异步运行时IO问题分析
Table of Contents
1. Xline运行时性能问题
2. 异步运行时和阻塞操作
3. Runtime调度问题
4. 性能测试
4.1 测试结果分析
5. 如何正确实现?
6. 何时能够在Runtime上阻塞
7. 总结
在异步运行时上进行编程经常是很困难的,在本篇文章中,我们主要会通过Xline开发中的几个例子,讨论Rust的异步运行时中有关于IO的问题,以及在代码实现中如何正确使用Tokio runtime以实现最佳性能。我会使用Tokio runtime作为本文的示例。本文所有示例都运行在:
AMD EPYC 7543 32-Core Processor
Samsung 980 pro NVME SSD
Ubuntu 22.04.3 LTS, GNU/Linux 6.5.0-21-generic
rustc 1.79.0 (129f3b996 2024-06-10)
tokio 1.38.001、Xline运行时性能问题
在Xline的性能测试中我遇到了使用异步运行时的一些麻烦,我发现在WAL(Write-Ahead-Log)的实现中,使用异步的文件读写会产生相当高的延迟,由于WAL的写入存在于关键路径上,这是不可以接受的,那么如何进行优化呢?
02、异步运行时和阻塞操作
我们首先简单回顾一下Rust中异步运行时的机制。我们知道Rust的async机制是通过协作式调度来实现并发的,Runtime维护了一个线程池(在Tokio中称为worker threads),通常等于主机上CPU的线程数量,对于线程池中的每个线程,runtime会分配一个executor。Runtime通过scheduler将任务(task)分发到每个executor上。
在Rust async的代码中,我们通过在 .await 点处进行切换不同的任务,当调用 .await 时,我们会将控制权交还给scheduler,以便能够运行其他的任务,这样就实现了各个任务之间的协作模式。下面就是一个异步的模式:
#[tokio::main(flavor = "current_thread")]
async fn main() {
let task = tokio::spawn(async {
println!("Hello");
});
tokio::time::sleep(Duration::from_secs(1)).await;
println!("World!");
task.await.unwrap();
}我们设置tokio使用 current_thread ,因此现在tokio runtime中只有一个线程。在以上的代码中存在两个task,一个是 main 本身的task,另外一个是通过 tokio::spawn 生成的另一个task,我们尝试在 main 中调用异步的 tokio::time::sleep ,那么我们就会通过这个 .await 挂起当前的task,然后切换到我们spawn的task。这样就不会有时间浪费在等待文件读取上。同时我们也可以给出一个阻塞操作的示例:
```rust
use tokio::time::Duration;
#[tokio::main(flavor = "current_thread")]
async fn main() {
let task = tokio::spawn(async {
println!("World!");
});
std::thread::sleep(Duration::from_secs(1));
println!("Hello");
task.await.unwrap();
}
```std::thread::sleep 就是一个阻塞操作,和 tokio::time::sleep 不同的是,它会直接进行系统调用,将整个线程置入休眠状态,因此,当我们执行sleep时,它同时也阻止了scheduler切换到其他的task,我们spawn的task无法取得任何进展,因此造成CPU资源的浪费。
从理论上来说,只要我们不使用阻塞的操作,Rust的异步运行时在逻辑上就不会浪费CPU时间,提供了一层零成本的抽象。但是,在实际使用中,用户仍然需要考虑如何才能最高效地使用runtime。
03、Runtime调度问题
回到我们之前的WAL的性能问题,我们首先来阅读下面简化过的代码:
#[tonic::async_trait]
impl Protocol for Server {
async fn propose(
&self,
request: Request,
) -> Result, Status> {
let req = request.into_inner();
let (tx, rx) = oneshot::channel();
self.send_to_persistent((req, tx));
Ok(Response::new(rx.recv().await))
}
}
impl Server {
async fn persistent_task(&self) {
loop {
let (reqs, txs) = self.recv_batch().await {
self.log_file.write_all(reqs.encode()).await;
self.log_file.fdatasync().await;
for tx in txs {
