如何将pytorch模型用于Tengine平台
如何将pytorch模型用于Tengine平台
- 0.Tengine介绍
- 1.Tengine 支持的OP
- 2.实施方案
- 2.1 pytorch模型转化成onnx并加载
- 2.1.1转化成onnx模型
- 2.1.2 tengine 加载onnx模型
- 2.2 pytorch模型转化成caffe模型
- 2.2.1 微软MMDNN工具
- 2.2.2 pytorch2caffe
- 2.3. pytorch框架用caffe框架代替,训练导出caffe模型。
- 3. 总结
0.Tengine介绍
OADI/Tengine | github
Tengine 是OPEN AI LAB 为嵌入式设备开发的一个轻量级、高性能并且模块化的引擎。
Tengine在嵌入式设备上支持CPU,GPU,DLA/NPU,DSP异构计算的计算框架,实现异构计算的调度器,基于ARM平台的高效的计算库实现,针对特定硬件平台的性能优化,动态规划计算图的内存使用,提供对于网络远端AI计算能力的访问支持,支持多级别并行,整个系统模块可拆卸,基于事件驱动的计算模型,吸取已有AI计算框架的优点,设计全新的计算图表示。
1.Tengine 支持的OP
https://github.com/OAID/Tengine/wiki/支持的OP
- CPU
- Caffe
Data、Input、Convolution、Deconvolution、Pooling、Eltwise、Softmax、Normalize、Slice、SoftmaxWithLoss、ReLU、PReLU、InnerProduct、Split、Concat、Dropout、Accuracy、BatchNorm、Scale、LRN、Permute、Flatten、PriorBox、Reshape、DetectionOuput、RPN、ROIPooling、Reorg、Region、Resize - Tensorflow
AvgPool、MaxPool、Conv2D、DepthwiseConv2dNative、FusedBatchNorm、Relu6、Relu、Softmax、ConcatV2、Add、Sub、Mul、Minimum、Rsqrt、ResizeNearestNeighbor、ComposedBN、Const、Reshape - MXNet
Convolution、Pooling、SoftmaxOuput、Concat、BatchNorm、Dropout、Activation、minusscalar、mulscalar、elemwise_add、LeakyReLU、FullyConnected、Reshape - ONNX
Conv、Relu、MaxPool、GlobalAveragePool、AveragePool、Concat、Dropout、Softmax、BatchNromalization、Add、Flatten、Gemm
- Caffe
- GPU
- GPU计算使用的ACL目前仅支持Input、BN、Concat、Convolution、Dropout、Eltwise、FC、Pooling、ReLu、ReLu6、Resize、Softmax
2.实施方案
设想的方案有三种,对于本来使用pytorch框架来搭建模型的同学来说,由易到难按顺序为:
- pytorch模型转化成onnx。
- pytorch模型转化成caffe模型。
- pytorch框架用caffe框架代替,训练导出caffe模型。
2.1 pytorch模型转化成onnx并加载
2.1.1转化成onnx模型
可参考博客PyTorch学习总结(三)——ONNX
但是这次训练的是用FPN+SSD的方法,转化的时候遇到如下等的诸多问题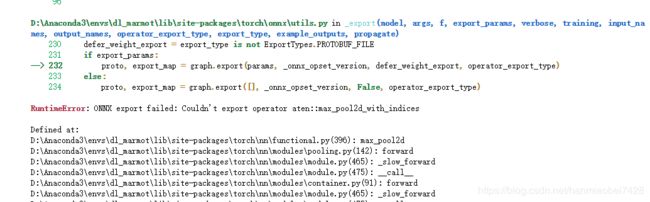
魔改了一下,最终还是放弃了这个方案,改用SSD来做检测。
最后转化成onnx模型成功。
2.1.2 tengine 加载onnx模型
修改tengine目录下的makefile.config文档
在# Enable other serializers 中取消关于ONNX的注释,注释掉其他模型,这里是在PC上调试,故注释掉 CONFIG_ARCH_ARM64=y,取消注释CONFIG_ARCH_BLAS=y,具体文档如下。
