Linux多线程编程学习(1)--线程的概念和线程控制
Linux多线程编程学习总结
- 一.线程的概念
- 1.什么是线程?
- 2.进程和线程的区别
- 3.进程和线程的关系
- 4.线程的优缺点
- 4.1 优点
- 4.2 缺点
- 5.线程异常
- 二.线程控制
- 1.POSIX线程库
- 2.创建线程
- 3.区分进程ID和线程ID
- 4.线程终止
- 5.线程等待
- 5.1 为什么要存在线程等待?
- 5.2 如何等待
- 6.线程分离
一.线程的概念
1.什么是线程?
- 在一个程序中的一个
执行路线就可以叫做一个线程(thread)。线程是一个进程内部的控制序列。 - 一个进程
至少要存在一个执行线路。 - 线程是在
进程的地址空间上运行,多个线程实际上共享了一个进程的地址空间。 - 通过进程的地址空间,可以看到一个进程的
大部分资源,多线程执行流就是将进程的资源合理分配给多个执行流。 - Linux下的进程称为
轻量级进程,因为Linux系统下的线程是使用进程模拟实现的,CPU在调度PCB的时候,这个PCB很可能是一个线程,这个PCB相对于以前学的进程比较轻量化,所以称为轻量级进程。
2.进程和线程的区别
- 进程是
资源竞争的单位,它担当分配资源的实例。 - 线程是
程序执行的最小单位,它是程序被调度执行的基本单位 - 多个线程实际上是一个
进程的地址空间对应多了几个PCB - 多个线程
共享进程的大部分数据(代码区、数据区、全局变量、常量区、库、堆区、文件描述符、信号处理方式、用户ID和组ID、当前的工作目录等) - 但是线程也有自己
独立的一部分数据(线程ID、一组寄存器(上下文,有上下文才可以被调度)、运行时堆栈(各个线程间互不干扰)、errno、信号屏蔽字、调度优先级等)
3.进程和线程的关系
4.线程的优缺点
4.1 优点
- Linux下创建一个线程的
代价比创建一个进程小的多,因为线程是使用进程模拟的。 - 线程之间的切换需要操作系统做的工作很少,只需要
切换上下文即可。不用像进程一样,切换上下文,页表,地址空间等。 - 线程占用的
资源比进程少很多。 - 可以充分利用
多处理器的可并行数量。 - 在等待
慢速IO操作结束的同时,程序可以执行其他的任务,不需要阻塞等待,提高效率。 计算密集型应用,将计算分解到多线程中执行,这样就可以在多处理器上同时运行。IO密集型应用,线程可以同时等待多个IO操作。
4.2 缺点
- 性能损失:指的是增加了额外的
同步和调度开销,而可用的资源不变。 - 健壮性降低:线程是
缺乏保护的,可能更改其他不该修改数据。 - 缺乏访问控制:进程是
访问控制的基本粒度,在一个线程中调⽤用某些OS函数会对整个进程造成影响 - 编程的难度很高:
编写与调试一个多线程程序⽐单线程程序困难得多
5.线程异常
- 单个线程如果出现了一些
不可逆转的错误(例如:野指针、除零操作)。不仅会导致该线程崩溃,而且进程也随之崩溃。 - 线程是进程的
执行分支,线程异常,会触发信号机制,从而终止进程,该进程的其他线程也会被终止。
二.线程控制
1.POSIX线程库
- 与线程有关的函数构成了⼀个完整的库
(用户级别的库),大多数函数的名字都是以“pthread_”打头的 - 要使⽤这个函数库,要通过引⼊头文件
链接这些线程函数库时要使⽤用编译器命令的“-lpthread”(引用一个库的名称,全称libpthrea.a或者libpthread.so)选项
2.创建线程
函数解释:
//功能:创建一个新的线程
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*star t_routine)(void*), void *arg);
//参数:
thread:返回线程ID
attr:设置线程的属性,attr为NULL表⽰使⽤用默认属性
start_routine:是个函数地址,线程启动后要执⾏行的函数
arg:传给线程启动函数的参数
