seq2seq 代码解析
先上一个seq2seq的图片,有几点需要注意
- 这是两个RNN,编码RNN会将一个序列最后的状态作为解码RNN的初始状态
- 编码的RNN我们是不需要输出,主要是没啥用,但是attention的时候需要
- 解码的RNN是有输入的
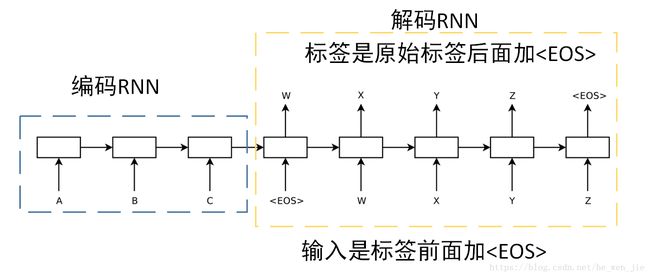
上图的例子就是,一个输入序列是[A,B,C],原始标签是[W,X,Y,Z],编码是我们将序列[A,B,C]依次输入到编码RNN,输完之后得到最终的状态C,解码RNN的输入就是标签前添加[。训练时的标签是[W,X,Y,Z,。
帮助函数
好了可以看看代码了,首先作者实现了一个batch的函数,主要就是对序列PAD和transpose,我就直接放带代码不解释了
def batch(inputs, max_sequence_length=None):
"""
Args:
inputs:
list of sentences (integer lists)
max_sequence_length:
integer specifying how large should `max_time` dimension be.
If None, maximum sequence length would be used
Outputs:
inputs_time_major:
input sentences transformed into time-major matrix
(shape [max_time, batch_size]) padded with 0s
sequence_lengths:
batch-sized list of integers specifying amount of active
time steps in each input sequence
"""
sequence_lengths = [len(seq) for seq in inputs] # inputs是batch,统计有几个序列
batch_size = len(inputs)
if max_sequence_length is None:
max_sequence_length = max(sequence_lengths) # 获取最大长度,为了PAD
inputs_batch_major = np.zeros(shape=[batch_size, max_sequence_length], dtype=np.int32) # == PAD
for i, seq in enumerate(inputs):
for j, element in enumerate(seq):
inputs_batch_major[i, j] = element # 将数据依次填入
# [batch_size, max_time] -> [max_time, batch_size]
inputs_time_major = inputs_batch_major.swapaxes(0, 1) # time_major
return inputs_time_major, sequence_lengths还有一个是batch生成的函数,作者没有用什么具体的数据集,只是随机生成的
def random_sequences(length_from, length_to,
vocab_lower, vocab_upper,
batch_size):
""" Generates batches of random integer sequences,
sequence length in [length_from, length_to],
vocabulary in [vocab_lower, vocab_upper]
"""
if length_from > length_to:
raise ValueError('length_from > length_to')
def random_length():
if length_from == length_to:
return length_from
return np.random.randint(length_from, length_to + 1)
# 生成一个list,长度为batch_size,list的内容是一个序列(其实就是一个list),
# 序列的长度由random_length函数生成,序列值的范围为[vocab_lower,vocab_upper]
# 所以一个batch种序列的长短是不一样的,这很符合实际(赞一个)
while True: # 生成无穷多个batch_size
yield [
np.random.randint(low=vocab_lower,
high=vocab_upper,
size=random_length()).tolist()
for _ in range(batch_size)
] 网络构建
编码部分
开始构建网络,第一步是编码RNN的输入,不知道为什么大家都是time_major,好像是因为这种格式运算会快
# encoder_inputs int32 tensor is shaped [encoder_max_time, batch_size]
encoder_inputs = tf.placeholder(shape=(None, None), dtype=tf.int32, name='encoder_inputs')然后要对输入进行embed,这是因为LSTM输入要求为[max_steps,batch,n_features],但是我们输入[max_steps,batch],我们可以使用tf.one_hot(encoder_inputs),将其编码成[max_steps,batch,n_features],此时n_features=vocab_size,我们知道有时候输入词的种类非常的多,我们要是进行one_hot编码会导致输入非常的大,所以我们可以进行embed,这个其实就是word2vec的想法。假如vocab_size=10000,即输入为 x10000 x 10000 我们让它的维度降到input_embedding_size=100,变成 y100 y 100 我们可以定义一个矩阵 W1000×100 W 1000 × 100 ,使得 y100=x10000W10000×100 y 100 = x 10000 W 10000 × 100 ,大致就是这种想法。
所以要定义一个embeddings的矩阵
embeddings = tf.Variable(
tf.random_uniform([vocab_size, input_embedding_size], -1.0, 1.0), dtype=tf.float32)但是这里有一个问题,我们输入encoder_inputs通常是整数,假如输入有10000种,那么每个值都是 xi<10000 x i < 10000 ,所以我们定义的vocab_size一定要大于等于10000,即 vocab_size>=10000 v o c a b _ s i z e >= 10000 ,如果小的话,有的值就无法正常映射
然后得到新的输入向量 y y