tx.send(ProposeResponse {});
}
}
}
}
} 这段代码中Xline中的gRPC server会接受Client的Propose请求,对于每个ProposeRequest,Xline必须将其写入WAL文件,并且同步到存储设备上。为了降低写入的延迟,我们在持久化中使用Dispatch的模式,每个请求都会通过channel发送到 persistent_task 。而在 persistent_task 中每次会获取一个batch的请求并写入文件。
可以注意到的是,对于 log_file 的写入和同步,都是使用的Tokio的异步fs实现的,使得在写入的过程中我们可以继续处理其他client传递的command。表面看上去似乎没有发现什么问题,但是在性能测试时,我们发现在高负载下 write_all 与 fdatasync 都经历了相当高的延迟,单次完整的写入甚至需要数毫秒才能完成。
这个例子实际上就是使用异步运行时进行文件操作的一个反模式。当Xline server经历大量负载时,runtime上此时会堆积非常多的任务,当我们的 persistent_task 进行异步写入的过程中yeild到runtime后,它重新被schedule的时间就会显著延长。这时即使内核中写入操作已经完成, persistent_task 仍然无法取得进展。在高负载下,runtime可能优先处理gRPC的请求,而server最先收到的请求反而无法优先完成处理,这个例子实际上体现了我们对请求处理的优先级,和Runtime调度的顺序之间产生了冲突,因此导致性能的下降。
04、性能测试
我们可以通过编写一个简单的性能测试以佐证上述的说法,这个测试用于显示在高负载runtime中使用异步IO的问题。简要来说,在这个测试中我们会首先需要在runtime上生成一些CPU任务增加负载,而在此期间进行文件IO的性能测试。
完整的测试的代码:
https://github.com/bsbds/bench_tokio_fs
测试结果:
https://bsbds.github.io/bench_tokio_fs/report/
测试中使用的名称:
fswrite: 在Tokio runtime中进行文件写入,使用同步文件IO
fs_write_async: 在Tokio runtime中进行文件写入,使用异步的文件IO
fs_write_thread: 使用单独的线程进行同步文件IO
noload: Tokio runtime上此时没有工作负载
stress: Tokio runtime上此时存在大量工作负载
测试结果分析
以下是测试结果的提琴图。
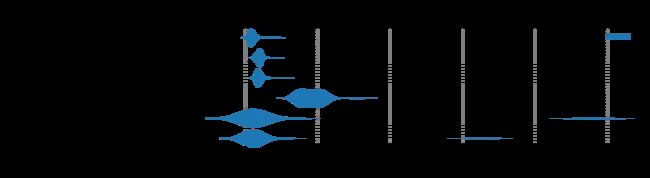
从图中可以看出,当我们在Tokio runtime上使用文件IO,不论是同步还是异步,都会出现不同程度的延迟上升。特别是对于纯粹异步的文件IO,我们可以观察到它的平均延迟出现了大幅度的上升,并且写入延迟的方差也相对增加,这进一步增加了写入延迟的不确定性。符合我们的预期。
05、如何正确实现?
导致我们问题的核心是因为Tokio不支持tasks之间的优先级,这使得更重要的task无法优先得到执行,由于各个task的执行时间是不确定的,在高负载的情况下我们无法准确预测每个任务被重新调度的时间。
如果要在Tokio上实现task的优先级,我们可能就需要使用优先队列来维护各个task之间的优先级,由于Tokio可能需要同时处理数十万甚至上百万的任务,大多数任务本身可能耗时较短,使用优先队列会带来显著的开销。另外一个问题是如果我们需要维护全局任务的优先级,那么各个worker thread之间就会产生较强的竞争,和Tokio work stealing的机制背道而驰,因此是不可行的。因此,如果需要实现调度优先级的特性,前提是用户所需的任务数量较少并且不会有大量短任务,并且优先级只能够在worker threads的本地工作队列中实现以避免竞争。
由于在现有runtime中难以实现开销较低的优先级机制,在使用Tokio runtime时,如果系统存在优先级较高的任务,正确的方式是需要让这些任务运行在单独的线程池中,避免被其他任务饿死,例如我们可以同时运行多个Tokio runtime,或者手动构建自己的线程池。
在Tokio runtime之上编写代码,明确任务的优先级是非常重要的。在我们的用例中, Tonic gRPC server本身会占用大量CPU时间,因此在高负载下很有可能饿死同一runtime下的其他任务,因此需要考虑将CPU-bound的任务和IO-bound的任务分成两个线程池。persistent_task 是位于关键路径上的一个IO任务,它的优先级应当是最高的。所以一个更合适的方式是让 persistent_task 与Tonic所在的runtime隔离开来,对其生成一个独立的系统线程,并使用同步的文件操作,这样就能够获得稳定的延迟。
06、何时能够在Runtime上阻塞
在上面的性能测试的例子中,我们可以发现,即使在Runtime上直接进行同步的文件IO(fs_write)性能也相对较好。可能有人会告诉你,永远不要在runtime上阻塞!例如在Future trait中有一段对Future特性的描述:
"An implementation of poll should strive to return quickly, and should not block."
