目标检测分块知识总结 2
tags: 目标检测;
1. FSAF
论文题目《Feature Selective Anchor-Free Module for Single-Shot Object Detection》2019
文章主要解决在进行多尺度检测的时候,利用特征金字塔无法给目标分配确切的某一层特征层来进行检测,这个比较依赖经验,但是效果表现并不是很好。因此,这里在每一个特征层都使用了一种叫做anchor-free的模块,来使目标自动选择最合适的特征层进行预测,从而脱离事先定义anchor这个过程。
通常目标检测算法都会使用特征金字塔的方式进行多尺度检测。但是究竟每一层的特征该预测多大尺度的目标是一个难以断定的事情。比如有可能一个60*60大小的目标是在P1层检测,而50*50大小的目标和40*40大小的目标却都放在了P2层进行检测,这种不同尺度的检测框的定义是非常难以衡量的。所以这里作者提出了,直接让网络根据目标的内容自己决定在哪层进行检测,不需要干预。
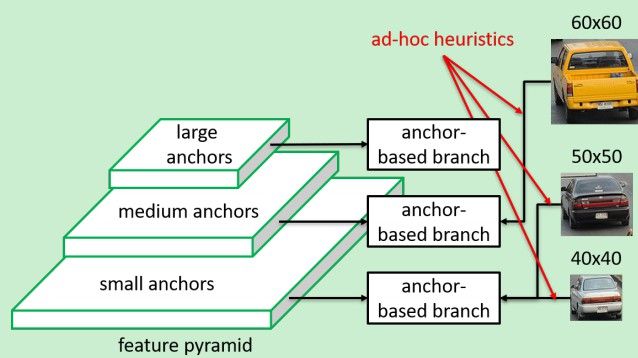
FASF模块定义
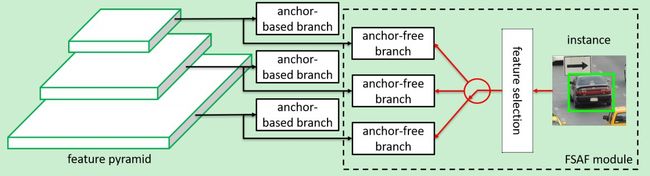
在训练的时候,基于目标的内容去自动选择某一个特征层进行检测,而不仅仅是根据目标的尺寸大小去选择。
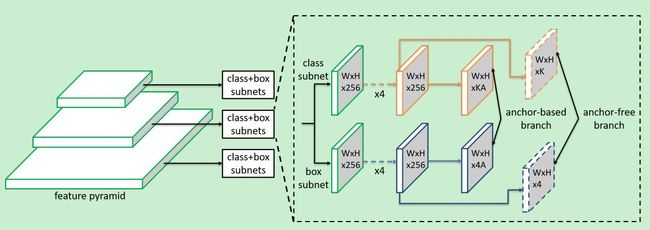
可以看到,FASF模块是在基于anchor的子网络上面引出来一支,用来进行anchor的判定。在原始的anchor-based分支上面,添加了anchor-free分支,这个分支是通过对特征图采用3*3*K的卷积核进行卷积的结果,然后采用sigmoid激活函数,最终得到的特征图W*H*K表示K个特征图对应K个类别,而每个特征图上的点表示该点属于该类别的概率。而W*H*4表示每个点都包含一个4维的坐标信息。