//返回值:
成功返回0,失败返回错误码
对于pthread_create函数,它的错误判断应该:
- 大部分函数的
返回值是,成功返回0,失败返回-1,并且对全局变量errno赋值以指示错误。 pthreads函数出错时不会设置全局变量errno,而是将错误代码通过返回值返回。但是大部分其他POSIX函数会设置errno。pthreads同样也提供了线程内的errno变量,以支持其它使⽤errno的代码。对于pthreads函数的错误,建议通过返回值判定,因为读取返回值要比读取线程内的errno变量的开销更⼩。
查看进程信息:ps -axj | grep 进程名 | grep -v grep(过滤掉grep进程信息)
查看线程信息:ps -aL | grep 进程名
#include 下边为运行结果:
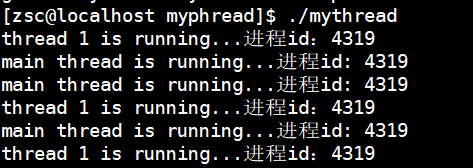
在另一个中断查看线程信息,看结果:

注意:两个线程到底哪个线程先运行,取决于调度器的调度。一个进程中任意一个线程因为一些不可逆转的操作使得该线程挂掉,那么该进程也会随着退出。
3.区分进程ID和线程ID
- 在Linux中,目前的线程实现是
Native POSIX Thread Libaray,简称NPTL。在这种实现下,线程⼜被称为轻量级进程(Light Weighted Process)。每⼀个用户态的线程,在内核中都对应一个调度实体,也拥有自己的进程描述符(task_struct结构体)。 - 没有线程之前,
一个进程对应内核⾥的一个进程描述符,对应一个进程ID。但是引入线程概念之后,情况发生了变化,一个用户进程下管辖N个用户态线程,每个线程作为一个独立的调度实体在内核态都有自己的进程描述符,进程和内核的描述符一下子就变成了1:N关系,POSIX标准又要求进程内的所有线程调用getpid函数时返回相同的进程ID。所以Linux内核又引入了线程组的概念
struct task_struct {
...
pid_t pid;//线程id
pid_t tgid;//相当于用户层面的进程id
...
struct task_struct *group_leader;
...
struct list_head thread_group;
...
};
多线程的进程,又被称为线程组,线程组内的每一个线程在内核之中都存在一个进程描述符 (task_struct)与之对应。进程描述符结构体中的pid,表面上看对应的是进程ID,其实不是,它对应的是线程ID。进程描述符中的tgid,含义是Thread Group ID,该值对应的是用户层面的进程id。
如何查看线程ID:ps -eLf |head -1 && ps -eLf |grep a.out |grep -v grep

LWP:线程ID,代表线程组中的pidNLWP:线程组内线程的个数
可以看出在上边的mythread代码中,有两个线程,线程ID分别是5227、5228。可以发现线程ID中有一个线程5227与进程的ID相同,这个线程在用户态被叫做主线程,在内核态被叫做group leader。线程组内存在的第一个线程ID等于进程的ID,该线程是线程组的主线程。线程组的其他线程的ID由内核分配。
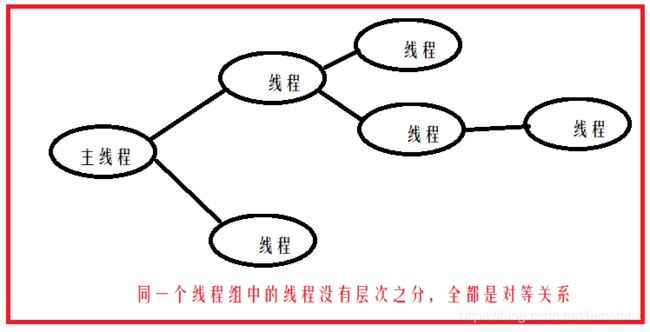
线程和进程不一样,进程有父子进程的概念,但是线程没有。在线程组中,所有的线程都是对等关系:
- pthread_t类型的线程ID
在上边的线程创建函数pthread_create函数中,该函数作用是创建一个线程,该函数创建完成之后,会产生一个新的线程ID,该线程ID存放在第一个参数所指向的地址中。这个线程ID的类型是pthread_t和上边线程库中的线程ID不是一个东西,线程库只能的线程ID是pid_t类型的,它属于线程调度的范畴(因为线程是轻量级进程,是Linux操作系统调度的最小单位,调度时需要一个唯一的整数来识别)。但是pthread_create函数产生的线程ID,属于NPTL线程库的范畴,线程的后续操作时要通过pthread_t类型的线程ID来进行的。
