介绍
Gatling是一款功能强大的负载测试工具。它的设计易于使用,可维护性和高性能。
开箱即用,Gatling提供了对HTTP协议的出色支持,使其成为负载测试HTTP服务器的首选工具。
只要底层协议(如HTTP)可以以非阻塞方式实现,Gatling的体系结构就是异步的。这种架构允许我们将虚拟用户实现为消息而不是专用线程,这使得它们非常便宜。因此,运行数千个并发虚拟用户不是问题。(和jmeter区别点)
Gatling是一款基于Scala 开发的高性能服务器性能测试工具,它主要用于对服务器进行负载等测试,并分析和测量服务器的各种性能指标。Gatling主要用于测量基于HTTP的服务器,比如Web应用程序,RESTful服务等,除此之外它拥有以下特点:
- 支持Akka Actors 和 Async IO,从而能达到很高的性能
- 支持实时生成Html动态轻量报表,从而使报表更易阅读和进行数据分析
- 支持DSL脚本,从而使测试脚本更易开发与维护
- 支持录制并生成测试脚本,从而可以方便的生成测试脚本
- 支持导入HAR(Http Archive)并生成测试脚本
- 支持Maven,Eclipse,IntelliJ等,以便于开发
- 支持Jenkins,以便于进行持续集成
- 支持插件,从而可以扩展其功能,比如可以扩展对其他协议的支持
- 开源免费
获取Gatling
官网下载即可。
(需要使用JDK1.8,有可能会存在版本问题,
我的版本为java version "1.8.0_111")
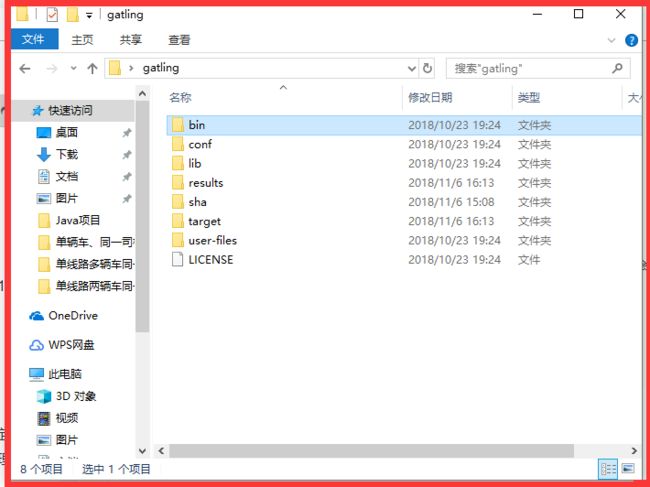
目录结构如图。简单来说:
bin: gatling也就两种组件-录制的组件和运行的组件;这个目录里面有两种脚本,一个是运行recorder的,也就是录制组件启动脚本;一个是运行组件的启动脚本;
conf: 放配置文件的目录。一般情况下你想要修改一些运行参数,都可来这里搞定;
lib: 里面是一些jar包,gatling的运作全靠他们了;我们仅作为使用者暂时不必去理会;
results: 测试报告目录;
target: 你启动运行组件后,gatling会为你编译好所有的.scala脚本,而编译后的class文件就会在这里;
user-files: 存放你录制后的.scala脚本;
总的来说,用gatling做一次简单的测试步骤如下(忽略细节):

- 在bin里打开recorder.bat(GUI)
- 录制后,在user-files里针对刚录制好的.scala文件作你想要的修改
- 在bin里打开gatling.bat(控制台)
- 选择你要运行哪一个脚本,并运行 ,运行完成后,在results目录下查看结果
