:
注意:
如果pandas读取文件时不加编码格式,dc_listings = pd.read_csv('listings.csv'),可能会报错:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa1 in position 19: invalid start byte
或者说如果出现如上错误时,应该加上编码设置,
dc_listings = pd.read_csv('listings.csv',encoding='ISO-8859-1')
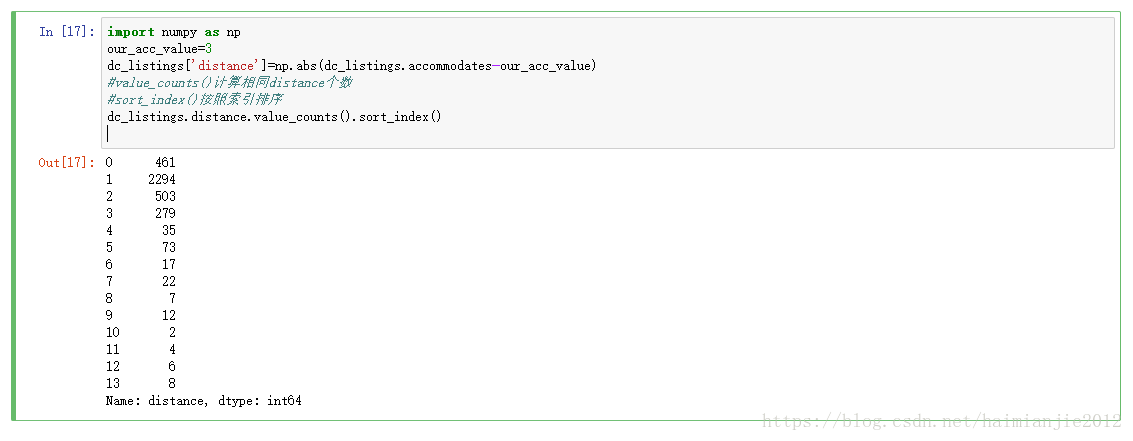
2.计算距离
import numpy as np
our_acc_value=3
dc_listings['distance']=np.abs(dc_listings.accommodates-our_acc_value)
#value_counts()计算相同distance个数
#sort_index()按照索引排序
dc_listings.distance.value_counts().sort_index()#value_counts()计算相同distance个数
#sort_index()按照索引排序
dc_listings.distance.value_counts().sort_index()
运行结果:
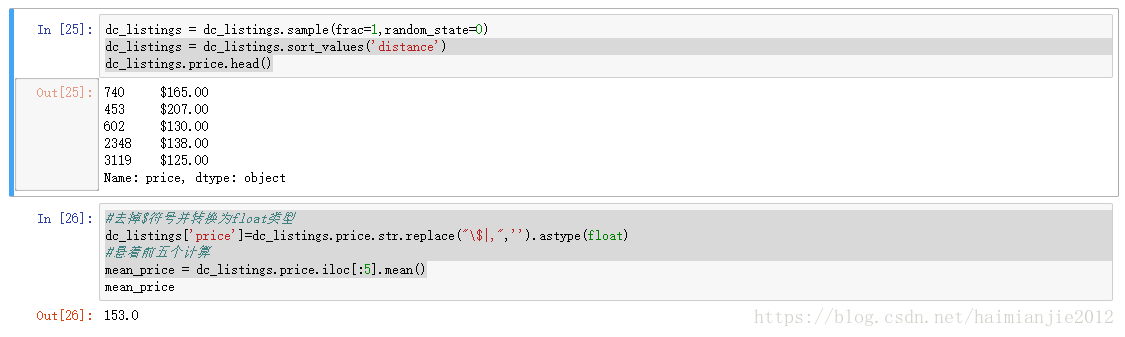
3.随机排序
当DataFrame中有n行m列数据,而我需要随机从中选取一部分时,可以使用DataFrame中的sample方法,进行随机选取 DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
n:表示你要随机抽取几行数据,比如你要抽取10行,n=10。不能与frac同时使用
frac:浮点型,可选。表示抽取数据的百分比,当不确定n的具体值的时候使用。不能与n同时使用
replace:布尔值,可选。原来的DataFrame是否被抽取的数据替换,默认为False.如果n取值大于原DataFrame的长度, replace为True,可返回结果。否则会因dataFrame长度不够而报错。
weights:权重,字符串或者数组格式,可选。通过设置不同的权重可以增加相应数据被选中的概率。
random_state:随机种子数
axis: 整数型或字符串,可选。可以是表示轴向的数据(0,1)或名称。当抽取数据的时候是从行中抽取数据,还是从列中抽取数 据。0表示纵向坐标轴,1表示横向坐标轴。
将dataframe中的数据重新洗牌:
dc_listings = dc_listings.sample(frac=1,random_state=0)按照distance字段排序,并显示前五个:
dc_listings = dc_listings.sort_values('distance')
dc_listings.price.head()
#去掉$符号并转换为float类型
dc_listings['price']=dc_listings.price.str.replace("\$|,",'').astype(float)
#悬着前五个计算
mean_price = dc_listings.price.iloc[:5].mean()
4.模型评估
4.1指定好训练集和测试集
#去掉一列
dc_listings.drop('distance',axis=1)
#前面2792行train,
train_df=dc_listings.copy().iloc[:2792]
test_df=dc_listings.copy().iloc[2792:2]
#去掉一列
dc_listings.drop('distance',axis=1)
#前面2792行train,
train_df=dc_listings.copy().iloc[:2792]
test_df=dc_listings.copy().iloc[2792:]4.2基于单变量预测价格
def predict_price(new_listing_value,feature_column):