encoder_inputs_embedded = tf.nn.embedding_lookup(embeddings, encoder_inputs)然后开始进行编码,就是常规的RNN,我们只需要final_state,这个要作为解码RNN的零状态输入,outputs我们是完全不需要的。
encoder_cell = tf.nn.rnn_cell.LSTMCell(encoder_hidden_units)
# encoder_outputs : [max_steps, batch_size, encoder_hidden_units]
# encoder_final_state : [batch_size, encoder_hidden_units]
encoder_outputs, encoder_final_state = tf.nn.dynamic_rnn(
encoder_cell, encoder_inputs_embedded,
dtype=tf.float32, time_major=True)
解码部分
下面定义解码的输入
# [encoder_max_time, batch_size]
# 解码RNN的输入
decoder_inputs = tf.placeholder(shape=(None, None), dtype=tf.int32, name='decoder_inputs')
# [decoder_max_time, batch_size] # 标签
decoder_targets = tf.placeholder(shape=(None, None), dtype=tf.int32, name='decoder_targets')很明显,解码RNN也需要输入,所以和编码时一样的,都需要进行embed,通常输入和输出的词的vocab_size时一样的,所以这里共用一个矩阵,但是有时候输入和输出是不一样的,例如OCR,我们先用CNN提取特征向量,然后输入编码RNN,编码RNN输入的是特征,本身就是密集的,不需要embed,而解码RNN输入和输出的都是文字,如果只是英文字母,其实也不需要embed,但是如果标签是中文等,就会很大,需要embed,OCR的例子说明编码RNN什么都不需要做,解码RNN需要进行embed。
decoder_inputs_embedded = tf.nn.embedding_lookup(embeddings, decoder_inputs)定义一个解码RNN
decoder_cell = tf.nn.rnn_cell.LSTMCell(decoder_hidden_units)
# decoder_outputs : [max_steps, batch_size, decoder_hidden_units]
# decoder_final_state : [batch_size, decoder_hidden_units]
decoder_outputs, decoder_final_state = tf.nn.dynamic_rnn(
decoder_cell, decoder_inputs_embedded,
initial_state=encoder_final_state, # 编码RNN的最后状态作为解码RNN的初始状态
dtype=tf.float32, time_major=True, scope="plain_decoder")输出的是解码RNN的神经元个数,我们加一个全连接层,让其输出vocab_size
# decoder_logits : [max_steps, batch_size, vocab_size]
decoder_logits = tf.layers.dense(decoder_outputs, vocab_size)
# decoder_prediction : [max_steps, batch_size]
# 预测的时候vocab_size维度上为单词的概率,取出最大的那个vocab,训练不需要
decoder_prediction = tf.argmax(decoder_logits, 2) 优化
stepwise_cross_entropy = tf.nn.softmax_cross_entropy_with_logits(
labels=tf.one_hot(decoder_targets, depth=vocab_size, dtype=tf.float32),
logits=decoder_logits)
loss = tf.reduce_mean(stepwise_cross_entropy)
train_op = tf.train.AdamOptimizer().minimize(loss)可以看到我们对标签进行了one_hot编码,这是因为最后我们输出的概率是每个词的概率,有10000个词就会有10000个概率,为了计算交叉熵,我们需要对其进行one_hot编码,当然我们也可以使用tf.nn.sparse_softmax_cross_entropy_with_logits函数。
stepwise_cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=decoder_targets, logits=decoder_logits)到这里整个网络就构建完成了,下面就是作者给的几个不知道什么例子的例子
首先产生一些数据吧,序列的长度从3到8,序列的值从2到10,batch_size=100
batch_size = 100
batches = helpers.random_sequences(length_from=3, length_to=8,
vocab_lower=2, vocab_upper=10,
batch_size=batch_size)
print('head of the batch:')
for seq in next(batches)[:10]:
print(seq)下一步很重要,是关于数据和标签的,一定要记住,解码label是原始label后加
def next_feed():
batch = next(batches) # 因为batches是迭代的,我们需要next才能取值,得到一个batch的序列
encoder_inputs_, _ = helpers.batch(batch) # 对每一个batch的数据进行pad和transpose
# 标签和输入一样,即输入什么,输出也是什么,但是上面说过,解码标签需要在原始标签后面添加编码输入是[5, 6, 7],label和输入一样[5, 6, 7],但是解码需要的label是[5, 6, 7, 1],这里1代表[1, 5, 6, 7]。
然后就是训练了,没啥东西了
max_batches = 3001 # 因为原来的batch生成器是while,没有停止条件,这里设置数据有max_batches个
batches_in_epoch = 1000
try:
for batch in range(max_batches):
fd = next_feed() # 获取下一个batch
_, l = sess.run([train_op, loss], fd) # 优化
loss_track.append(l)
if batch == 0 or batch % batches_in_epoch == 0:
print('batch {}'.format(batch))
