Linux日常——shell工具之grep(包含正则表达式)、sed
grep行过滤器
grep是⼀种查找过滤⼯具
正则表达式在grep中⽤来查找符合模式的字符串。
egrep相当于grep -E,表⽰采⽤Extended正则表达式语法。
fgrep相当于grep - F,表⽰只搜索固定字符串⽽不搜索正则表达式模式,不会按正则表达式的语法解释后⾯的参数。
grep的正则表达式 有Basic和Extended两种规范,它们之间的区别下面有解释。
正则表达式
规定:⼀些特殊语法表⽰字符类、数量限定符和位置关系,然后⽤这些特殊语法和普通字符⼀起表⽰ ⼀个模式,这就是正则表达(RegularExpression)
字符类(Character Class):如上例的x和y,它们在模式中表⽰⼀个字符,但是取值范围是 ⼀类字符中的任意⼀个。
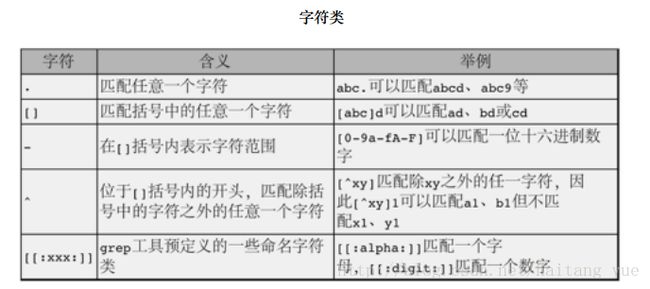
数量限定符(Quantifier): 邮件地址的每⼀部分可以有⼀个或多个x字符,地址的每⼀部分可以有1-3个y字符
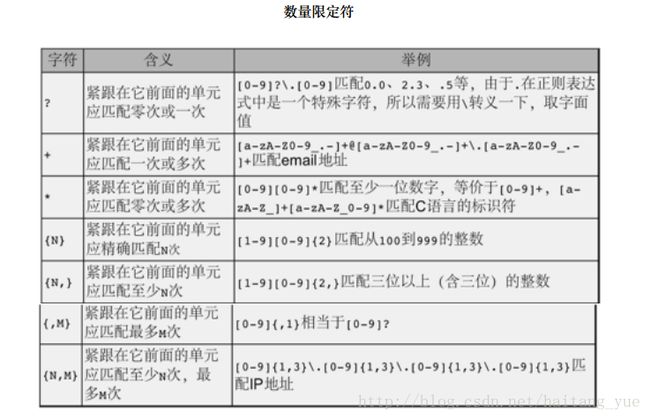
位置限定符(Anchor):描述各种字符类以及普通字符之间的位置关系,例如邮件地址分三部分,⽤普通字符@和.隔 开,IP地址分四部分,⽤.隔开,每⼀部分都可以⽤字符类和数量限定符描述。

正则表达式还有⼀个重要的应⽤是验证⽤户输⼊是否合法,例如⽤户通过⽹页表单提交⾃⼰的email 地址,就需要 ⽤程序验证⼀下是不是合法的email 地址,这个⼯作可以在⽹页的Javascript 中做,也可以在⽹站后台的程序中做,例如PHP、Perl、Python、Ruby、Java或C,所有这些语⾔都⽀持正则表达式,可 以说,⽬前不⽀持正则表达式的编程语⾔实在很少见。除了编程语⾔之外,很多UNIX 命令和⼯具 也都⽀持正则表达式,例如grep、vi、sed、awk、emacs等等。“正则表达式”就像“变量”⼀样,它 是⼀个⼴泛的概念,⽽不是某⼀种⼯具或编程语⾔的特性。
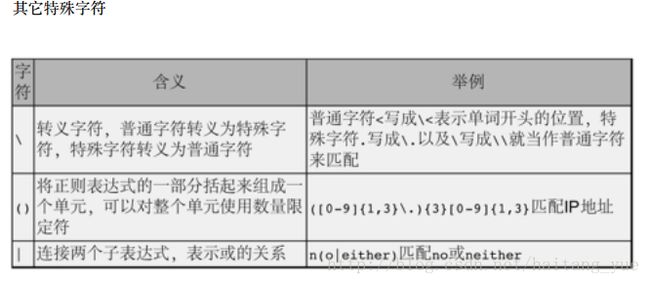
注意正则表达式参数⽤单引号括起来了,因为正则表达式中⽤到的很多特殊字符在Shell中也有特殊 含义(例如),只有⽤单引号括起来才能保证这些字符原封不动地传给grep命令,⽽不会被Shell解释掉。
规范:grep默认Basic规范
Basic与Extended的区别
Basic:? {} + | () 默认为普通字符,加 \ 转义为特殊字符
Extended:? {} + | () . 默认为特殊字符,加 \ 转义为普通字符、
所以:
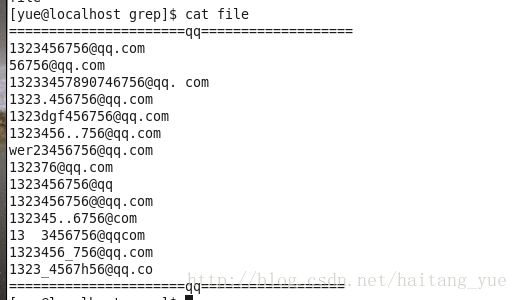
要求筛选出正确形式的QQ邮箱:
grep -E –color ‘[1-9][0-9]{5,12}@qq.com’
等价于:
grep -E –color ‘[1-9][0-9]{5,12}@qq.com’