#-------------------------------------------------------------------------------
# Template configuration for compiling
#
# First copy makefile.config.example to makefile.config (assume you are on the
# root directory).
#
# $ cp makefile.config.example makefile.config
#
# Next modify makefile.config, and then compile by
#
# $ make
#
# or build in parallel with 8 threads
#
# $ make -j8
#-------------------------------------------------------------------------------
# Set the target arch
# CONFIG_ARCH_ARM64=y
# Enable Compiling Optimization
CONFIG_OPT_CFLAGS = -O2
# Enable GPU support by Arm Computing Library
# CONFIG_ACL_GPU=y
#
# Use BLAS as the operator implementation
#
CONFIG_ARCH_BLAS=y
# Set the path of ACL
# ACL_ROOT=/home/firefly/ComputeLibrary
# Enable other serializers
# CONFIG_CAFFE_SERIALIZER=y
# CONFIG_MXNET_SERIALIZER=y
CONFIG_ONNX_SERIALIZER=y
# CONFIG_TF_SERIALIZER=y
CONFIG_TENGINE_SERIALIZER=y
# Enable Wrappers
# CONFIG_FRAMEWORK_WRAPPER=y
# version postfix
CONFIG_VERSION_POSTFIX=github
在tengine目录下重新make 通过后,在之前已调试过的MSSD下测试。
修改mssd.cpp的代码:
修改model路径,这里的models/ARM_OCR.onnx为具体路径。
#define DEF_MODEL "models/ARM_OCR.onnx"
修改部分加载模型的代码:
// const char *model_name = "mssd_300";
// if(proto_file.empty())
// {
// proto_file = root_path + DEF_PROTO;
// std::cout<< "proto file not specified,using "<运行,报错
cannot find load function for operator: ReduceL2
cannot find load function for operator: Constant
tengine对于ONNX的模型支持较差,询问了官方工程师,对该模型的支持可能不会继续做,如果有需要可以自己移植。
对于有时间有兴趣的同学,可以尝试自己移植。我们这边先采取下面的方法。
2.2 pytorch模型转化成caffe模型
2.2.1 微软MMDNN工具
mmdnn的方法是要先在pytorch框架下转化成权重和结构两个文件,称之为IR ,再从caffe框架下转化成它的.py和.npy,再生成.prototxt。
按照官方给的操作方法,
mmtoir -f pytorch -d resnet101 --inputShape 3,224,224 -n imagenet_resnet101.pth
这里我使用lenet保存的lenet-5.pth作为测试
mmtoir -f pytorch -d lenet --inputShape 1,32,32 -n lenet-5.pth
报错
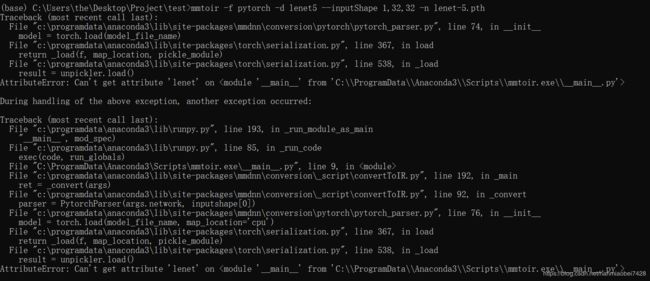
在网上找到类似的问题,解决办法是类.module = ‘lenet’,
https://www.stefaanlippens.net/python-pickling-and-dealing-with-attributeerror-module-object-has-no-attribute-thing.html

仍没有解决。
在 https://github.com/Microsoft/MMdnn/issues/241 找到一致的问题,使用他的方法尝试解决。
将mmdnn的resp下载本地,修改MMdnn\mmdnn\conversion\pytorch\pytorch_parser.py。
注释掉 从 67行到 76行, 在 77行添加 model = model_file_name
如下
def __init__(self, model_file_name, input_shape):
super(PytorchParser, self).__init__()
# if not os.path.exists(model_file_name):
# print("Pytorch model file [{}] is not found.".format(model_file_name))
# assert False
# # test
# # cpu: https://github.com/pytorch/pytorch/issues/5286
# try:
# model = torch.load(model_file_name)
# except:
# model = torch.load(model_file_name, map_location='cpu')
model = model_file_name
self.weight_loaded = True
# Build network graph
self.pytorch_graph = PytorchGraph(model)
self.input_shape = tuple([1] + input_shape)
self.pytorch_graph.build(self.input_shape)
self.state_dict = self.pytorch_graph.state_dict
self.shape_dict = self.pytorch_graph.shape_dict
在pytorch0.4.0的环境下,进入到MMdnn文件夹,安装mmdnn工具。