print(' minibatch loss: {}'.format(sess.run(loss, fd)))
predict_ = sess.run(decoder_prediction, fd)
for i, (inp, pred) in enumerate(zip(fd[encoder_inputs].T, predict_.T)):
print(' sample {}:'.format(i + 1))
print(' input > {}'.format(inp))
print(' predicted > {}'.format(pred))
if i >= 2:
break
print()
except KeyboardInterrupt:
print('training interrupted')
plt.plot(loss_track)
print('loss {:.4f} after {} examples (batch_size={})'.format(loss_track[-1], len(loss_track)*batch_size, batch_size)最后的可执行代码
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
tf.reset_default_graph()
vocab_size=10
input_embedding_size=11
encoder_hidden_units = 32
decoder_hidden_units = 32
batch_size = 100
EOS = 1
def create_batch(inputs, max_sequence_length=None):
"""
Args:
inputs:
list of sentences (integer lists)
max_sequence_length:
integer specifying how large should `max_time` dimension be.
If None, maximum sequence length would be used
Outputs:
inputs_time_major:
input sentences transformed into time-major matrix
(shape [max_time, batch_size]) padded with 0s
sequence_lengths:
batch-sized list of integers specifying amount of active
time steps in each input sequence
"""
sequence_lengths = [len(seq) for seq in inputs] # inputs是batch,统计有几个序列
batch_size = len(inputs)
if max_sequence_length is None:
max_sequence_length = max(sequence_lengths) # 获取最大长度,为了PAD
inputs_batch_major = np.zeros(shape=[batch_size, max_sequence_length], dtype=np.int32) # == PAD
for i, seq in enumerate(inputs):
for j, element in enumerate(seq):
inputs_batch_major[i, j] = element # 将数据依次填入
# [batch_size, max_time] -> [max_time, batch_size]
inputs_time_major = inputs_batch_major.swapaxes(0, 1) # time_major
return inputs_time_major, sequence_lengths
def random_sequences(length_from, length_to,
vocab_lower, vocab_upper,
batch_size):
""" Generates batches of random integer sequences,
sequence length in [length_from, length_to],
vocabulary in [vocab_lower, vocab_upper]
"""
if length_from > length_to:
raise ValueError('length_from > length_to')
def random_length():
if length_from == length_to:
return length_from
return np.random.randint(length_from, length_to + 1)
# 生成一个list,长度为batch_size,list的内容是一个序列(其实就是一个list),
# 序列的长度由random_length函数生成,序列值的范围为[vocab_lower,vocab_upper]
# 所以一个batch种序列的长短是不一样的,这很符合实际(赞一个)
while True: # 生成无穷多个batch_size
yield [
np.random.randint(low=vocab_lower,
high=vocab_upper,
size=random_length()).tolist()
for _ in range(batch_size)
]
# encoder_inputs int32 tensor is shaped [encoder_max_time, batch_size]
encoder_inputs = tf.placeholder(shape=(None, None), dtype=tf.int32, name='encoder_inputs')
embeddings = tf.Variable(
tf.random_uniform([vocab_size, input_embedding_size], -1.0, 1.0), dtype=tf.float32)
encoder_inputs_embedded = tf.nn.embedding_lookup(embeddings, encoder_inputs)
encoder_cell = tf.nn.rnn_cell.LSTMCell(encoder_hidden_units)
# encoder_outputs : [max_steps, batch_size, encoder_hidden_units]
# encoder_final_state : [batch_size, encoder_hidden_units]
encoder_outputs, encoder_final_state = tf.nn.dynamic_rnn(
encoder_cell, encoder_inputs_embedded,
dtype=tf.float32, time_major=True)
