语义分割--FCN 算法中的一些细节--特征怎么融合
语义分割--FCN 算法中的一些细节--特征怎么融合
Fully Convolutional Networks for Semantic Segmentation
语义分割 FCN 算法 这里主要说一下 FCN-32s 、FCN-16s 、FCN-8s 三个分割结果是怎么得到的,从而知道FCN中的特征到底是怎么融合的?
首先来看看 最粗糙的分割结果 FCN-32s 是怎么得到的?
我们通过将全连接层变为卷积层,实现分类器变身稠密预测即分割 Adapting classifiers for dense prediction,如下图所示
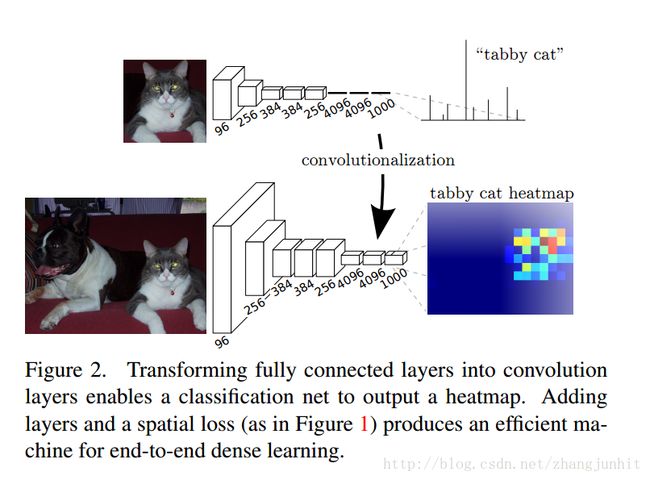
如果我们将 AlexNet 变为全卷积网络用于图像稠密分类( discarding the final classifier layer, and convert all fully connected layers to convolutions),
如下图所示 
如果227 × 227输入图像经过一系列卷积池化,得到一个图像对应的特征图,以前用该特征图进行分类,得到该图像的类别信息
对于一个 500×500 大小的图像,我们可以用 10 × 10 个 227 × 227子图像块进行覆盖,这样就得到了 10 × 10 个特征图,分别对这些特征图进行分类,得到一个10 × 10 的分割结果。
这里我们使用一个 1 × 1卷积层进行分类,对于PASCAL 数据库有 21个类别(包括背景)
We append a 1 × 1 convolution with channel dimension 21 to predict scores for each of the PASCAL classes (including background) at each of the coarse
output locations, followed by a deconvolution layer to bilinearly upsample the coarse outputs to pixel-dense outputs
得到一个 10 × 10 的分割结果A,我们使用一个 deconvolution layer 进行双线性上采样到输入图像尺寸得到 FCN-32s分割结果, 直接放大32倍
deconvolution layer 中的滤波器参数通过学习得到。
Note that the convolution filter in such a layer need not be fixed (e.g., to bilinear upsampling), but can be learned. A stack of deconvolution layers and activation functions can even learn a nonlinear upsampling.
下面再看看怎么得到 FCN-16s 这个分割结果,即怎么融合卷积网络中间特征图的 
一开始的计划是这样的:首先将不同尺寸的特征图 搞到一个尺寸,因为 Layer fusion is essentially an elementwise operation. 这里需要放大,裁剪,对齐。 in general, layers to be fused must be aligned by scaling and cropping,对齐之后就是将不同特征图 组合起来concatenation,最后用一个 score layer 分类,
Having spatially aligned the layers, we next pick a fusion operation. We fuse features by concatenation, and immediately follow with classification by a “score layer” consisting of a 1 × 1 convolution.
但是因为存储 concatenated features 需要内存,所以我们就先分类,再 concatenation
Rather than storing concatenated features in memory, we commute the concatenation and subsequent classification (as both are linear).
实际我们是这么干的:对 pool4 的输出使用一个 1 × 1 卷积层,步长为 16个像素进行分类,得到一个分割结果图B,然后 再对 conv7 的分割结果A 进行 2× upsampling layer 得到一个放大2倍的分割结果图A2, 将这两个分类置信度图求和相加得到了 一个分割结果图 C,最后使用一个 deconvolution layer 进行双线性上采样到输入图像尺寸得到 FCN-16s分割结果,直接放大16倍
We first divide the output stride in half by predicting from a 16 pixel stride layer. We add a 1 × 1 convolution layer on top of pool4 to produce additional class predictions. We fuse this output with the predictions computed on top of conv7 (convolutionalized fc7) at stride 32 by adding a 2× upsampling layer and summing both predictions
FCN-8s 结合图3
对 pool3 的输出使用一个 1 × 1 卷积层,步长为 8个像素进行分类,得到一个分割结果图 D,然后 再对 FCN-16s中 的分割结果 C 进行 2× upsampling layer 得到一个放大2倍的分割结果图C2, 将这两个分类置信度图求和相加得到了 一个分割结果图 E,最后使用一个 deconvolution layer 进行双线性上采样到输入图像尺寸得到 FCN-16s分割结果,直接放大8倍