线程库是一个用户级别的库,提供了一个可以获得线程自身ID的接口:
//用来获得线程自身的ID,pthread_t类型实质上是进程地址空间的一个地址
pthread_t pthread_self(void);
4.线程终止
线程终止指的是终止某个线程而不是终止某个进程,在终止某个线程的时候,不可以影响其他的线程。对于终止线程有三种方法:
- 在线程函数中
return。(这个方法不适用于主线程,从在主线程中调用return,相当于在一个进程中调用exit,结果是终止进程) - 线程可以调用
pthread_exit函数终止自己。
//函数作用:终止线程
void pthread_exit(void *value_ptr);
参数:value_ptr是一个输出型参数,这个指针指向一块空间,这个空间包括一些退出信息。这个参数不能指向一个局部变量,一定要是全局变量或者是malloc出来的空间,因为当其他线程得到这个值时,该线程已经退出,局部变量已经全部销毁
返回值:无返回值,和exit一样
- 一个线程可以调用
pthread_cancel终止线程组中的另一个线程
int pthread_cancel(pthread_t thread);
参数:pthread_t类型的线程ID
返回值:取消成功返回0,失败返回错误码
5.线程等待
5.1 为什么要存在线程等待?
- 和
进程等待类似,如果没有线程等待,会造成类似僵尸进程的状态 - 已经退出的线程,它的
空间没有立即释放,仍然在地址空间内,而是要等到获得该线程的退出信息后,通知该线程,线程才会释放资源,如果不进行等待,会造成资源泄露 - 有时候需要让一个线程去执行一段代码,我们
需要知道它是否帮我们完成了指定的要求,或者异常终止,这时候我们就需要获取线程运行结果 - 创建的新线程并不会
复用刚才退出线程的地址空间内
5.2 如何等待
- pthread_join函数
//调用此函数的线程将挂起等待,直到该线程终止
int pthread_join(pthread_t thread, void **value_ptr);
参数:
thread:线程ID
value_ptr:这个指针指向pthread_exit的参数,pthread_exit的参数用来指向线程的返回值
返回值:成功返回0,失败返回退出码
关于value_ptr参数的值:
- 如果
thread线程通过return返回,value_ ptr所指向的单元里存放的是thread线程函数的返回值 - 如果
thread线程被别的线程调用pthread_ cancel异常终掉,value_ ptr所指向的单元里存放的是常数PTHREAD_ CANCELED - 如果
thread线程是⾃己调用pthread_exit终止的 ,value_ptr所指向的单元存放的是传给pthread_exit的参数的指针 - 如果对
thread线程的终止状态不感兴趣,可以传NULL给value_ ptr参数
6.线程分离
- 在默认情况下,新创建的线程是
可以被等待的(join),当线程退出之后,需要通过pthread_join对该线程等待,否则无法释放该线程所占用的资源,从而造成资源泄露 - 如果我们
不想知道某个线程的返回值状态,对该线程join其实是一种负担。在这种情况下,我们可以通过分离线程告诉OS,当线程退出时,自动的释放线程资源
pthread_detach函数:
函数功能:分离线程,OS自动释放资源,不需要等待
//线程组内其他线程对目标线程分离
int pthread_detach(pthread_t thread);
//线程自己分离
int pthread_detach(pthread_self());
注:一个线程可被等待和分离是两种状态,它们是冲突的,一个线程不能即使可被等待的也被分离。