pip install -e . -U
安装好之后,我们用lenet网络作为测试。
test.py 代码如下
# -*- coding: utf-8 -*-
# %%
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision import datasets
dataset = datasets.MNIST(root=r'./Datasets/mnist/', train=True,
transform=transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
]),
target_transform=None, download=True)
dataloader = DataLoader(dataset, batch_size=1024, shuffle=True, num_workers=32, drop_last=True)
print('load train data ok')
# %%
class lenet(nn.Module):
def __init__(self):
super(lenet, self).__init__()
self.activate = nn.ReLU(inplace=True)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5),
self.activate,
self.pool,
nn.Conv2d(6, 16, kernel_size=5),
self.activate,
self.pool
)
self.fc = nn.Sequential(
nn.Linear(16*5*5, 120),
self.activate,
nn.Linear(120, 84),
self.activate,
nn.Linear(84, 10)
)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size()[0], -1)
x = self.fc(x)
return x
# %%
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = lenet().to(device)
# Build Loss and Optimizer.
criterion = nn.CrossEntropyLoss(reduction='mean')
lr = 1e-1
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
print('start to train')
# Forward propagation.
for epoch in range(2):
loss_aver = 0
for i, (image, label) in enumerate(dataloader):
output = net(image.to(device))
loss = criterion(output, label.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_aver += loss.item()
print("{}_epoch: {}, loss_aver: {}".format(i, epoch, loss_aver / (i + 1)))
torch.save(net.state_dict(), './lenet-5.pth')
if (epoch + 1) % 20 == 0:
# 周期性阶梯式降学习率
lr *= 0.75
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# %%
model = lenet()
model.load_state_dict(torch.load('./lenet-5.pth'))
print('load ok')
# %%
from mmdnn.conversion.pytorch.pytorch_parser import PytorchParser
size=32
pytorchparser = PytorchParser(model, [1, size, size])
IR_file = 'lenet'
pytorchparser.run(IR_file)
对于其它需要处理的,只需要加上转化代码即可,注意这里保存模型的时候是通过 torch.save(net.state_dict(), ‘./lenet-5.pth’)这样的方式来保存。
# %%
model = lenet()
model.load_state_dict(torch.load('./lenet-5.pth'))
print('load ok')
# %%
from mmdnn.conversion.pytorch.pytorch_parser import PytorchParser
size=32
pytorchparser = PytorchParser(model, [1, size, size])
IR_file = 'lenet'
pytorchparser.run(IR_file)
运行
python test.py
如果报错TypeError: _jit_pass_onnx(): incompatible function arguments. The following argument types are supported,则切换至pytorch0.4.0环境下重新运行。
如果报错 ,No module named ‘cv2’,则
pip install opencv-python
成功转化的运行结果为:
IR network structure is saved as [lenet.json].
IR network structure is saved as [lenet.pb].
IR weights are saved as [lenet.npy].
再在caffe环境下运行
mmtocode -f caffe -n lenet.pb -w lenet.npy -d caffe_lenet_converted.py -dw caffe_lenet_converted.npy
结果为:
Parse file [lenet.pb] with binary format successfully.
Target network code snippet is saved as [caffe_lenet_converted.py].
Target weights are saved as [caffe_lenet_converted.npy].