给定了一个图像的位置信息 b = [ x , y , w , h ] b=[x, y, w, h] b=[x,y,w,h], 那么其在 l l l次下采样之后,到达第P个特征层之后,位置信息会变成 b p l = [ x p l , y p l , w p l , h p l ] b_p^l=[x_p^l, y_p^l, w_p^l, h_p^l] bpl=[xpl,ypl,wpl,hpl],其中, b p l = b / 2 l b_p^l=b/2^l bpl=b/2l。定义有效区域 b e l = [ x e l , y e l , w e l , h e l ] b_e^l=[x_e^l, y_e^l, w_e^l, h_e^l] bel=[xel,yel,wel,hel]和忽略区域 b i l = [ x i l , y i l , w i l , h i l ] b_i^l=[x_i^l, y_i^l, w_i^l, h_i^l] bil=[xil,yil,wil,hil],这两个区域的大小是根据 b p l b_p^l bpl计算求得的,其缩放系数分别为 ϵ e \epsilon_e ϵe, ϵ i \epsilon_i ϵi。 x i l = x e l = x p l x_i^l=x_e^l=x_p^l xil=xel=xpl, y i l = y e l = y p l y_i^l=y_e^l=y_p^l yil=yel=ypl, w i l ϵ = w e l ϵ = w p l w_i^l\epsilon=w_e^l\epsilon=w_p^l wilϵ=welϵ=wpl, h i l ϵ = h e l ϵ = h p l h_i^l\epsilon=h_e^l\epsilon=h_p^l hilϵ=helϵ=hpl。也就是说中心点不变,长宽进行了缩放。