# [encoder_max_time, batch_size]
# 解码RNN的输入
decoder_inputs = tf.placeholder(shape=(None, None), dtype=tf.int32, name='decoder_inputs')
# [decoder_max_time, batch_size] # 标签
decoder_targets = tf.placeholder(shape=(None, None), dtype=tf.int32, name='decoder_targets')
decoder_inputs_embedded = tf.nn.embedding_lookup(embeddings, decoder_inputs)
decoder_cell = tf.nn.rnn_cell.LSTMCell(decoder_hidden_units)
# decoder_outputs : [max_steps, batch_size, decoder_hidden_units]
# decoder_final_state : [batch_size, decoder_hidden_units]
decoder_outputs, decoder_final_state = tf.nn.dynamic_rnn(
decoder_cell, decoder_inputs_embedded,
initial_state=encoder_final_state, # 编码RNN的最后状态作为解码RNN的初始状态
dtype=tf.float32, time_major=True, scope="plain_decoder")
# decoder_logits : [max_steps, batch_size, vocab_size]
decoder_logits = tf.layers.dense(decoder_outputs, vocab_size)
# decoder_prediction : [max_steps, batch_size]
# 预测的时候vocab_size维度上为单词的概率,取出最大的那个vocab,训练不需要
decoder_prediction = tf.argmax(decoder_logits, 2)
stepwise_cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=decoder_targets, logits=decoder_logits)
loss = tf.reduce_mean(stepwise_cross_entropy)
train_op = tf.train.AdamOptimizer().minimize(loss)
batches = random_sequences(length_from=3, length_to=8,
vocab_lower=2, vocab_upper=10,
batch_size=batch_size)
def next_feed():
batch = next(batches) # 因为batches是迭代的,我们需要next才能取值,得到一个batch的序列
encoder_inputs_, _ = create_batch(batch) # 对每一个batch的数据进行pad和transpose
# 标签和输入一样,即输入什么,输出也是什么,但是上面说过,解码标签需要在原始标签后面添加总结
最后对代码的套路进行总结
1. 数据
- 数据是batch输入的,RNN要求每个batch的序列的长度必须是一致的,因此需要对一个batch的序列进行pad
- 解码时的标签和输入需要添加
2. 编码
1.首先定义编码的输入,
encoder_inputs = tf.placeholder(shape=(None, None), dtype=tf.int32, name='encoder_inputs')2.定义embed矩阵
embeddings = tf.Variable(
tf.random_uniform([vocab_size, input_embedding_size], -1.0, 1.0), dtype=tf.float32)3.对输入进行embed
encoder_inputs_embedded = tf.nn.embedding_lookup(embeddings, encoder_inputs)4.定义RNN结构
encoder_cell = tf.nn.rnn_cell.LSTMCell(encoder_hidden_units)5.执行RNN,得到输出和状态,最终状态作为解码RNN的初始状态
encoder_outputs, encoder_final_state = tf.nn.dynamic_rnn(
encoder_cell, encoder_inputs_embedded,
dtype=tf.float32, time_major=True)3. 解码
1.首先定义解码的输入和标签,
decoder_inputs = tf.placeholder(shape=(None, None), dtype=tf.int32, name='decoder_inputs')
decoder_targets = tf.placeholder(shape=(None, None), dtype=tf.int32, name='decoder_targets')2.编码解码使用同一embed矩阵,对输入进行embed
encoder_inputs_embedded = tf.nn.embedding_lookup(embeddings, encoder_inputs)3.定义解码RNN结构,可以和编码不同
encoder_cell = tf.nn.rnn_cell.LSTMCell(encoder_hidden_units)4.执行RNN,得到输出和状态
encoder_outputs, encoder_final_state = tf.nn.dynamic_rnn(
encoder_cell, encoder_inputs_embedded,
dtype=tf.float32, time_major=True)5.定义全连接层,得到softmax
decoder_logits = tf.layers.dense(decoder_outputs, vocab_size)
decoder_prediction = tf.argmax(decoder_logits, 2) 4. 优化
stepwise_cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=decoder_targets, logits=decoder_logits)
loss = tf.reduce_mean(stepwise_cross_entropy)
# 梯度裁剪
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
gvs = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gvs]
train_op = optimizer.apply_gradients(capped_gvs)tensorflow-seq2seq-tutorials