实践
1.打开recorder
录制看一下脚本是啥样。所以打开了recorder
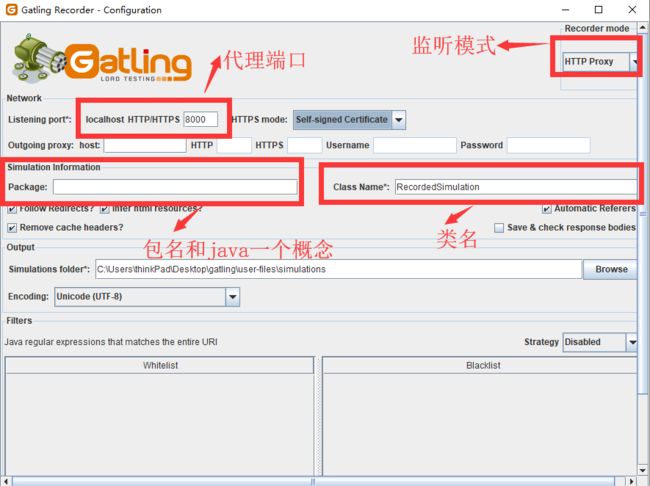
还可以使用以下选项进行设置:
- (Follow Redirects? checked)关注重定向?检查
- (Automatic Referers? checked)自动参考?检查
- (Black list first filter strategy selected)选择黑名单第一个过滤策略,黑名单过滤器中的。。css,。。js和。*。ico
2. 设置一下浏览器代理
打开浏览器,设置代理端口和上面保持一致。

3. 开始录制
回到recorder中,点一下Start,随后在浏览器中模仿真实用户的场景。完成场景播放后,单击StopRecorder界面。
脚本默认会存在定义的输出文件夹gatling\user-files\simulations里面,名称为类的名字。
默认所有的.scala脚本都放置在\user-files\simulations中某一个包的根目录下,一旦项目变得庞大,是会变的不容易进行维护的。
可以考虑以包的形式来存放脚本
做法,在
\user-files\simulations里面创建包名存放脚本。
4. 查看脚本
查看user-files/simulations/computerdatabase在名称下的Gatling安装文件夹中生成BasicSimulation.scala。(这个是官方自带的脚本)
官方已经解释的很明确
对稍微懂点代码的测试人员,这个脚本都是简单易懂的:
httpProtocol中的BlackList描述了你将不会录制针对css,js和ico文件的请求。录制到了几个请求头header。
scenario("HomePage")定义了这个场景的名称。默认以你的类名来命名,当然你可以改,比如改成SinaHomePage。修改这个名字只会影响你运行该脚本后在报告中看到的名字。
这个庞大的场景“HomePage”赋给了变量scn。当然,你也可以把他赋值给另一个变量叫做SinaUsers,看起来更为贴切,代码更易懂。
setUp(scn)就是运行这个场景的主函数。
inject为这个场景注入一些用户。这里atOnceUsers代表一次性一个用户来做这个操作——因为刚才录制时就是这种情况.
5. 运行脚本
bin\gatling.bat
运行后短暂等待一下,gatling会编译\user-files\simulations里面存在的所有脚本:
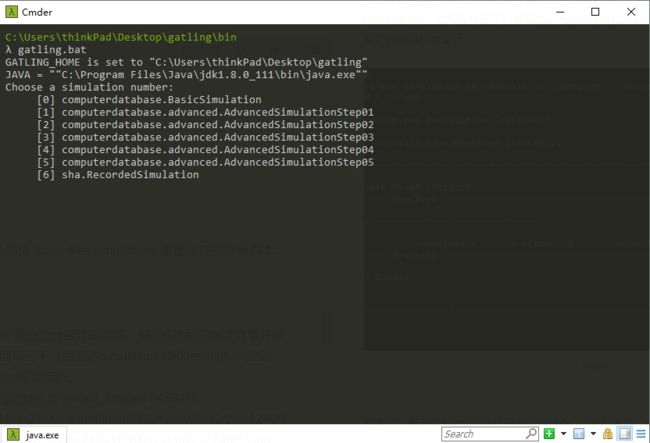