anchor-free模块的监督信息如下:
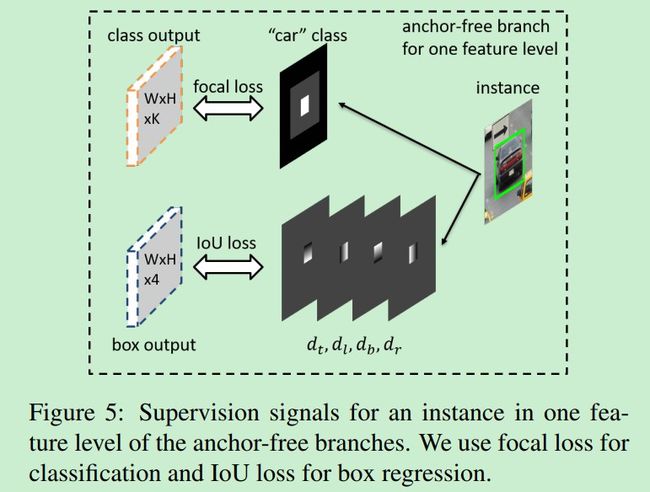
对于分类部分:有效区域为图中的白色区域,忽略区域为灰色中不包含白色部分,训练的时候,这部分梯度不进行回传。同时,如果灰色区域对应的相邻的特征图中的灰色区域也被视为忽视区域,不回传梯度。还有一点需要注意的是,如果有两个目标的有效区域在一个特征图上重叠了,那么该特征图倾向于预测两个目标中的小目标。剩下的黑色区域为负样本区域,表示不存在目标。训练的时候,使用focal loss去搜集所有除了忽视区域外所产生的损失。
对于回归部分:所产生的四个坐标是相对图像左上下右的距离,坐标经过归一化后映射回原图,但是如果某些坐标落到了灰色区域,那么这部分的梯度不会回传。这部分采用的损失为IOU 损失。
对于前向推测:当一个像素产生了结果 [ o t , o l , o b , o r ] [o_t, o_l, o_b,o_r] [ot,ol,ob,or],那么将其乘以归一化系数S为 [ S o t , S o l , S o b , S o r ] [So_t, So_l, So_b,So_r] [Sot,Sol,Sob,Sor],然后预测左上角为 [ i − S o t , j − S o l ] [i-So_t, j-So_l] [i−Sot,j−Sol],右下角为 [ i − S o b , j − S o r ] [i-So_b, j-So_r] [i−Sob,j−Sor]。然后乘以下采样系数 2 l 2^l 2l,映射回原图。
损失函数如下:
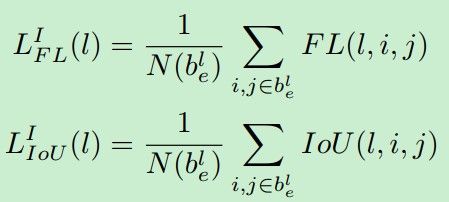
对于每个特征层,都是通过计算focal loss 和IOU loss,将两者结合起来一起优化。