实例
匹配电话号码
grep '^1[34578][0-9]{9}$' test.c匹配ip
grep '^[12][0-9]{0,2}(\.[0-9]{0,3}){3}$' test.c匹配163邮箱
grep '^[a-zA-Z0-9_]{1,}@163\.com$' test.csed—流式编辑器(Stream Editor)
- 功能:sed主要用来自动编辑一个或多个文件,简化对文件的反复操作
- 介绍:把前一个程序的输入引入sed的输入,经过一系列编辑命令转换为另一种格式输出,它处理的⽂件既可以由标准输⼊重定向得到,也可以当命令⾏参数传⼊,命令⾏参数可以⼀次传⼊多个⽂件,sed会依次处理。
- 格式: sed ‘/pattern/action’ filename
pattern–正则表达式
action–编辑操作 - 处理数据:如果某一行与pattern匹配,则执行对应的action,如果一条命令没有pattern只 有action,则这条命令的action将用于待处理文件的每一行。
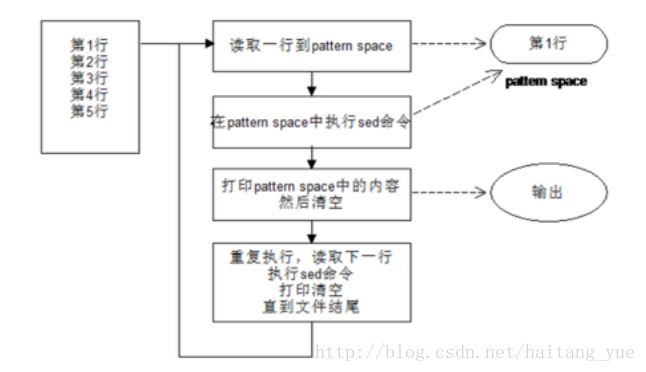
- sed是一种在线编辑器,按行处理文件。
- 模式空间(pattern space):处理时,把当前处理的行存储在临时缓冲区中,该缓冲区称为“模式空间”。
sed处理缓冲区的内容,最后将处理完成后的内容送往屏幕。接着处理下一行,不断重复直到文件末尾。
要注意,此时文件内容并没用改变, 除非使用了重定向存储输出或者使用了 -i 选项。 - 规范:sed默认Basic规范基本匹配
- 模式空间和保持空间
模式空间:可以想成⼯程⾥⾯的流⽔线,数据直接在它上⾯进⾏处理。进行正则匹配
保持空间:可以想象成仓库,我们在进⾏数据处理的时候,作为数据的暂存区域。
1.sed在正常模式下,将处理的行读入模式空间(在正常模式下,只使用模式空间)
2.模式空间,保持空间为两段缓冲区
3.数据处理只能在保持空间
4.只有在sed使用某些命令时才使用保持空间,命令括在‘ ’里
5.正常情况下,如果不显⽰使⽤某些⾼级命令,保持空间不会使⽤到。
文本处理处理过程
sed命令:
+ g:[address[,address]]g 将hold space中的内容拷⻉到pattern space中, 原来pattern space⾥的内容清除 //get
+ G:[address[,address]]G 将hold space中的内容append到pattern space\n后
+ h:[address[,address]]h 将pattern space中的内容拷⻉到hold space中, 原来的hold space⾥的内容被清除 //hold
+ H:[address[,address]]H 将pattern space中的内容append到hold space\n后
+ d:[address[,address]]d 删除pattern中的所有行,并读入下一新⾏到 pattern中 //delete
+ D:[address[,address]]D 删除multiline pattern中的第一行,不读入下一行⼀⾏
+ x:交换保持空间和模式空间的内容
+ n:将下一行读取到pattern space,覆盖 //next
+ N:将下一行读取到pattern space,追加 1.注释代码
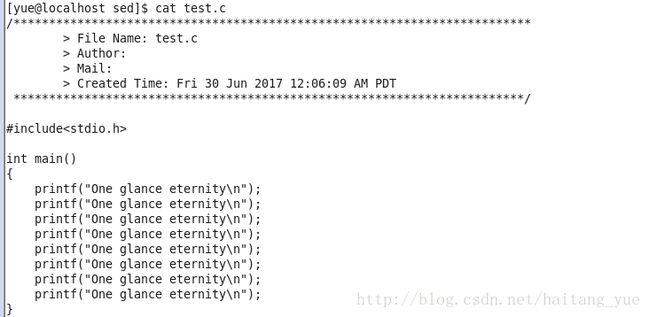
sed '/printf/s/^/\/\//g' test.c

但此时文件并没有改变,要加上-i选项
sed -i '/printf/s/^/\/\//g' test.c 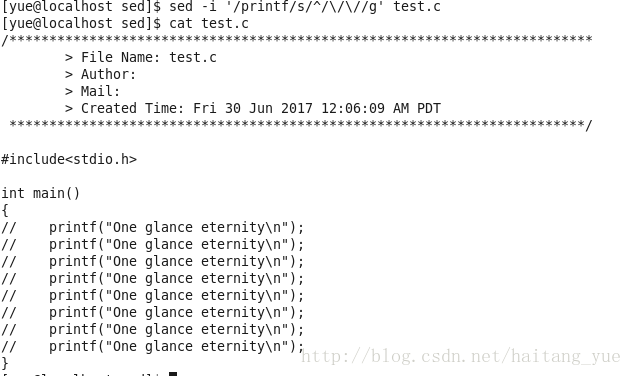
2.去注释
sed -i '/printf/s/\/\//g' test.c