SpringBoot整合Netty并使用Protobuf进行数据传输
我只是给代码注入灵魂;
官方地址: https://github.com/google/protobuf
高效的编码方式 Google Protocol
我们在编写网络应用程序的时候需要注意codec(编解码器),因为数据在网络中传输的都是二进制字节码数据,而我们拿到的目标数据往往
不是字节码数据,因此在发送数据时就需要编码,收到数据时需要解码
codec 的组成部分有两个:decoder(解码器)和encoder(编码器)。encoder 负责把业务数据转换成字节码数据,decoder 负责把字节码数据转换成业务数据。
其实Java 的序列化技术就可以作为codec 去使用,但是它的硬伤太多:
1. 无法跨语言,这应该是Java 序列化最致命的问题了。
2. 序列化后的体积太大,是二进制编码的5 倍多。
3. 序列化性能太低。
由于Java 序列化技术硬伤太多,因此Netty 自身提供了一些codec,如下所示:
Netty 提供的解码器:
1. StringDecoder, 对字符串数据进行解码
2. ObjectDecoder,对Java 对象进行解码
Netty 提供的编码器:
1. StringEncoder,对字符串数据进行编码
2. ObjectEncoder,对Java 对象进行编码
Netty 本身自带的ObjectDecoder 和ObjectEncoder 可以用来实现POJO 对象或各种业务对象的编码和解码,但其内部使用的仍是Java 序列化技术,所以我们不建议使用。因此对
于POJO 对象或各种业务对象要实现编码和解码,我们需要更高效更强的技术。
Google 的Protocol(Google出品必然牛x)
Protocol 是Google 发布的开源项目,全称Google Protocol Buffers,特点如下:
- 支持跨平台、多语言(支持目前绝大多数语言,例如C++、C#、Java、python 等)
- 高性能,高可靠性
- 使用Protocol 编译器能自动生成代码,Protocol 是将类的定义使用.proto 文件进行描述,然后通过protoc.exe 编译器根据.proto 自动生成.java 文件
1, 首先是安装
2, 使用:
- 2.1 引入Protocol的依赖
<dependency>
<groupId>com.google.protobufgroupId>
<artifactId>protobuf-javaartifactId>
<version>3.5.1version>
dependency>
-
2.2 定义自己的协议格式
接着是需要按照官方要求的语法定义自己的协议格式。
比如我这里需要定义一个输入输出的报文格式:
MessageRequestBase.protosyntax = "proto3"; // (1) option java_package = "cn.haoxiaoyong.record.proto.protobuf";//(2) option java_outer_classname = "MessageRequestBase";//(3) message MessageRequest {//(4) string requestId = 1;//(5) string content = 2; }
(1): 版本号,protobuf语法有 proto2和proto3两种,这里指定 proto3
(2): 指定包名
(3): 设置生成的Java类名
(4): 内部类的类名,真正的POJO
(5): 设置类中的属性,符号后是序号,不是属性值
注意个文件名MessageRequestBase.proto必须是 .proto后缀
MessageResponseBase.proto:
syntax = "proto3";
option java_package = "cn.haoxiaoyong.record.proto.protobuf";
option java_outer_classname = "MessageResponseBase";
message MessageResponse {
int32 code = 1;
string content = 2;
string msg = 3;
}
以上同理,其中string,int32,是这个字段的类型,更多类型参考官方文档,基本上java中的数据类型都包含了,其中还包含了枚举(enum)类型;
- 2.3 安装成功之后,通过protoc.exe 根据描述文件(.proto)生成Java 类,具体操作如下所示:
- 进入
MessageRequestBase.proto,MessageResponseBase.proto这两个文件所在的目录; - 执行
protoc --java_out=/tmp MessageRequestBase.proto MessageResponseBase.proto,生成的 java类就会在 /tmp 文件夹下;当然这个目录可以改为其他的.(如果你是windows电脑就可以指定在C盘下或者D盘下,看心情。。) - 将这两个 java 类拷贝到项目中,这两个类我们不要编辑它,直接拿着用即可,该类内部有一个内部类,这个内部类才是真正的POJO,一定要注意。
- 进入