(https://doc.rust-lang.org/stable/std/future/trait.Future.html#runtime-characteristics)
然而这并非在任何时候都成立,盲目地实现理论上非阻塞的IO反而会对系统性能带来负面影响。
例如,在Xline中,我们使用RocksDB作为底层KV存储引擎。由于rocksdb crate是对C++库的一层包装,本身并不支持异步的接口,很多人会担心使用同步接口会导致阻塞runtime,他们可能会这样使用RocksDB:
{
tokio::task::spawn_blocking(move || {
db.put("foo", "bar").unwrap();
})
.await;
}tokio::task::spawn_blocking 的作用是将阻塞任务生成到runtime的blocking threads上,blocking threads是独立的线程池,因此不会阻塞executor所在的线程池。
对于RocksDB不熟悉的人可能会认为 db.put 涉及到文件操作,所以是阻塞的,这并不完全正确。我们可以构建简单的benchmark来说明这一点。
下面的benchmark向db写入一个由100个key组成的batch,key size = 256bytes, value size = 1024bytes。
完整的测试代码:
https://github.com/bsbds/bench_rocksdb
测试结果:
https://bsbds.github.io/bench_rocksdb/report/
fn rocksdb_benchmark(c: &mut Criterion) {
let mut group = c.benchmark_group("rocksdb_benchmarks");
let rt = build_runtime();
let db = Arc::new(DB::open_default(BENCH_PATH).unwrap());
group.bench_function("rocksdb_write_sync", |b| {
b.to_async(&rt).iter(|| async {
db_write(&db);
})
});
group.bench_function("rocksdb_write_async", |b| {
b.to_async(&rt).iter(|| {
let db_c = Arc::clone(&db);
tokio::task::spawn_blocking(move || db_write(&db_c))
})
});
group.finish();
clean_up();
}在 rocksdb_write_sync 中,直接同步地写入db,而在 rocksdb_write_async 中,使用 spawn_blocking 将同步操作转换为异步写入db。结果如下:

可见我们的异步版本比同步版本慢了46%。这个例子中我们使用RocksDB的同步API实际上是更优的,而如果使用我们转化后的异步版本反而会造成较大的开销。
一个原因是当我们使用 spawn_blocking 运行一个任务时,必定会产生从tokio的worker thread到blocking thread的切换,涉及到两个线程间的数据同步,并且会使得CPU缓存失效,因此这个操作实际上相当昂贵。
使用同步版本的另外一个理由是我们的写操作仅仅花费了数百微秒,这实际上并不能算是一个阻塞操作,RocksDB本身会首先将操作写入到MemTable中,然后通过后台任务异步落盘,因此耗时很短。对于这类时间本身很短的任务如果中途yield到runtime会产生两个问题:
- 由于时间太短,runtime即使在此期间切换到其他任务也无法有效节省CPU时间
- Runtime高负载情况下会导致延迟增加,并且也可能涉及到任务被发送到其他worker线程的情况产生同步成本。
然而,熟悉RocksDB的读者可能会疑惑,RocksDB存在write stalls的现象,并不能保证每次写入都保持稳定的延迟,那么这样使用同步版本会产生问题吗?一般来说,偶尔阻塞Runtime实际上不会对整体性能产生明显影响,例如Tokio实现了work stealing机制,如果一个worker thread被阻塞了,其他的worker threads能够从它的工作队列中偷取任务进行执行,这一定程度上缓解阻塞情况,这对于拥有较多核心的CPU产生的影响是较小的, 而 async-std 中会对阻塞时间较长的任务生成一个新线程,这同样缓解了runtime上偶尔阻塞的问题。
综上所属,调用RocksDB的同步API只是“可能阻塞”,这个可能的概率取决于实际的工作负载,在决定是否需要在Runtime中调用同步的阻塞时,请首先评估系统中阻塞的概率。例如在Xline中,我们主要的目标是运行在拥有现代SSD的机器上,并且Xline的设计吞吐量相对于RocksDB最大吞吐量较低,性能瓶颈并不在RocksDB本身的吞吐上,因此RocksDB几乎不会出现write stalls的现象,此时我们在runtime中同步地调用API就能够实现最佳性能。
07、总结
本文我们主要通过Xline中的两个例子来解释在异步运行时上有关IO性能的问题,以此说明我们不能够盲目依赖runtime本身的调度,而需要对实际的情况进行分析并且设计对应的解决方案。
往期推荐
1. Xline 0.7重构性能分析总述
2. 常见设计模式及其Rust实现
Xline于2023年6月加入CNCF 沙箱计划,是一个用于元数据管理的分布式KV存储。Xline项目以Rust语言写就。感谢每一位参与的社区伙伴对Xline的帮助和支持,也欢迎更多使用者和开发者参与体验和使用Xline。
GitHub链接:
https://github.com/xline-kv/Xline
Xline官网:www.xline.cloud
Xline Discord:
https://discord.gg/kZd9JzQc