linux环境下的伪分布式的hadoop基本搭建
搭建hadoop
1.查看防火墙的命令:service iptables status
2.查看防火墙的开关状态:chkconfig iptables --list 这里面有七个,分别对应了其中系统模式:使用命令(vim /etc/inittab)可以查看:七种模式分别是:关机模式,单用户模式,多用户模式(没有NFS),多用户模式,未使用到,图形界面模式,重启模式
关闭防火墙使用命令: chkconfig iptables off
*设置服务器的主机名称采取主机映射的方式:vim /etc/sysconfig/network
*在这里我犯过的一个错误是:我使用阿里服务器的时候,进行主机名称与ip地址进行映射的时候,在配置文件中如果写的是映射的名字的话,服务开启就会不成功,所以我建议在配置文件中还是不要写映射名,而是写确定的ip地址比较好
设置映射方式的用途就在于,可以以后使用指定的用户名来代替IP地址进行界面化的hadoop集群访问
*命令echo用于输出环境变量
3.配置hadoop
(1).http://archive.apache.org/dist/ (下载hadoop的网站)
hadoop->core->stable(稳定版本)
(2)这里面下载的hadoop文件存放的路径比如:/usr/hadoop
(3).修改配置文件:(进入到hadoop目录下的etc文件夹,文件夹中保存了hadoop需要的各种配置文件)
一、vim hadoop-env.sh (配置hadoop依赖的jdk)
修改JAVA_HOME地址:export JAVA_HOME=jdk地址
二、vim core-site.xml
//指定hdfs的namenode的地址
//用来指定hadoop运行时产生文件的存放目录(并不是临时文件 )
三、vim hdfs-site.xml
//指定hdfs保存数据副本的数量
四、vim mapred-site.xml(这个需要进行重命名的操作)
//指定mapreduce运行在yarn上面
五、vim yarn-site.xml
//nodemanager获取数据的方式采取shuffle的方式
//指定yarn的老大:resourceManager的地址
(3)配置hadoop的环境变量:
vim /etc/profile

(4)namenode进行格式化操作:
hdfs namenode -format
这步之后,hadoop目录下个就会多出来了tmp文件
(5)开启服务进程:
在目录下的sbin文件中输入命令: ./start.all-sh 进行服务的开启操作
在这里可能会遇到无法识别主机名的错误:Unknownhostnameexception,说主机名称是bogon
解决的方法是修改主机名称和IP地址的映射关系:
使用命令: vim /etc/sysconfig/network,在里面修改 HOSTNAME=yourname(你的主机名)
并添加GATEWAY=ip(你的IP地址)
然后使用命令: vim /etc/hosts 添加主机名和IP地址的映射关系: ip(你的IP地址):yourname(你的主机名)
操作完毕之后,使用命令:hostname yourname(你的主机名);然后使用命令su就可以在不关机的情况下修改你的主机名称了
这些步骤经过之后,hadoop服务就可以正常使用了。
*修改本地的windows机器下的一个配置文件:计算机->C盘->Windows->System32->drivers->etc->hosts
修改hosts文件,在文件中添加IP地址的映射关系之后,就可以通过浏览器的方式,通过界面化的方式去访问hadoop集群的单个节点的数据信息了:
只要在里面添加上服务器的外网的IP地址就可以了,当然,我还是不建议采取地址映射的方法去设置这一项,因为在阿里服务器里面还是不太好用这个功能。
之后通过浏览器去访问这个url地址:http://139.129.49.49:50070/ (服务器的IP地址+50070)
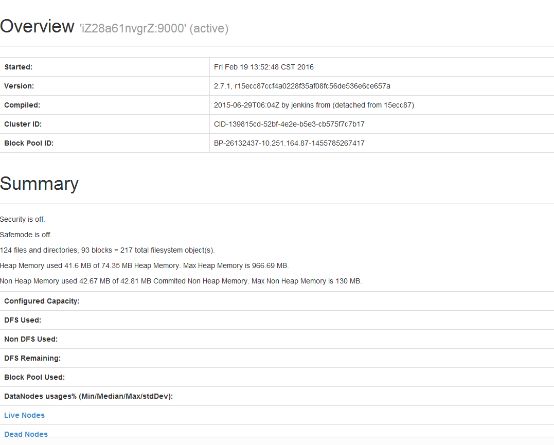
就可以看到结点中的数据文件的信息了:
(特别注意:有时候访问这个网址但是网页却没有正常显示的原因可能就是因为防火前没有关闭的原因,只要把服务器端的防火墙关闭就可以正常访问这个网址了)
之后可以点击下面的这个选项”Browse the file system”来查看到结点中的文件信息

使用SSH免密码登陆模式:在~目录下查询文件ll -a查询到隐藏文件.ssh,进入到这个文件中输入命令ssh-keygen -t rsa之后按回车继续。之后会产生公钥和私钥,这个公钥就是对外开放的密钥,只要将这个公钥给别人,别人再登陆你的服务器就不用再输入密码了。之后输入命令: cp id_rsa.pub authorized_keys,之后目录中就会产生一个新的文件了,之后就配置成功了