temp_df=train_df
temp_df['distance']=np.abs(dc_listings[feature_column] - new_listing_value)
temp_df = temp_df.sort_value('distance')
knn_5 = temp_df.price.iloc[:5]
predicted_price = knn_5.mean()
return(predicted_price)对于dataframe的每个样本都运用predict_price函数
test_df['predicted_price']=test_df.accommodates.apply(predict_price,feature_column='accommodates')这样测试集中,所有的房子都有预测的价格了
计算预测值与真实值得均方根误差:
test_df['squared_error']=(test_df['predicted_price']-test_df['price'])**(2)
mse=test_df['squared_error'].mean()
rmse=mse ** (1/2)均方根误差越低越好
5.不同变量效果会不会不同呢
for feature in ['accommodates','bedrooms','bathrooms','number_of_reviews']:
test_df['predicted_price'] =
test_df[feature].apply(predict_price,feature_column=feature)
test_df['squared_error'] = (test_df['predicted_price'] - test_df['price'])**(2)
mse=test_df['squared_error'].mean()
rmse=mse ** (1/2)
print("RSME for the {} column:{}".format(feature,rmse))
6.综合利用所有的信息一起测试
数据预处理:标准化,归一化
如果某一列的值为空,那么去掉这一行数据:
dc_listings = dc_listings.dropna()
运用sklearn的标准化对数据进行标准化预处理:
dc_listings[features] = StandardScaler().fit_transform(dc_listings[features])
import pandas as pd
from sklearn.preprocessing import StandardScaler
features = ['accommodates','bedrooms','bathrooms','beds','price','minimum_nights','maximum_nights','number_of_reviews']
dc_listings = pd.read_csv('listings.csv',encoding='ISO-8859-1')
dc_listings = dc_listings[features]
dc_listings['price'] = dc_listings.price.str.replace("\$|,",'').astype(float)
dc_listings = dc_listings.dropna()
dc_listings[features]=StandardScaler().fit_transform(dc_listings[features])
normalized_listings =dc_listings
print(dc_listings.shape)
normalized_listings.head()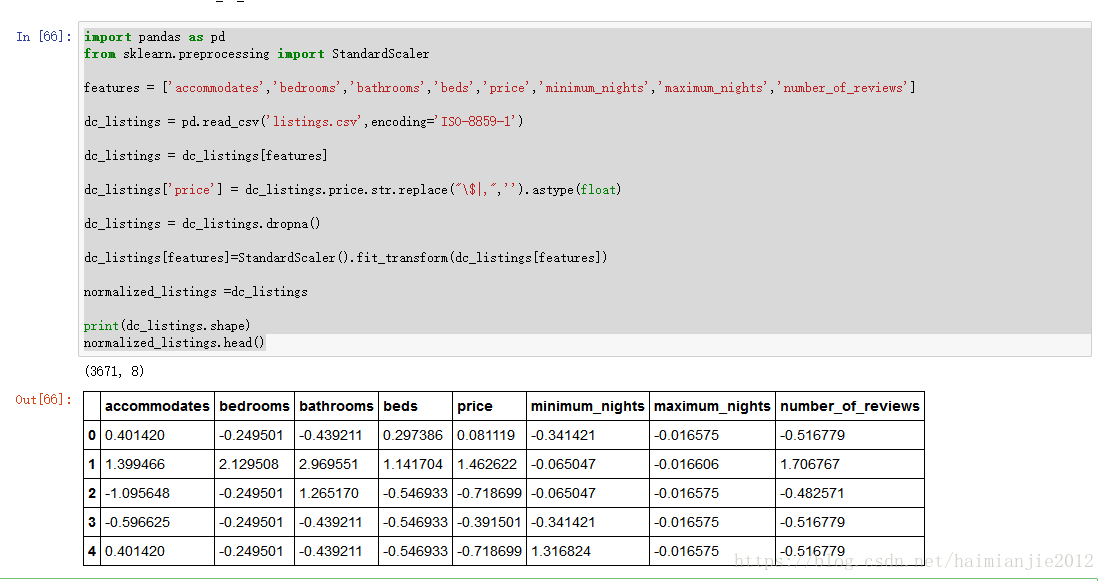
参考文献:
https://blog.csdn.net/weixin_41789707/article/details/80930274?utm_source=copy