- 2.4在项目中使用,Netty 已经自带了对 Google protobuf 的编解码器,也是只需要在 pipline 中添加即可。
Client:
public class ClientHandlerInitilizer extends ChannelInitializer<Channel> {
@Override
protected void initChannel(Channel ch) throws Exception {
ch.pipeline()
// google Protobuf 编解码
.addLast(new ProtobufDecoder(MessageResponseBase.MessageResponse.getDefaultInstance()))
.addLast(new ProtobufEncoder())
.addLast(new NettyClientHandler());
}
}
上述代码在编写客户端程序时,要向Pipeline 链中添加ProtobufEncoder 编码器对象。
@RequestMapping("/send")
public String send(@RequestBody RestInfo restInfo) {
MessageRequestBase.MessageRequest message = new MessageRequestBase.MessageRequest()
.toBuilder()
.setContent(restInfo.getStr())
.setRequestId(UUID.randomUUID().toString()).build();
//异步执行
nettyClient.sendMsg(message);
return "send ok";
}
上述代码在往服务器端发送(POJO)时就可以使用生成的MessageRequestBase类搞定,非常方便。
Server:
public class NettyServerHandlerInitializer extends ChannelInitializer<Channel> {
@Override
protected void initChannel(Channel ch) throws Exception {
ch.pipeline()
.addLast(new ProtobufDecoder(MessageRequestBase.MessageRequest.getDefaultInstance()))
.addLast(new ProtobufEncoder())
.addLast(new NettyServerHandler());
}
}
上述代码在编写服务器端程序时,要向Pipeline 链中添加ProtobufDecoder 解码器对象。
稍微注意的是,在构建 ProtobufDecoder 时需要显式指定解码器需要解码成什么类型。在服务端MessageRequestBase.MessageRequest.getDefaultInstance(),在客户端MessageResponseBase.MessageResponse.getDefaultInstance()
@Override
protected void channelRead0(ChannelHandlerContext ctx, MessageRequestBase.MessageRequest msg) throws Exception {
if (msg.getContent() != null) {
log.info("收到客户端的业务消息:{}",msg.toString());
//在这里做一些业务处理操作。。。
String converter = NettyServerHandler.converter.converterTask(msg);
log.info("server 拿到处理后的返回结果 :{}",converter);
MessageResponseBase.MessageResponse response = MessageResponseBase.MessageResponse.newBuilder()
.setCode(200)
.setContent(converter)
.setMsg("success")
.build();
ctx.writeAndFlush(response);
}
}
上述代码在服务器端接收数据时,直接就可以把数据转换成 pojo 使用,非常方便
结束了吗…No… (看看了时间已经将近零点了,该睡了,看博客你也不要熬夜,注意身体,加油!)
本文介绍了Netty中使用Protobuf的编码解码;下篇文件将介绍**使用Protobuf解决粘包拆包**;
使用方式
1,启动:NettyApplication
2,使用postman或者其他工具请求:
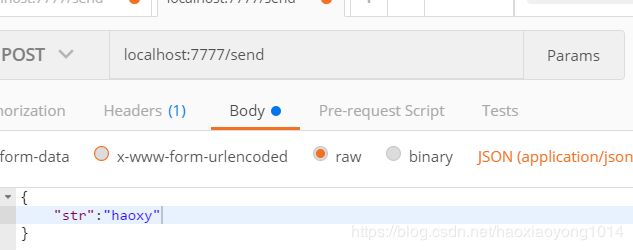
控制台打印:

demo 地址:
当前项目:Netty框架–netty编码解码(项目中proto包下)
多线程并发编程(项目中thread包下)
BIO编程(项目中bio包下)
NIO编程(项目中nio包下)
自定义RPC(项目中rpc包下)
欢迎给个小星星鼓励一下(记得Star哦,害羞脸)…