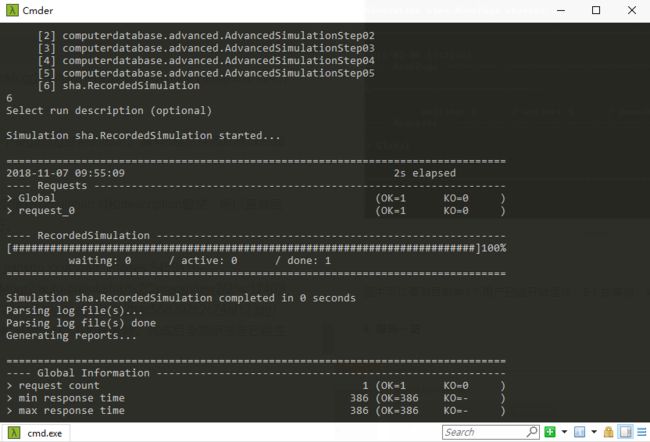
可以看到已经编译成功。前面6个是gatling自带的脚本。编号6是后续添加修改的脚本。
cmd中敲入6,然后回车三下(后面的simulation id和description留空,所以直接回车)。可以看到gatling开始运行。
6. 报告一览
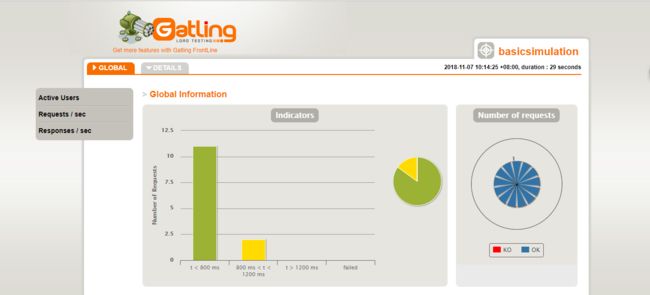
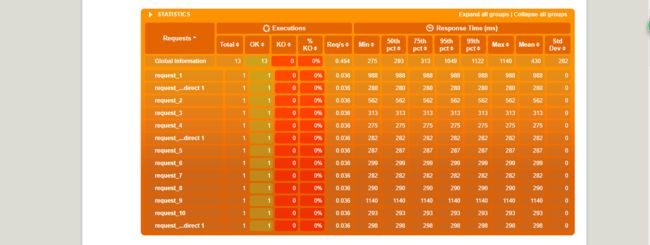
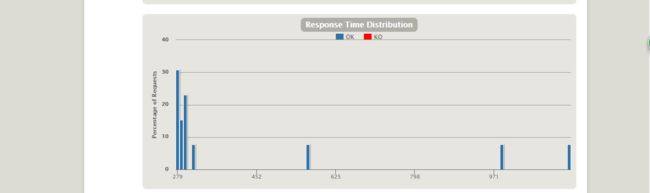
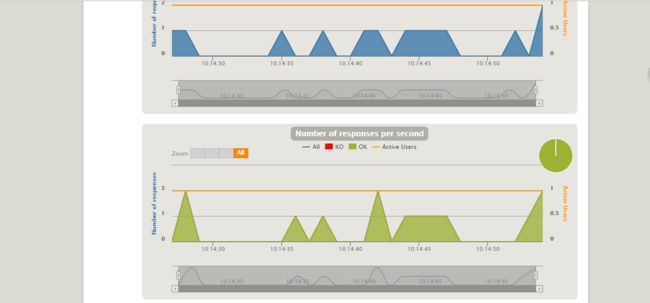
要针对gatling的report进行详尽透彻的分析,并正确评价系统,甚至找出性能瓶颈
HAR文件生成脚本
Gatling的Recorder提供了HAR Converter的功能。
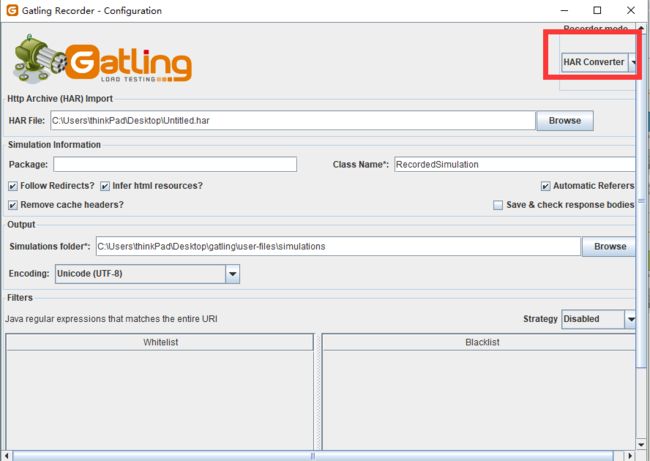
这样产生的脚本会更加精准。
高级用法
分层设计
类似于Selenium的PageObject模式。
借用官网解释
在我们的场景中,我们有三个独立的过程
- 搜索:按名称搜索模型
- 浏览:浏览模型列表
- 编辑:编辑给定的模型
将提取这些链并将它们存储到对象中。对象是原生的Scala单例。
object Search {
val search = exec(http("Home") // let's give proper names, as they are displayed in the reports
.get("/"))
.pause(7)
.exec(http("Search")
.get("/computers?f=macbook"))
.pause(2)
.exec(http("Select")
.get("/computers/6"))
.pause(3)
}
object Browse {
val browse = ???
}
object Edit {
val edit = ???
}
和Java就很相似了,借用面对对象的思想,把公用的封装为对象,需要使用的时候就调用对象里面的方法。
可以使用这些可重用的业务流程重写我们的场景
val scn = scenario("Scenario Name").exec(Search.search, Browse.browse, Edit.edit)
当然更加具体的请参照官网
Gatling的功能点
官网是最好的教学https://gatling.io/docs/current/general/