颜水成:深度学习、Baby Learning与人工智能
深度学习(Deep Learning)当前的成功离不开与大数据的结合,但从业者也渴望摆脱对大量标注样本的依赖。颜水成(YAN Shuicheng),奇虎360首席科学家、360人工智能研究院院长,曾任新加坡国立大学电子与计算机工程系的Dean’s Chair Associate Professor,提出了模拟婴儿自学习逐步获取知识的Baby Learning方法,对于学习模型的自我增强与自我适应非常有价值。近日,CSDN记者采访了颜水成,从研究和应用两个角度对深度学习的进展、问题与未来发展进行剖析,并对深度学习从业人员如何开展工作的方法提出建议。
个人简介
CSDN:能否介绍一下您目前的重点工作,以及为什么选择从事深度学习的研究?
颜水成:我目前在360的工作重点是开展计算机视觉与大数据相关的人工智能基础技术研究,为公司在物联网及大数据分析方面提供技术支持,同时探索新产品的研发。深度学习是人工智能研究院当前的一个核心,主要解决语义感知层次的问题。另一个核心是3D相关技术,主要解决物理感知层次的问题。后一个核心不涉及机器学习过程,但也是产生人工智能及其重要的步骤。
我个人14年来一直主要在探索更好地解决人脸、物体、行为相关问题的算法。期间经历了子空间学习,稀疏性分析,到深度学习的三个有代表性的阶段。这三个阶段本身差别很大,但和我自己的计算数学专业的背景都密切相关,很多优化的思想在这三个阶段都是贯通的。
深度学习与人工智能
CSDN:您曾在公开场合谈深度学习方法的优势,今天深度学习在视觉、语音领域的进展确实让人工智能焕发新春,但历史上人工智能也曾经多次被高估过,您认为业界对深度学习的应用潜力是否过于乐观?
颜水成:这个问题很多学者都讨论过。我个人觉得,一方面,这次人工智能的浪潮是以大数据和可承受的高性能计算为铺垫的。无论学术界还是工业界,都有足够的空间去探索和实践自己关心问题。另一方面深度学习的发展也激发了相关领域的发展,比如说低能耗的芯片研发。这样不同领域在配合同时也充分利用深度学习的发展,从而大大促进了技术产业化的可能性。学术界当前普遍认为深度学习是靠数据暴力而获得成功,但如果从工业界的角度来讲,看重的主要是技术是否可用,是否可以支撑一个好的产品,而且工业界要处理的很多问题天然地就是大数据。所以,深度学习非常适合业界的需要。当然,我们也不能迷信深度学习能把所有问题都解决,其实业界更多地时候是在考虑,随着深度学习的发展,哪些应用和产品形态已经是时候启动了。
CSDN:关于神经网络的研究,在很多方面依靠生物学、神经科学等领域。在您看来,深度学习的模型是否已经完善?若没有,目前最大的缺陷或困难在于何处?
颜水成:基于深度学习的人工智能应该包含两部分,一部分是知识如何表达,一部分是人的知识如何获取。
- 第一部分的进展确实令人振奋。这部分当前的一个缺陷是还没有很好地模拟大脑中的反馈机制。虽然有不少具备一定反馈机制的模型提出来,但是还没有从根本上去模拟大脑的时间连续反馈的能力。
- 第二部分涉及人从婴孩到小孩,再到大人,逐步获取知识的过程。当前的模型一般采用批量式学习,同时需要大量学习样本的学习方法本身不是人类学习方式的模仿。这部分的问题如果能很好解决,对于少量样本学习或者无监督学习将产生根本性影响。
CSDN:如您所言,开发智能机器在很大程度上受限于对人脑机制理解的缺乏,那么在这个存在许多假设和未知的前沿领域进行研究,您如何判断自己研究的方向和做出的各种选择是否正确?
颜水成:我个人对于脑认知本身并没有深入研究。这方面的研究更多基于直觉和常识,比如说我们探索了好几年的“Baby Learning”。同时,很多研究是基于计算数学的一些基础理论。从这两方面考虑,如果一个方向对于解决问题应该有益,那么就可以去开拓这个方向。
CSDN:能否概括Baby Learning的核心思想,以及目前的主要进展和重点问题?