最后在caffe环境中运行
mmtomodel -f caffe -in caffe_lenet_converted.py -iw caffe_lenet_converted.npy -o caffe_target
正确结果为:
WARNING: Logging before InitGoogleLogging() is written to STDERR
I1229 13:21:46.023447 30749 net.cpp:53] Initializing net from parameters:
state {
phase: TRAIN
level: 0
}
layer {
name: "input"
type: "Input"
top: "input"
input_param {
shape {
dim: 1
dim: 1
dim: 32
dim: 32
}
}
}
layer {
name: "lenetnSequentialnconvnnConv2dn0n11"
type: "Convolution"
bottom: "input"
top: "lenetnSequentialnconvnnConv2dn0n11"
convolution_param {
num_output: 6
bias_term: true
group: 1
stride: 1
pad_h: 0
pad_w: 0
kernel_h: 5
kernel_w: 5
}
}
layer {
name: "lenetnSequentialnconvnnReLUn1n12"
type: "ReLU"
bottom: "lenetnSequentialnconvnnConv2dn0n11"
top: "lenetnSequentialnconvnnConv2dn0n11"
}
layer {
name: "lenetnSequentialnconvnnMaxPool2dn2n13"
type: "Pooling"
bottom: "lenetnSequentialnconvnnConv2dn0n11"
top: "lenetnSequentialnconvnnMaxPool2dn2n13"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
pad_h: 0
pad_w: 0
}
}
layer {
name: "lenetnSequentialnconvnnConv2dn3n14"
type: "Convolution"
bottom: "lenetnSequentialnconvnnMaxPool2dn2n13"
top: "lenetnSequentialnconvnnConv2dn3n14"
convolution_param {
num_output: 16
bias_term: true
group: 1
stride: 1
pad_h: 0
pad_w: 0
kernel_h: 5
kernel_w: 5
}
}
layer {
name: "lenetnSequentialnconvnnReLUn1n15"
type: "ReLU"
bottom: "lenetnSequentialnconvnnConv2dn3n14"
top: "lenetnSequentialnconvnnConv2dn3n14"
}
layer {
name: "lenetnSequentialnconvnnMaxPool2dn2n16"
type: "Pooling"
bottom: "lenetnSequentialnconvnnConv2dn3n14"
top: "lenetnSequentialnconvnnMaxPool2dn2n16"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
pad_h: 0
pad_w: 0
}
}
layer {
name: "lenetnSequentialnfcnnLinearn0n18"
type: "InnerProduct"
bottom: "lenetnSequentialnconvnnMaxPool2dn2n16"
top: "lenetnSequentialnfcnnLinearn0n18"
inner_product_param {
num_output: 120
bias_term: true
}
}
layer {
name: "lenetnSequentialnfcnnReLUn1n19"
type: "ReLU"
bottom: "lenetnSequentialnfcnnLinearn0n18"
top: "lenetnSequentialnfcnnLinearn0n18"
}
layer {
name: "lenetnSequentialnfcnnLinearn2n20"
type: "InnerProduct"
bottom: "lenetnSequentialnfcnnLinearn0n18"
top: "lenetnSequentialnfcnnLinearn2n20"
inner_product_param {
num_output: 84
bias_term: true
}
}
layer {
name: "lenetnSequentialnfcnnReLUn1n21"
type: "ReLU"
bottom: "lenetnSequentialnfcnnLinearn2n20"
top: "lenetnSequentialnfcnnLinearn2n20"
}
layer {
name: "lenetnSequentialnfcnnLinearn4n22"
type: "InnerProduct"
bottom: "lenetnSequentialnfcnnLinearn2n20"
top: "lenetnSequentialnfcnnLinearn4n22"
inner_product_param {
num_output: 10
bias_term: true
}
}
I1229 13:21:46.023567 30749 layer_factory.hpp:77] Creating layer input
I1229 13:21:46.023586 30749 net.cpp:86] Creating Layer input
I1229 13:21:46.023597 30749 net.cpp:382] input -> input
I1229 13:21:46.023633 30749 net.cpp:124] Setting up input
I1229 13:21:46.023643 30749 net.cpp:131] Top shape: 1 1 32 32 (1024)
I1229 13:21:46.023656 30749 net.cpp:139] Memory required for data: 4096