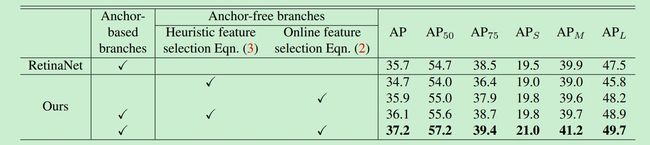
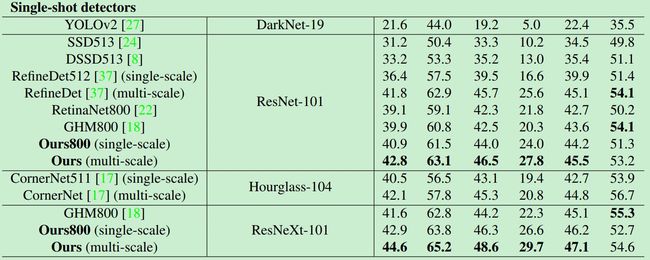
算法的结果如下:
2. DSSD
论文题目《DSSD: Deconvolutional Single Shot Detector》 2017
文章主要解决SSD中对于小目标检测时候缺乏语义信息导致检出率不够的问题。
大体上文章主要做了几方面工作:
- 使用了ResNet101代替原始SSD中的VGG网络,构成了类似SSD网络
- 在更改之后的网络后面增加了Deconvolution层,形成了hourglass的结构,用来进行检测
- 在进行检测的时候,增加了几个卷积层,可以提升准确率
- 对PASCAL VOC物体的纵横比进行了聚类,发现纵横比在1-3之间,所以在SSD中原始只使用2和3比例的特征层增加了1.6这个纵横比
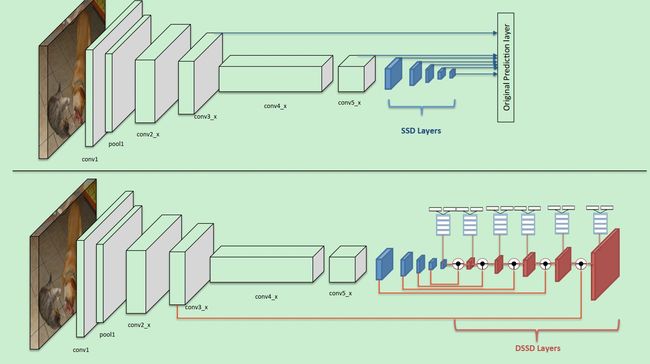
可以看到,DSSD在原始的SSD后面增加了几个反卷积层,主要在反卷积层进行预测,这部分内容综合了低层次的细节信息和高层次的语义信息。
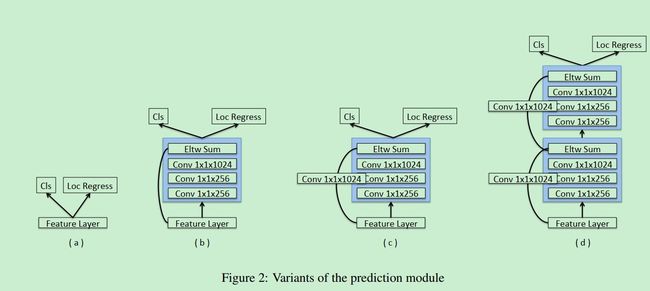
这里为了增加准确率,在进行预测的时候又添加了几个卷积层,最后进行预测。
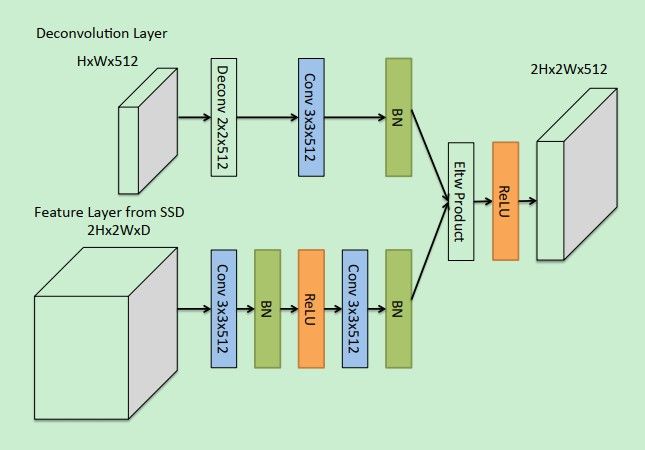
这部分内容就是DSSD中特征层的结合方式。可以看到,最终两层之间进行特征融合的时候使用了点乘,作者也尝试了相加,但是发现点乘的方式对于结果准确率的提升还是很有帮助的。
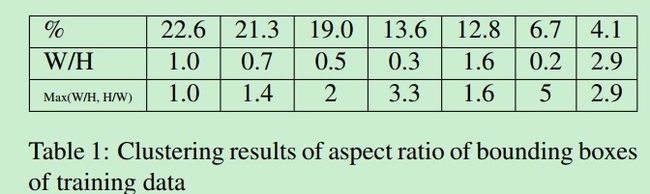
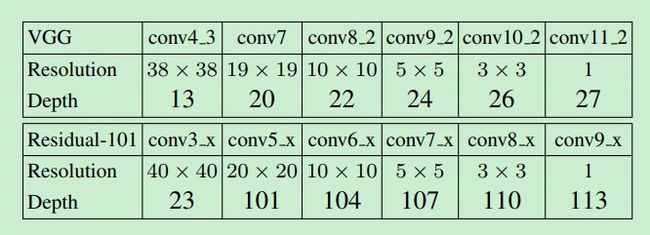

另外一点需要注意的是作者在测试的时候使用了一个技巧来大大减少前向推理时间:
在测试的时候,将bn层去掉,而使用训练好的参数scale和shift去直接进行参数操作
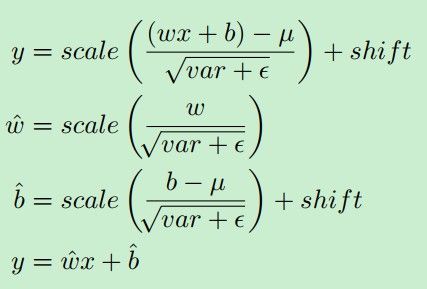
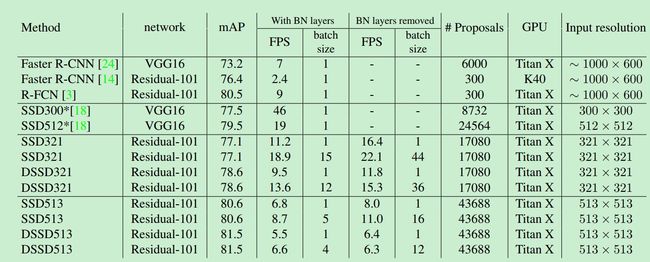
通过SSD和DSSD的对比,可以看出,去掉bn层之后,速度提高了很多。但是SSD比DSSD的速度要快好多倍。这点作者解释说是由于ResNet101的层数深,同时在预测的时候增加了反卷积和多个卷积层进行预测;而且DSSD所生成的anchor的数量是SSD的2倍之多,所以可能导致速度下降。这点可能会在后面的研究中想法搞定,反正精度还是不错的。
3. GIOU
论文题目《Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression》
本文主要解决的问题是:传统的L范数损失对于尺度不具有不变性,虽然IOU损失对于尺度具有不变性,但是又对坐标比较敏感。在进行坐标回归的时候,预测框与gt之间如果没有交集的时候,他们之间的IOU为0,这样的话,在计算loss的时候就会出现是0的情况,gt无法引导预测框调整方向。或者当预测框与gt之间的IOU相同,但是预测框形状可以是任意形状的时候,gt也无法引导预测框如何调整。
主要原因在于,现在在进行坐标回归的时候,所使用的损失函数一般是基于L范数的,但是在衡量框的准确性的时候,是基于IOU的,而这两者之间并没有很强的关联性,从而导致很多算法虽然能够通过训练,将L范数降低,但是无法提高最终的预测准确性。如果使用IOU损失,如何才能够让其不受坐标的影响是个问题。
如下图所示:
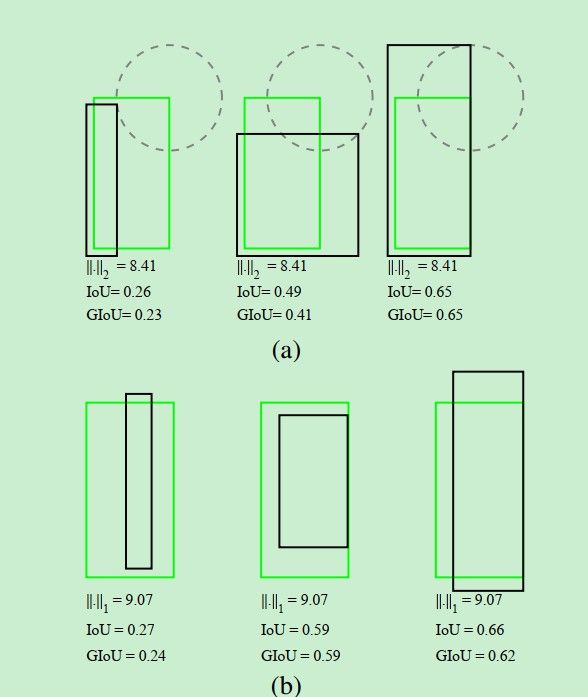