颜水成: Baby Learning的核心思想在于模拟Baby的自学习、never-ending learning过程,包含:
- 先验建模(baby 生下来不是一张白纸)
- 个例/少例学习(父母从少儿读物上教的少量样本)
- context-based 自学习(边探索大千世界,边自我学习与自适应)
- 主动反馈(有问题就问老师、问父母)
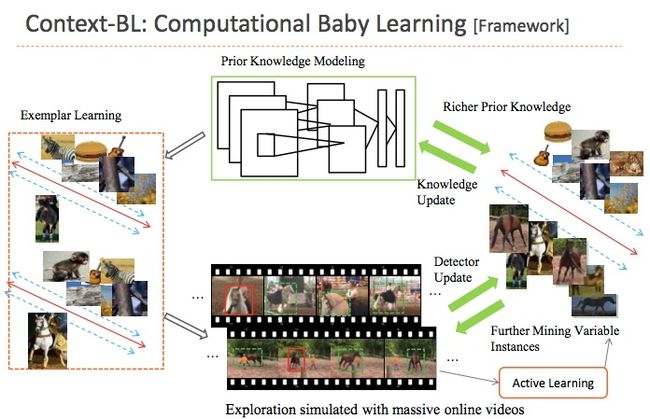
这种方法当前在人脸检测和一般物体检测上都取得很不错的性能提升,同时这种思想也可使用在机器人上,对于机器人在具体环境中自适应能力的逐步增强非常有价值。
当前最大的问题在于context-based自学习阶段可使用的context非常有限,当前主要采用temporal contexts, 但其他的contexts 肯定也是有价值的,值得深入研究。
CSDN:Science杂志在2015年12月发表的Bayesian Program Learning方法,您认为对Baby Learning的研究有一些什么启发吗?
颜水成: Bayesian Program Learning 是一个非常令人exciting 的工作,我非常喜欢。这个工作也是受启发于小孩子只要少量样本就能得到不错的模型, 同时能自动创造新的样本。两者要解决的问题不一样,Bayesian Program Learning 更加fundamental,而baby learning则是一个通用的never-ending learning框架,适用于很多的任务,也能解决各种具体困难(比如说姿态、遮挡、模糊等)。Bayesian Program Learning 可以替换第二步个例/少例学习,将非常有利于baby learning的进一步发展。
CSDN:Baby Learning之外,在过去的2015年,深度学习领域取得的哪些成就让您印象最深刻?
颜水成:除了更深的网络这方面很多从业界研究院出来的工作,我对两个系列的工作印象最为深刻。
一个系列是image-to-caption 相关的,基本做法是CNN与RNN的融合来bridge图像和文本之间的gap。最终目标是为图像自动产生高质量的文本描述,从而便于图像的搜索和使用。
另一个系列是根基于Generative Adversarial Network(GAN),巧妙地提供了一个图像生成的框架,通过generative和discriminative 模型的融合,当discriminative 模型无法区分真实图像和通过generative 模型产生的图像,即获得了一个高性能的特定类型图像生成器。
这两个系列的工作如果继续基于大数据发展下去,将产生很多非常有价值的应用。
从业者的思考
CSDN:深度学习的原理已经不是秘密。但为什么如今只有少数几人成为这个领域的顶尖科学家?对于研究者来说,想要做出一流研究和应用,您认为决胜的关键因素是什么?
颜水成:个人觉得顶尖专家比较少的主要原因是深度学习理论上的匮乏和相对无从下手,这样大部分工作看起来挺工程,从而后面很难产生质的飞跃。但是我相信迟早会有不错的理论体系来解释和指导这个领域的发展,到时会产生很多新的角度的顶尖科学家。如果仔细观察,最近一流的研究和应用,主要都在工业界或有工业背景的研究组。主要有三方面的原因:1)数据上的优势,2)计算资源上的优势,3)人才的相对稳定性和专注性。个人觉得学术界可以更专注于深度学习的理论研究或深度学习在新的领域的应用。
CSDN:能否介绍您为什么选择在360开展您的工作?对于在您在360未来一年的研究和影响,您有什么样的期待?
颜水成:去年我在一家互联网公司进行了我人生的第一次sabbatical leave, 期间成功帮助这家公司把深度学习技术落地成公司的一个日用户百万级的产品。这个经历让我深深明白人工智能技术落地最快的方式还是和顶尖的公司一起去做,这样让自己专注于技术本身,而不必分心去思考别的非技术因素。奇虎360最吸引我的地方是技术的落地性非常好,同时公司在物联网方向的总体发展纲要和我个人的研究/人生目标非常吻合,这些都是人生非常难得的机遇。在360未来一年,一方面会继续扩大招聘研究员和实习生,进行原创技术的积累。另一方面,会主要支持公司的两个物联网/智能硬件产品,将技术尽快落地,为广大的360产品用户提供各种云端/本地智能支持。同时研究院也会探索新的产品形态。
CSDN:对于深度学习的入门和进阶,您有什么学习方法的建议或者书籍的推荐?
颜水成:这个问题,我曾经在不少场合给过建议。当前深度学习的研究很像老中医,很多独门秘笈需要手把手来言传身教,自己摸索起来费时费力。所以最好的办法是到优秀的研究组去访问,这样周围有很多经验丰富的研究者,从而可以得到及时的指点,避免走弯路。(责编/周建丁)
本文为CSDN原创文章,未经允许不得转载,如需转载请联系market#csdn.net(#换成@)