I1229 13:21:46.023663 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnconvnnConv2dn0n11
I1229 13:21:46.023681 30749 net.cpp:86] Creating Layer lenetnSequentialnconvnnConv2dn0n11
I1229 13:21:46.023689 30749 net.cpp:408] lenetnSequentialnconvnnConv2dn0n11 <- input
I1229 13:21:46.023696 30749 net.cpp:382] lenetnSequentialnconvnnConv2dn0n11 -> lenetnSequentialnconvnnConv2dn0n11
I1229 13:21:46.023726 30749 net.cpp:124] Setting up lenetnSequentialnconvnnConv2dn0n11
I1229 13:21:46.023736 30749 net.cpp:131] Top shape: 1 6 28 28 (4704)
I1229 13:21:46.023741 30749 net.cpp:139] Memory required for data: 22912
I1229 13:21:46.023751 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnconvnnReLUn1n12
I1229 13:21:46.023761 30749 net.cpp:86] Creating Layer lenetnSequentialnconvnnReLUn1n12
I1229 13:21:46.023766 30749 net.cpp:408] lenetnSequentialnconvnnReLUn1n12 <- lenetnSequentialnconvnnConv2dn0n11
I1229 13:21:46.023773 30749 net.cpp:369] lenetnSequentialnconvnnReLUn1n12 -> lenetnSequentialnconvnnConv2dn0n11 (in-place)
I1229 13:21:46.023787 30749 net.cpp:124] Setting up lenetnSequentialnconvnnReLUn1n12
I1229 13:21:46.023793 30749 net.cpp:131] Top shape: 1 6 28 28 (4704)
I1229 13:21:46.023799 30749 net.cpp:139] Memory required for data: 41728
I1229 13:21:46.023804 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnconvnnMaxPool2dn2n13
I1229 13:21:46.023813 30749 net.cpp:86] Creating Layer lenetnSequentialnconvnnMaxPool2dn2n13
I1229 13:21:46.023818 30749 net.cpp:408] lenetnSequentialnconvnnMaxPool2dn2n13 <- lenetnSequentialnconvnnConv2dn0n11
I1229 13:21:46.023825 30749 net.cpp:382] lenetnSequentialnconvnnMaxPool2dn2n13 -> lenetnSequentialnconvnnMaxPool2dn2n13
I1229 13:21:46.023838 30749 net.cpp:124] Setting up lenetnSequentialnconvnnMaxPool2dn2n13
I1229 13:21:46.023846 30749 net.cpp:131] Top shape: 1 6 14 14 (1176)
I1229 13:21:46.023851 30749 net.cpp:139] Memory required for data: 46432
I1229 13:21:46.023856 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnconvnnConv2dn3n14
I1229 13:21:46.023865 30749 net.cpp:86] Creating Layer lenetnSequentialnconvnnConv2dn3n14
I1229 13:21:46.023871 30749 net.cpp:408] lenetnSequentialnconvnnConv2dn3n14 <- lenetnSequentialnconvnnMaxPool2dn2n13
I1229 13:21:46.023880 30749 net.cpp:382] lenetnSequentialnconvnnConv2dn3n14 -> lenetnSequentialnconvnnConv2dn3n14
I1229 13:21:46.023898 30749 net.cpp:124] Setting up lenetnSequentialnconvnnConv2dn3n14
I1229 13:21:46.023907 30749 net.cpp:131] Top shape: 1 16 10 10 (1600)
I1229 13:21:46.023912 30749 net.cpp:139] Memory required for data: 52832
I1229 13:21:46.023922 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnconvnnReLUn1n15
I1229 13:21:46.023929 30749 net.cpp:86] Creating Layer lenetnSequentialnconvnnReLUn1n15
I1229 13:21:46.023936 30749 net.cpp:408] lenetnSequentialnconvnnReLUn1n15 <- lenetnSequentialnconvnnConv2dn3n14
I1229 13:21:46.023943 30749 net.cpp:369] lenetnSequentialnconvnnReLUn1n15 -> lenetnSequentialnconvnnConv2dn3n14 (in-place)
I1229 13:21:46.023952 30749 net.cpp:124] Setting up lenetnSequentialnconvnnReLUn1n15
I1229 13:21:46.023958 30749 net.cpp:131] Top shape: 1 16 10 10 (1600)
I1229 13:21:46.023963 30749 net.cpp:139] Memory required for data: 59232
I1229 13:21:46.023968 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnconvnnMaxPool2dn2n16
I1229 13:21:46.023975 30749 net.cpp:86] Creating Layer lenetnSequentialnconvnnMaxPool2dn2n16
I1229 13:21:46.023982 30749 net.cpp:408] lenetnSequentialnconvnnMaxPool2dn2n16 <- lenetnSequentialnconvnnConv2dn3n14
I1229 13:21:46.023988 30749 net.cpp:382] lenetnSequentialnconvnnMaxPool2dn2n16 -> lenetnSequentialnconvnnMaxPool2dn2n16
I1229 13:21:46.023999 30749 net.cpp:124] Setting up lenetnSequentialnconvnnMaxPool2dn2n16
I1229 13:21:46.024008 30749 net.cpp:131] Top shape: 1 16 5 5 (400)
I1229 13:21:46.024013 30749 net.cpp:139] Memory required for data: 60832
I1229 13:21:46.024018 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnfcnnLinearn0n18
I1229 13:21:46.024025 30749 net.cpp:86] Creating Layer lenetnSequentialnfcnnLinearn0n18
I1229 13:21:46.024031 30749 net.cpp:408] lenetnSequentialnfcnnLinearn0n18 <- lenetnSequentialnconvnnMaxPool2dn2n16
I1229 13:21:46.024039 30749 net.cpp:382] lenetnSequentialnfcnnLinearn0n18 -> lenetnSequentialnfcnnLinearn0n18
I1229 13:21:46.024103 30749 net.cpp:124] Setting up lenetnSequentialnfcnnLinearn0n18
I1229 13:21:46.024113 30749 net.cpp:131] Top shape: 1 120 (120)
I1229 13:21:46.024119 30749 net.cpp:139] Memory required for data: 61312
I1229 13:21:46.024129 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnfcnnReLUn1n19
I1229 13:21:46.024138 30749 net.cpp:86] Creating Layer lenetnSequentialnfcnnReLUn1n19
I1229 13:21:46.024144 30749 net.cpp:408] lenetnSequentialnfcnnReLUn1n19 <- lenetnSequentialnfcnnLinearn0n18
I1229 13:21:46.024152 30749 net.cpp:369] lenetnSequentialnfcnnReLUn1n19 -> lenetnSequentialnfcnnLinearn0n18 (in-place)
I1229 13:21:46.024159 30749 net.cpp:124] Setting up lenetnSequentialnfcnnReLUn1n19
I1229 13:21:46.024166 30749 net.cpp:131] Top shape: 1 120 (120)
I1229 13:21:46.024171 30749 net.cpp:139] Memory required for data: 61792
I1229 13:21:46.024176 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnfcnnLinearn2n20
I1229 13:21:46.024183 30749 net.cpp:86] Creating Layer lenetnSequentialnfcnnLinearn2n20
I1229 13:21:46.024189 30749 net.cpp:408] lenetnSequentialnfcnnLinearn2n20 <- lenetnSequentialnfcnnLinearn0n18
I1229 13:21:46.024196 30749 net.cpp:382] lenetnSequentialnfcnnLinearn2n20 -> lenetnSequentialnfcnnLinearn2n20
I1229 13:21:46.024225 30749 net.cpp:124] Setting up lenetnSequentialnfcnnLinearn2n20
I1229 13:21:46.024233 30749 net.cpp:131] Top shape: 1 84 (84)
I1229 13:21:46.024240 30749 net.cpp:139] Memory required for data: 62128
I1229 13:21:46.024247 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnfcnnReLUn1n21
I1229 13:21:46.024255 30749 net.cpp:86] Creating Layer lenetnSequentialnfcnnReLUn1n21
I1229 13:21:46.024260 30749 net.cpp:408] lenetnSequentialnfcnnReLUn1n21 <- lenetnSequentialnfcnnLinearn2n20
I1229 13:21:46.024267 30749 net.cpp:369] lenetnSequentialnfcnnReLUn1n21 -> lenetnSequentialnfcnnLinearn2n20 (in-place)
I1229 13:21:46.024276 30749 net.cpp:124] Setting up lenetnSequentialnfcnnReLUn1n21
I1229 13:21:46.024281 30749 net.cpp:131] Top shape: 1 84 (84)
I1229 13:21:46.024286 30749 net.cpp:139] Memory required for data: 62464
I1229 13:21:46.024292 30749 layer_factory.hpp:77] Creating layer lenetnSequentialnfcnnLinearn4n22
I1229 13:21:46.024298 30749 net.cpp:86] Creating Layer lenetnSequentialnfcnnLinearn4n22
I1229 13:21:46.024304 30749 net.cpp:408] lenetnSequentialnfcnnLinearn4n22 <- lenetnSequentialnfcnnLinearn2n20
I1229 13:21:46.024312 30749 net.cpp:382] lenetnSequentialnfcnnLinearn4n22 -> lenetnSequentialnfcnnLinearn4n22
I1229 13:21:46.024324 30749 net.cpp:124] Setting up lenetnSequentialnfcnnLinearn4n22
I1229 13:21:46.024332 30749 net.cpp:131] Top shape: 1 10 (10)
I1229 13:21:46.024336 30749 net.cpp:139] Memory required for data: 62504
I1229 13:21:46.024348 30749 net.cpp:202] lenetnSequentialnfcnnLinearn4n22 does not need backward computation.
I1229 13:21:46.024353 30749 net.cpp:202] lenetnSequentialnfcnnReLUn1n21 does not need backward computation.
I1229 13:21:46.024359 30749 net.cpp:202] lenetnSequentialnfcnnLinearn2n20 does not need backward computation.
I1229 13:21:46.024365 30749 net.cpp:202] lenetnSequentialnfcnnReLUn1n19 does not need backward computation.
I1229 13:21:46.024370 30749 net.cpp:202] lenetnSequentialnfcnnLinearn0n18 does not need backward computation.
I1229 13:21:46.024376 30749 net.cpp:202] lenetnSequentialnconvnnMaxPool2dn2n16 does not need backward computation.
I1229 13:21:46.024382 30749 net.cpp:202] lenetnSequentialnconvnnReLUn1n15 does not need backward computation.
I1229 13:21:46.024389 30749 net.cpp:202] lenetnSequentialnconvnnConv2dn3n14 does not need backward computation.
I1229 13:21:46.024394 30749 net.cpp:202] lenetnSequentialnconvnnMaxPool2dn2n13 does not need backward computation.
I1229 13:21:46.024400 30749 net.cpp:202] lenetnSequentialnconvnnReLUn1n12 does not need backward computation.
I1229 13:21:46.024405 30749 net.cpp:202] lenetnSequentialnconvnnConv2dn0n11 does not need backward computation.
I1229 13:21:46.024411 30749 net.cpp:202] input does not need backward computation.
I1229 13:21:46.024416 30749 net.cpp:244] This network produces output lenetnSequentialnfcnnLinearn4n22
I1229 13:21:46.024430 30749 net.cpp:257] Network initialization done.
Caffe model files are saved as [caffe_target.prototxt] and [caffe_target.caffemodel], generated by [caffe_lenet_converted.py] and [caffe_lenet_converted.npy].
最终生成caffe_target.prototxt和caffe_target.caffemodel,完成转换。
2.2.2 pytorch2caffe
该方法没有使用过,读者可自行尝试。
https://github.com/longcw/pytorch2caffe
2.3. pytorch框架用caffe框架代替,训练导出caffe模型。
该方法在前面均不成功时使用,此时不需要使用。
3. 总结
采用修改后的微软的mmdnn工具完成了从pytorch0.4.0模型到caffe模型的转化。