图中的绿色框为gt,黑色框为预测框,可以发现,只要预测框右上角在图中的虚圆圈上,那么他们之间的L范数就会相同,但是相同的L范数并不意味着IOU就相同。也就说明了,在优化L范数的时候,并不能直接体现在IOU上,也就是预测框的准确性上。所以这里作者进行了改进。
而且,在使用IOU衡量的时候,也无法体现预测框的准确性,比如下图:
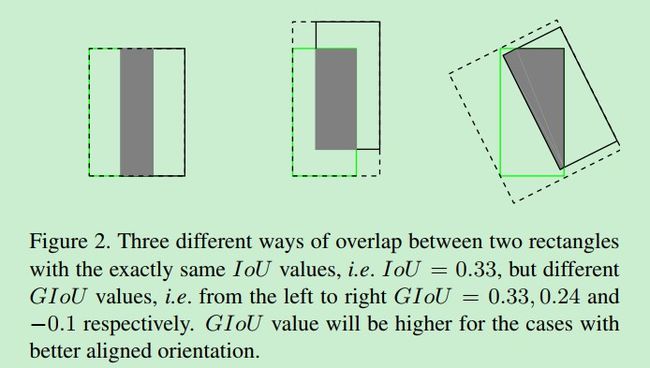
图中的IOU都是相同的,但是可以发现,两者之间的位置是不相同的,IOU本身不能够体现出来如何调整坐标位置才能够使得预测框更准确,所以有必要进行改进。
下图就是GIOU的算法原理与细节:


可以看到,作者的做法是首先计算预测框和gt之间的IOU,然后计算两者之间的一个最小的封闭集合,最终的GIOU是原始的IOU减去封闭集合去除两个框所占的面积后的归一化结果。说来有点太抽象,这里举个例子(根据算法2):
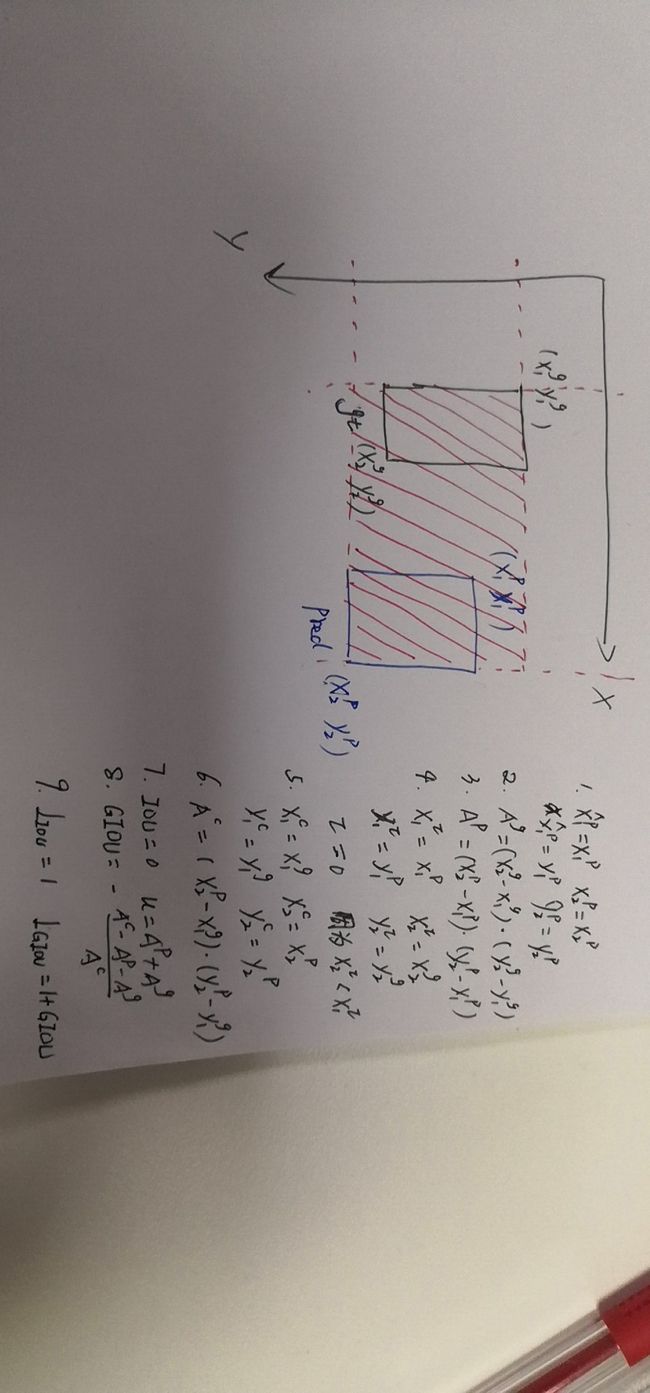
可以看到,所做的事情就是几个方面:
- 第四步,计算gt与预测框之间的IOU
- 第6步,计算最小封闭框的面积
- 计算IOU与GIOU
两者之间没有交集的时候,IOU是0,但是GIOU并非是0,所以可以继续优化。
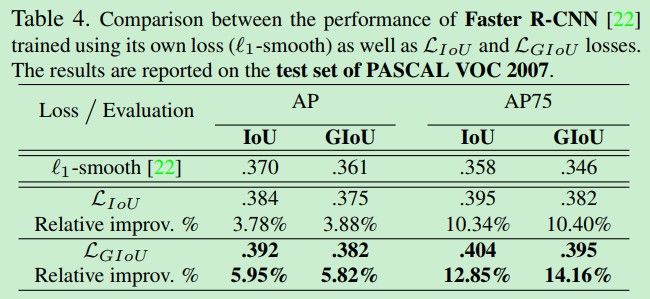
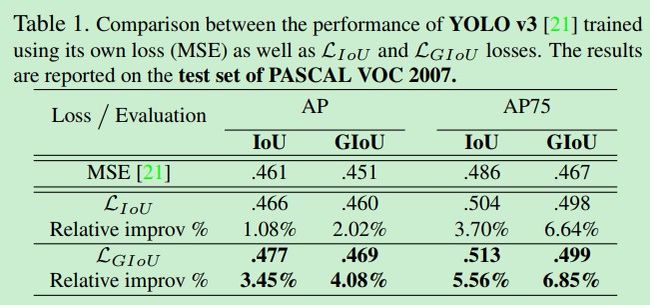
在各种数据集上的表现如下:
参考文献
- Feature Selective Anchor-Free Module for Single-Shot Object Detection
- DSSD: Deconvolutional Single Shot Detector
- Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression