Hadoop大数据开发基础系列:五、MapReduce进阶编程
五、MapReduce进阶编程
目录:
1.筛选日志文件并生成序列化文件
2.Hadoop Java API读取序列化日志文件
3.优化日志文件统计程序
4.Eclipse提交日志文件统计程序
5.小结
6.实训
7.小练习
任务背景:网站运营方又提出来新的需求,为了比较今年与去年同期的用户访问数据,要求分别统计出2016年1月与2月的用户访问次数,并输出到不同的目录中。在本章中,将引入一些高级的编程技巧,使得整体编程更加高效实用。
第一个任务:在大数据文件分析处理中,尤其是在处理逻辑比较复杂的情况下,要使用多个MapReduce程序来连续进行处理,就需要在HDFS上保存大量的中间结果。如何提高中间结果的存取效率,对于整个数据处理流程是很有意义的。Hadoop序列化具有紧凑、快速、可扩展以及互操作的特点,非常适合MapReduce任务的输入与输出格式。首要任务就是从原数据中筛选出1月与2月的数据,以序列化文件的格式存储,为后续的数据处理任务做准备。
第二个任务:简要了解javaAPI的基本操作和应用。通过JavaAPI对HDFS中的文件进行操作,它不但能够轻松处理各类常规的文件操作,而且还提供了多种文件类型接口,能够轻松处理文本、键值对、序列化等多种文件格式。
第三个任务:在实际任务中,数据结构与逻辑更为复杂,键或值可能是由多个元素组成的,那么就需要用户根据情况自定义键值对的类型。Map端的输出结果是经过网络传输到Reduce端的。当Map端的输出数据量特别大时,网络传输可能成为影响处理效率的一大因素。为了提高整体处理效率,Hadoop提供了用于优化组件Combiner与Partitioner,可以帮助数据在传到Reducer之前进行一系列的合并和分区处理。另外,Hadoop提供了执行MapReduce程序过程中的计数功能,用户也可以根据需要进行个性化的计数设置。现在要编程实现2016年1月与2月的用户访问次数统计,并在编程过程中使用自定义的键值对类型、组件Combiner与Partitioner、自定义计数器等模块,有利于对Hadoop编程有更加深刻的认识。
第四个任务:学会MapReduce任务在工作环境中的实际提交流程,就是在Eclipse中直接向Hadoop提交MapReduce任务,而且显示执行过程中的输出日志。
1.筛选日志文件并生成序列化文件
任务:以序列化文件的格式输出筛选的数据。
1.1 MapReduce输入格式
(1)Hadoop自带了多个输入格式,其中一个抽象类为FileInputFormat,所有操作文件的InputFormat类都是从它那里继承方法和属性。当启动hadoop时,FileInputFormat会得到一个路径参数,这个路径包含了所需要处理的文件,FileInputFormat会读取这个文件夹内的所有文件,然后会把这些文件拆分为一个或多个InputSplit。下图为InputFormat的类继承结构:
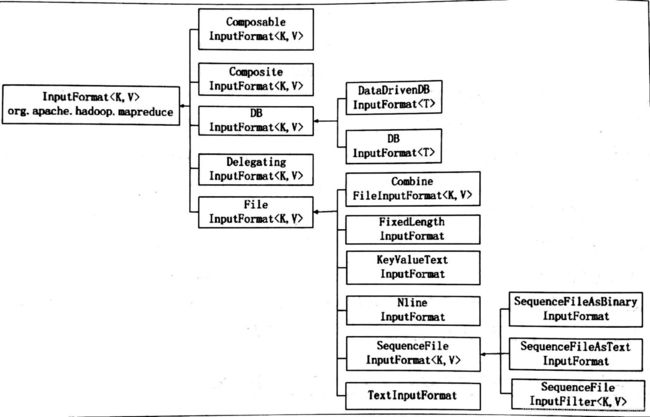
其中TextInputFormat是默认的inputformat。
(2)Hadoop的MapReduce不仅可以处理文本信息,还可以处理二进制格式的数据,二进制格式也成为序列化格式,Hadoop的序列化有以下特点:
①紧凑:高效使用存储空间 ②快速:读取数据的额外开销少
③可扩展:可透明的读取旧格式的数据 ④互操作:可以使用不同的语言读/写永久存储的数据
处理序列化数据需要使用SequenceFileInputFormat来作为MapReduce的输入格式。
(3)常用的inputformat的输入格式:
| 输入格式 |
描述 |
键类型 |
值类型 |
| TextInputFormat |
默认格式,读取文件的行 |
行的字节偏移量(LongWriable) |
行的内容(Text) |
| SequenceFileInputFormat |
Hadoop定义的高性能二进制格式 |
用户自定义 |
|
| KeyValueInputFormat |
把行解析为键值对 |
第一个tab字符前的所有字符 |
行剩下的所有内容(Text) |
设置MapReduce输入格式,可在驱动类中使用Job对象的setInputFormat()方法。例如,我们要读取社交网站2016年用户登录的信息,要设定输入对象为TextInputFormat,可以在驱动类中设置以下代码:
job.setInputFormat(TextInputFormat.class)
由于TextInputFormat是默认的输入格式,所以当输入格式是TextInputFormat时,驱动类可以不设置输入格式。但是要使用其他的输入格式,就要在驱动类中设置输入格式。
1.2 MapReduce输出格式
(1)针对上一小节介绍的输入格式,Hadoop都有对应的输出格式。输出格式实际上是输入格式的逆过程,即把键值对写入HDFS的文件块内。下图为OutputFormat类的继承构造:
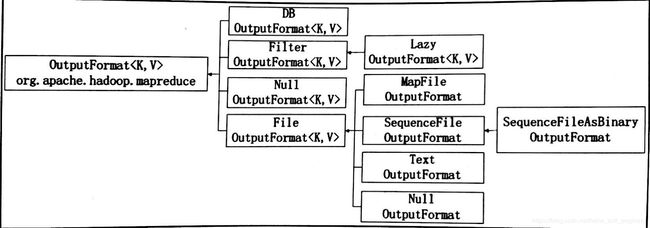
默认的输出格式是TextOutputFormat,它把每一条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把他们转换为字符串。每个键值对由制表符进行分割,当然也可以通过设定mapreduce.output.textoutputformat.separator属性来改变默认的分隔符。
(2)下表列出了常用的输出格式类:
| 输出格式 |
描述 |
| TextOutputFormat |
默认的输出格式,以“key \t value”的方式输出行 |
| SequenceFileOutputFormat |
输出二进制文件,适合作为子MapReduce作业的输入 |
| NullOutputFormat |
忽略收到的数据,即不做输出 |
如果作为后续MapReduce任务的输入,那么序列化输入是一种好的输入格式,因为它的格式紧凑,很容易被压缩。本节任务需要将筛选出来的数据以序列化的格式输出,只需要在驱动类中添加以下代码:
job.setOutputFormat(SequenceFileOutputFormat.class)1.3 任务实现(完成前述第一个任务)
(1)实现步骤:
①以文本格式读取文件 ②在map函数里判断读取进来的数据是否是1月或2月的数据。若是,则将该条数据输出;若不是,则不输出
③以序列化的格式输出数据。本人无只需要Mapper类就可以完成,即Map端的输出可以直接输出到HDFS,因此本任务不必设置Reducer类,即在驱动类中设置Reducer的个数为0。
(2)①代码:
package test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;;
public class SelectData {
public static class SelectDataMapper extends Mapper{
protected void map(LongWritable key,Text value,Mapper.Context context)
throws IOException,InterruptedException{
String[] val=value.toString().split(",");
//过滤选取1月份和2月份的数据
if(val[1].contains("2016-01") || val[1].contains("2016-02")) {
context.write(new Text(val[0]), new Text(val[1]));
}
}
}
public static void main(String[]args) throws IOException,
ClassNotFoundException,InterruptedException{
Configuration conf=new Configuration();
Job job=Job.getInstance(conf,"selectdata");
job.setJarByClass(SelectData.class);
job.setMapperClass(SelectDataMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);//设置输入格式
job.setOutputFormatClass(SequenceFileOutputFormat.class);//设置输出格式
job.setNumReduceTasks(0);//设置Reducer的任务数为0
FileInputFormat.addInputPath(job, new Path(args[0]));
FileSystem.get(conf).delete(new Path(args[1]),true);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.err.println(job.waitForCompletion(true)?-1:1);
}
} ②执行并查看结果:
hadoop jar selectdata.jar test.SelectData /user/dftest/user_login.txt /user/dftest/Selectdata
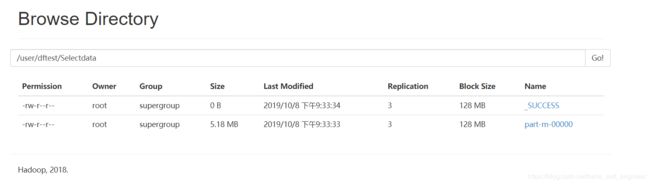
③记事本打开是(记事本对数据进行了解析):

由 sublime打开是二进制文件:
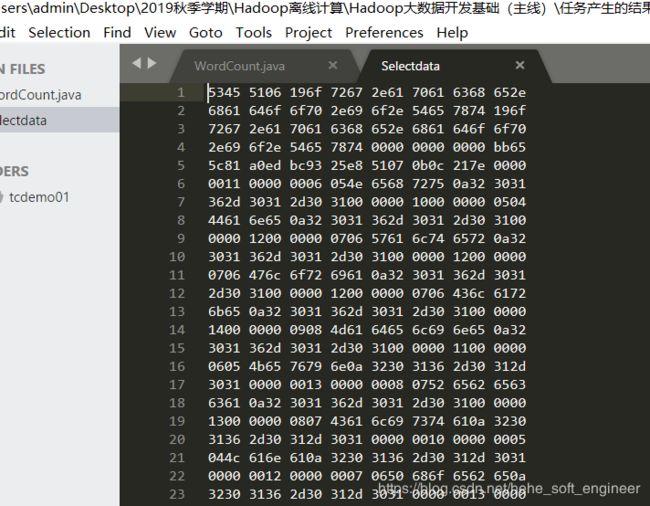
序列化输出完成。
2.Hadoop Java API读取序列化日志文件
本节将使用Hadoop Java API的方式读取该序列化文件,并将读取的数据保存到本地文件系统中,查看内容是否为1月和2月的用户登录信息。
2.1 FileSystem API 管理文件
(1)FileSystem是一个通用的文件管理系统API,使用它的第一步是需要先获取它的一个实例,下面给出了几个获取FileSystem实例的静态方法:
public static FileSystem get(Configuration conf) throws IOException
public static FileSystem get(URI uri,Configuration conf) throws IOException
public static FileSystem get(URI uri,Configuration conf,String user) throws IOException(2)Configuration 对象封装了客户端或服务器端的配置信息,下面说明以上三个方法:
①第一个方法返回了一个默认的文件系统,是在core-site.xml中通过fs.defaultFS来指定的,如果在core-site.xml中没有设置,则返回本地的文件系统。
②第二个方法是通过uri来指定要返回的文件系统。如果uri是以hdfs标识开头,那么久返回一个HDFS文件系统;如果uri中没有相应的标识,则返回本地文件系统。
③第三个方法返回文件系统的原理与②相同,但它同时又限定了该文件系统的用户,在这方面是很重要的。
通过查看FileSystem的API可以找到FileSystem类的相关方法。
(3)举例:
| 修饰符和类型 |
方法 |
| abstract FileStatus[] |
listStatus(Path f) |
| FileStatus[] |
listStatus(Path[] files) |
| FileStatus[] |
listStatus(Path[] files,PathFilter filter) |
| FileStatus[] |
listStatus(Path f,PathFilter filter) |
以上方法返回的是一个文件列表。
①列举文件夹示例代码:
//获取配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS","172.16.29.76:8020");
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//指定要查看的文件目录
Path path = new Path("/user/dftest");
//获取文件列表
FileStatus[] filesatus = fs.listStatus(path);
//遍历文件列表
for (FileStatus file: filestatus) {
//判断是否为文件夹
if( file.isDirectory() ){
System.out.printlin( file.getPath().toString() );
}
}
//关闭文件系统
fs.close();首先要设置Configuration来获取集群配置,然后指定集群内的hdfs文件目录
②与列举目录下的文件夹方式类似,可以使用同样的方法去遍历一个文件夹下面的所有文件。代码如下:
//获取配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS","172.16.29.76:8020");
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//指定要查看的文件目录
Path path = new Path("/user/dftest");
//获取文件列表
FileStatus[] filesatus = fs.listStatus(path);
//遍历文件列表
for (FileStatus file: filestatus) {
//判断是否为文件夹
if( file.isFile() ){
System.out.printlin( file.getPath().toString() );
}
}
//关闭文件系统
fs.close();(4)用FileSystem API 创建目录
| 修饰符和类型 |
方法 |
| static boolean |
mkdirs(FileSystem fs,Path dir,FsPermission permission) |
| boolean |
mkdirs(Path f) |
| abstract boolean |
mkdirs(Path f,FsPermission permission) |
相关参数:fs:文件系统对象 dir:要创建的目录名称 permission:为该目录设置的权限
任务:使用mkdirs(Path f)方法在HDFS上创建目录/user/dftest/loginmessage
代码示例如下:
//获取配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS","172.16.29.76:8020");
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//声明要创建的文件目录
Path path = new Path("/user/dftest/loginmessage");
//调用mkdirs函数创建目录
fs.mkdirs(path);
//关闭文件系统
fs.close();2.2 FileSystem API 操作文件
(1)删除文件:
这里主要介绍delete方法
| 修饰符和类型 |
方法 |
| boolean |
delete(Path f) |
| abstract boolean |
delete(Path f,boolean recursive) |
相关参数:f 要删除的文件路径 recursive 如果路径是一个目录且不为空,要把recursive设置为true,否则会报出异常。在如果是文件的话,此值true或false均可。
使用delete(Path f,boolean recursive)删除HDFS上的/user/dftest/user_login.txt文件,具体实现代码如下:
//获取配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS","172.16.29.76:8020");
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//声明要删除的文件或目录
Path path = new Path("/user/dftest/user_login.txt");
//调用mkdirs函数创建目录
fs.delete(path,true);
//关闭文件系统
fs.close();(2)上传与下载文件:(示例代码用的方法是蓝色标注的方法,结构与上面的代码类似,只是注明参数即可)
①本地上传文件:
| 修饰符和类型 |
方法 |
| void |
copyFromLocalFile(boolean delSrc,boolean overwrite,Path[] srcs,Path dst) |
| void |
copyFromLocalFile(boolean delSrc,boolean overwrite,Path srcs,Path dst) |
| void |
copyFromLocalFile(boolean delSrc,Path srcs,Path dst) |
| void |
copyFromLocalFile(Path srcs,Path dst) |
②下载到本地:
| 修饰符和类型 |
方法 |
| void |
copyToLocalFile(boolean delSrc,Path src,Path dst) |
| void |
copyToLocalFile(boolean delSrc,Path src,Path dst,boolean useRawLocalFileSystem) |
| void |
copyToLocalFile(Path src,Path dst) |
相关参数 :delSrc:是否删除源文件 overwrite:是否覆盖已经存在的文件 srcs:存储源文件目录的数组
dst:目标路径 src:源文件路径 useRawLocalFileSystem:是否使用原始文件系统作为本地文件系统
2.3 FileSystem API 读写数据
(1)查看文件内容
Hadoop Java API 提供了一个获取指定文件的数据字节流的方法——open()。该方法返回的是FSDataInputStream对象。
| 修饰符和类型 |
方法 |
| FSDataInputStream |
open(Path f) |
| abstract FSDataInputStream |
open(Path f,int bufferSize) |
相关参数:f :要打开的文件 bufferSize:要使用的缓冲区大小
示例:读取HDFS上的文件/user/dftest/loginmessage/user_login.txt的内容,具体实现代码如下:
//获取配置
Configuration conf = new Configuration();
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//声明要查看的文件路径
Path path = new Path("/user/dftest/loginmessage/user_login.txt");
//获取指定文件的数据字节流
FSDataInputStream is = fs.open(path);
//读取文件内容并打印出来
BufferedReader br=new BufferedReader(new InputStreamReader(is,"utf-8"));
String line="";
while((line=br.readline())!=null){
System.out.println(line);
}
//关闭数据字节流
br.close();
is.close();
//关闭文件系统
fs.close();(2)写入数据
与读取数据类似,写入数据的实现可以理解为读取数据的逆向过程。向HDFS写入数据首先需要创建一个文件,FileSystem类提供了多种方法来创建文件。最常用的就是调用以创建文件的Path对象为参数的create(Path f)方法。除了创建一个新文件来写入数据,还可以用append()方法向一个已存在的文件添加数据。
示例:在/user/dftest/loginmessage/user_login.txt目录下创建文件new_user_login.txt,读取该目录下的user_login.txt文件并写入新文件new_user_login.txt中,具体实现代码如下:
//获取配置
Configuration conf = new Configuration();
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//声明要查看的文件路径
Path path = new Path("/user/dftest/loginmessage/user_login.txt");
//创建新文件
Path newpath=new Path("/user/root/loginmessage/new_user_login.txt");
fs.delet(newpath);
FSDataOutputStream os=fs.create(newPath);
//获取指定文件的数据字节流
FSDataInputStream is = fs.open(path);
//读取文件内容并写入到新文件
BufferedReader br=new BufferedReader(new InputStreamReader(is,"utf-8"));
BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(os,"utf-8"));
String line="";
while((line=br.readline())!=null){
bw.write(line);
bw.newLine();
}
//关闭数据字节流
bw.close();
os.close();
br.close();
is.close();
//关闭文件系统
fs.close();
2.4 任务实现(完成前述第二个任务)
(1) Hadoop Java API提供了读取HDFS上的文件的方法,当然也可以读取序列化文件。不同于普通问件的读取方法,读取序列化文件需要获取到SequenceFile.Reader对象。下表给出了该对象提供的几个重要方法。
| 方法 |
描述 |
| getKeyClassName() |
返回序列化文件中的键类型 |
| getValueClassName() |
返回序列化文件中的值类型 |
| next(Writable key) |
读取该文件中的键,如果存在下一个键,则返回true,读到文件末尾则返回false |
| next(Writable key,Writable value) |
读取文件中的键和值,如果存在下一个键值,则返回true,读到文件末尾返回false |
| toString() |
返回文件的路径名称 |
(2) 读取序列化文件
main函数部分代码如下:
//获取配置
Configuration conf = new Configuration();
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//获取SequenceFile.Reader对象
SequenceFile.Reader reader=new SequenceFile.Reader(fs,new Path("/user/dftest/Selectdata/part-m-00000"),conf);
//获取序列化文件中使用的键值类型
Text key = new Text();
Text value=new Text();
//读取的数据写入selectdata.txt文件
BufferedWriter out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("C:\\Users\\Admin\\desktop\\selectdata.txt",true)));
while(reader.next(key,value)){
out.write(key.toString()+"\t"+value.toString()+"\r\n");
}
out.close();
reader.close();读取结果如下(截取的部分数据):
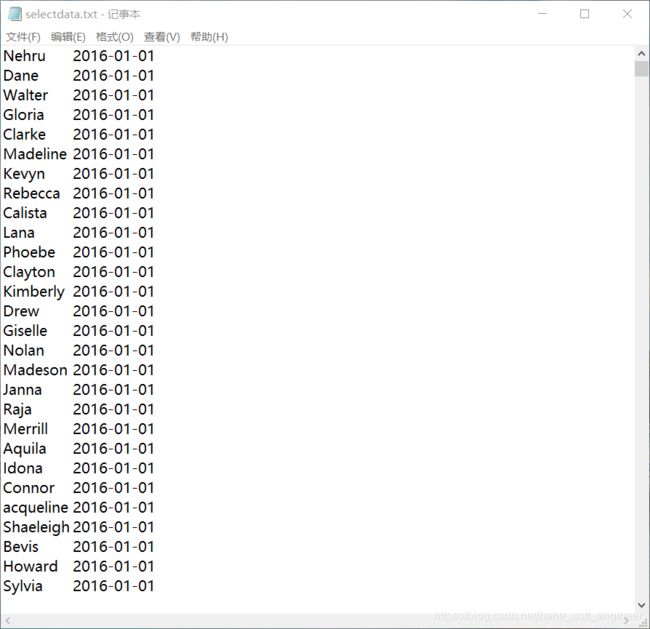
3.优化日志文件统计程序
任务1中筛选了1.2月份的用户登录信息,并生成了序列化文件,本节任务就是使用MapReduce读取该序列化文件,统计在2016年1.2月份每天的登录次数,并且要求最终的输出结果根据月份分别保存到两个不同的文件中。同时要求分别统计输入记录中1月份和2月份的记录数以及输出结果中1月份和2月份的记录数。
3.1 自定义键值类型
在Hadoop中,mapper和reducer处理的都是键值对记录。Hadoop提供了很多键值对类型,如Text、IntWritable、LongWritable等。
下图为Hadoop内置的数据类型:
下面对常用的集中数据类型进行详细解析:
| 类型 |
解释 |
| BooleanWritable |
标准布尔型,相当于java数据里面的boolean,当 |
| ByteWritable |
单字节型,相当于Java数据类型里面的byte,当 |
| DoubleWritable |
双精度浮点型,相当于Java数据类型里面的double,当 |
| FloatWritable |
单精度浮点型,相当于Java数据类型里面的float,当 |
| IntWritable |
整型,相当于Java数据类型里面的int,当 |
| LongWritable |
长整型,相当于Java数据类型里面的Long,当 |
| Text |
使用UTF-8格式存储文本,在java数据中主要针对String类型 |
| NullWritable |
空值,当 |
Hadoop内置的数据类型可以满足绝大多数需求。但有时,用户需要一些特殊的键值类型来满足业务需求,即自定义键值类型。
①自定义值类型必须实现Writable接口,接口Writable是一个简单高效的基于基本I/O的序列化接口对象,包含两个方法,即write(DataOutput out)与readFields(DataInput in),其功能分别是将数据写入指定的流中和从指定的流中读取数据。下表为对这两个方法的描述。自定义值类型必须实现这两个方法。
| 返回类型 |
方向和描述 |
| void |
readFields(DataInput in),从in中反序列化该对象的字段 |
| void |
write(DataOuput out),将该对象的字段序列化到out中 |
②自定义键类型必须实现WritableComparable接口。WritableComparable接口自身又实现了Wriable接口,所以Hadoop中的键也可以作为值使用,但是实现Writable接口不能作为键使用。WritableComparable接口中不仅有readFields(DataInput in)方法和write(DataOutput out)方法,还提供了一个compareTo(To)方法,该方法提供了3种返回类型,如下表:
| 返回类型 |
解释 |
| 负整数 |
表示小于被比较对象 |
| 0 |
表示等于被比较对象 |
| 正整数 |
表示大于被比较对象 |
无论是自定义键类型还是自定义值类型,自定义的类默认继承object类,而object类默认有一个toString方法,该方法返回的是对象的内存地址。但有时候用户想要看到的是该对象的具体内容,而不是内存地址,这个时候就需要重写toString方法。重写方法只需要返回自己想要的字符串即可。
③下面具体介绍如何完整地自定义一个键值类型:
本节任务是统计用户每天登录的次数,输入的数据包含两列信息,用户名和登录日期。Mapper输出的键是用户名及登录日期,输出的值是1;Reducer输出的键也是登录名和日期,输出的值是每个用户每天登录的次数。由此可以看出,Mapper和Reducer输出的值类型使用Hadoop内置的IntWritable类型即可,而键类型可以自己定义。定义一个MemberLogTime类,该类实现接口WritableComparable
自定义键类型代码如下所示:
package essential;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class MemberLogTime implements WritableComparable {
private String member_name;
private String logTime;
public MemberLogTime(){
}
public MemberLogTime(String member_name,String logTime){
this.member_name=member_name;
this.logTime=logTime;
}
public String getLogTime() {
return logTime;
}
public void setLogTime(String logTime) {
this.logTime = logTime;
}
public String getMember_name() {
return member_name;
}
public void setMember_name(String member_name) {
this.member_name = member_name;
}
/*关键是对下面三个方法进行重写实现
*
* */
@Override
public void readFields(DataInput dataInput) throws IOException {
this.member_name=dataInput.readUTF();
this.logTime=dataInput.readUTF();
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(member_name);
dataOutput.writeUTF(logTime);
}
@Override
public int compareTo(MemberLogTime o) {
return this.getMember_name().compareTo(o.getMember_name());
}
public String toString(){
return this.member_name+","+this.logTime;
}
} 3.2 初步探索Combiner
为了提高MapReduce作业的工作效率,Hadoop允许用户声明一个Combiner。Combiner是运行在Map端的一个“迷你Reducer”过程,它只处理单台机器生成的数据。
(1)声明的Combiner继承的是Reducer,其方法原理和Reduce的实现原理基本相同。不同的是,Combiner操作发生在Map端,或者说Combiner运行在每一个运行Map任务的节点上。它会接收特定节点上的Map输出作为输入,对Map输入的数据先做一次合并,再把输出结果发送到Reducer。需要注意的是,combiner不影响程序的处理逻辑,只会影响处理效率。
所有节点的Mapper输出都会传送到Reducer,当数据集很大时,Reduce端也会接收大量的数据,这样无疑会增加Reducer的负担,影响Reducer的工作效率。当加入Combiner时,每个节点的Mapper输出现在Combiner上进行整合,Combiner先对Mapper输出进行计算,然后将计算结果传输给Reducer,这样Reducer端接收到的数据量就会大大减少,提高效率。
下图为有无Combiner的对比图:
值得一提的是:并非所有的MapReduce程序都可以加入Combiner。仅当Reducer输入的键值对类型与Reducer输出的键值对类型一样,并且计算逻辑不影响最终的结果时才可以在MapReduce程序中加入Combiner。例如,统计求和或者求最大值时可以使用Combiner,但是类似计算平均值时就不能使用Combiner。
(2)Combiner继承的是Reducer,所以声明Combiner类的继承必须继承Reducer,在Combiner类里面重写reduce方法。下面代码展示了统计社交网站2016年1月和2月用户每天登录该网站次数的Combiner代码。
package essential;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LogCountCombiner extends Reducer {
protected void reduce(MemberLogTime key,Iterable value,
Reducer.Context context)
throws IOException, InterruptedException {
int sum=0;
for(IntWritable iw:value){
sum+=iw.get();
}
context.write(key,new IntWritable(sum));
}
} 除了声明Combiner类外,还需要在驱动类里面配置Combiner类,如下所示:
job.setCombinerClass(LogCountCombiner.class);有时候甚至不需要特意声明一个Combiner类。当Combiner与Reducer实现逻辑相同时,可以不用声明Combiner类,在驱动类里面添加以下代码即可:
job.setCombinerClass(LogCountReducer.class);3.3 浅析Partitioner
(1)下面先给出MapReduce的执行过程
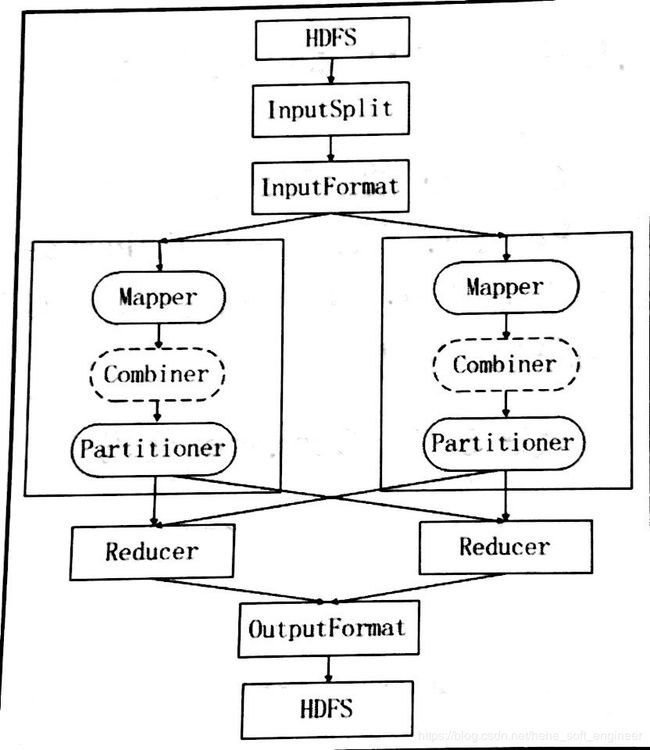
数据首先上传到HDFS并且被分成文件块,接着MapReduce框架根据输入的文件计算输入分片,每个输入分片对应一个Map任务。Map在读取分片数据之前,InputFormat会将分片中的每条记录解析成键值对格式供Map读取。Map的输出结果可能会先传送到Combiner进行合并,而Combiner的输出结果会被Partitioner均匀地分配到每个Reducer上,Reducer的输出结果又会通过OutputFormat解析成特定的格式存储到HDFS上。在这个过程中,Combiner和Partitioner并非必须的,Combiner和Partitioner的使用需要根据实际业务需求来定。
(2)下面对Partitioner进行详细介绍:
Partitioner组件的功能是让Map对key进行分区,从而将不同的key分发到不同的Reducer中进行处理。分区阶段发生在Map阶段之后,Reduce阶段之前,分区的数量等于Reducer的个数。Reducer的个数可以在驱动类里面通过job.setNumReduceTasks设置。在使用多个Reducer的情况下,需要一些方法来确保Mapper输出的键值对发送到正确的Reducer中。
Hadoop自带了一个默认的分区实现,即HashPartitioner。HashPartitioner的实现很简单,它继承了Partitioner
一般情况下,MapReduce程序都会使用默认的HashPartitioner分区,但有时候用户会有一些特殊的需求,例如,统计某社交网站2016年1月和2月用户每天登录的次数,要求1月份的输出结果放到一个文件里,2月份的输出结果放在一个文件里。这个时候就需要自定义Partition来实现这个要求。
(3)下面开始实现自定义Partition
自定义Partitioner需要继承Partitioner
package essential;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class LogCountPartitioner extends Partitioner {
@Override
public int getPartition(MemberLogTime key, IntWritable value, int numberPartitions) {
String date=key.getLogTime();
if(date.contains("2016-01")){
return 0/numberPartitions;
}else {
return 1/numberPartitions;
}
}
} 在main函数实现设置Partitioner类和设置Reducer个数
job.setPartitionerClass(LogCountPartitioner.class);
job.setNumReduceTask(2);//这样就可以控制Reducer输出的文件及数据分区了3.4 自定义计数器
在Hadoop的运行日志中可以获取到Map和Reduce的任务数、运行Map任务花费的时间、运行Reduce任务花费的时间,以及Map、Combiner和Reduce的输入输出记录等。这些信息都是Hadoop自带的计数器统计出来的。
(1)概述:计数器是Hadoop框架使用的一种对统计信息收集的手段,主要应用于对数据的控制及收集统计信息。计数器可以帮助程序设计人员手机某一类特定的信息数据。一般情况下,Hadoop将计数器分为五大类,如下表所示:
| 计数器 |
属性名 |
| MapReduce任务计数器 |
org.apache.hadoop.mapreduce.TaskCounter |
| 文件系统计数器 |
org.apache.hadoop.mapreduce.FileSystemCounter |
| 输入文件计数器 |
org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter |
| 输出文件计数器 |
org.apache.hadoop.mapreduce.lib.input.FileOutputFormatCounter |
| 作业计数器 |
org.apache.hadoop.mapreduce.JobCounter |
任务计数器主要用于收集任务在运行时的任务信息,任务计数器可以被部署在各个节点上,并且统一传送到主节点进行汇集,如果一个任务最终失败,那么所有的计数器记录都会被重置,即所有的计数清零。只有当任务成功以后,计数器才会被记录。
(2)自定义计数器:
自定义计数器有两种类型:
①通过java枚举(enum)类型来定义,一个作业可以定义的枚举类型数量不限,各个枚举类型包含的字段数量也不限。枚举类型的名称即为组的名称,枚举类型的字段就是计数器的名称。
②使用动态计数器。
(3)实现自定义计数器:
本节任务使用的是社交网站1月份和2月份用户的登录信息,但是1月份和2月份的数据各有多少不知道,如果想要知道每个月份的数据记录数,可以通过自定义计数器来实现。首先在Mapper类中定义枚举类型,代码如下:
enum LogCounter{
January,
February
}接着在map函数里调用Context类的getCounter方法,说明使用了枚举类型中的哪个计数器,还需要调用increment()方法进行计数的添加,代码如下:
if(logTime.contains("2016-01")){
context.getCounter(LogCounter.January).increment(1);
}else if(logTime.contains("2016-02")){
context.getCounter(LogCounter.February).increment(1);
}注意:计数器不是只能在Mapper中添加,也可以在Reducer中添加,如果要统计每个月的输出结果记录数,则需要在Reducer中添加上面代码。
(4)另一种自定义计数器的方式是使用动态计数器。除了使用getCounter方法获取枚举中值的方式外,Context类中还有一个重载方法getCounter(String groupName,String countName),能够对当前计数器进行动态计数。例如对统计一月份和二月份用户每天登录次数的输出结果进行计数,则可以在reduce函数中添加代码:
if(key.getLogTime().contains("2016-01")){
context.getCounter("OutputCounter","JanuaryResult").increment(1);
}else if(key.getLogTime().contains("2016-02")){
context.getCounter("OutputCounter","FebruaryResult").increment(1);
}3.5 任务实现(完成前述第三个任务)
经过前面的讨论探索,现在开始实现本节任务:通过MapReduce编程实现用户在2016年1月份和2月份每天登录次数的统计。实现该任务的具体步骤及代码如下:
自定义Mapper类:
package essential;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//自定义实现Mapper类
//为了提高效率,在驱动类里面配置Combiner类
public class LogCountMapper extends Mapper {
private MemberLogTime mt=new MemberLogTime();
private IntWritable one=new IntWritable(1);
enum LogCounter{
January,
February
}
protected void map(Text key,Text value,Mapper.Context context) throws IOException, InterruptedException {
String member_name=key.toString();
String logTime=value.toString();
if(logTime.contains("2016-01")){
context.getCounter(LogCounter.January).increment(1);
}else if(logTime.contains("2016-02")){
context.getCounter(LogCounter.February).increment(1);
}
mt.setMember_name(member_name);
mt.setLogTime(logTime);
context.write(mt,one);
}
} 自定义Reducer类:
package essential;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//自定义实现Reducer类
public class LogCountReducer extends Reducer {
protected void reduce(MemberLogTime key,Iterable value,Reducer.Context context) throws IOException, InterruptedException {
if(key.getLogTime().contains("2016-01")){//此处就是使用了计数器
context.getCounter("OutPutCounter","JanuaryResult").increment(1);
}else if(key.getLogTime().contains("2016-02")){
context.getCounter("OutPutCounter","FebruaryResult").increment(1);
}
//下面才是reduce函数的主体
int sum=0;
for(IntWritable iw:value){
sum+=iw.get();
}
context.write(key,new IntWritable(sum));
}
} 驱动类:
package essential;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Properties;
//编辑查找1、2月数据统计的驱动类
public class LogCount {
public static void main(String args[]) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Properties properties = System.getProperties();
properties.setProperty("HADOOP_USER_NAME","root");
//计数器类在前面的自定义Mapper和Reducer已经写入
Job job = Job.getInstance(conf,"LogCount");
job.setJarByClass(LogCount.class);
job.setMapperClass(LogCountMapper.class);//设置自定义Mapper类
job.setMapOutputKeyClass(MemberLogTime.class);
job.setMapOutputValueClass(IntWritable.class);
job.setCombinerClass(LogCountCombiner.class);//设置自定义Combiner类
job.setReducerClass(LogCountReducer.class);//设置自定义Reducer类
job.setOutputKeyClass(MemberLogTime.class);
job.setOutputValueClass(IntWritable.class);
job.setPartitionerClass(LogCountPartitioner.class);//设置自定义分区类
job.setNumReduceTasks(2);
//job.setOutputFormatClass(GbkOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileSystem.get(conf).delete(new Path(args[1]),true);//防止文件目录重复
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}4.Eclipse提交日志文件统计程序
打包并提交任务到Hadoop集群,比在集成开发工具上更具有高效性,大文件开发可使用。
5.小结
本章是MapReduce编程进阶,介绍的内容包括MapReduce的输入及输出格式、Hadoop Java API、自定义键值类型、Combiner组件、自定义计数器以及Eclipse提交MapReduce任务。其中,自定义键值类型、Combiner组件和Partitioner组件对程序的优化起到了举足轻重的作用,在一定程度上可以提高程序运行效率。
6.实训
实训目的:掌握MapReduce的Combiner的使用,掌握自定义数据类型,掌握自定义计数器,掌握MapReduce参数传递,掌握ToolRunner的使用和提交MapReduce任务
实训1.统计全球每年的最高气温和最低气温
1.训练要点:掌握Combiner的使用、掌握自定义数据类型
2.需求说明:
将压缩文件上传到linux本地目录,在该目录下解压所有文件,文件数据格式如下:

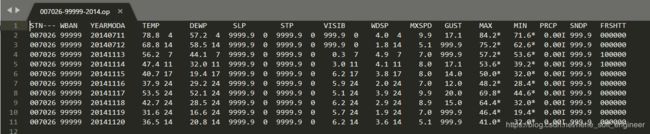
其中,YEARMODA对应年月日,TEMP对应温度,并且每列数据的分隔符空格数是不同的,这个在预处理数据时要注意。
创建一个文件temperaturedata.txt,在数据文件所在目录执行命令 sed -i '1d' 来删除所有文件的首行字段,然后执行cat * >>data.txt将所有的数据输入到data.txt中
(1)统计全球每年的最高气温和最低气温。
(2)MapReduce输出结果包含年份、最高气温、最低气温,并按照最高气温降序排序。如果最高气温相同,则按照最低气温升序排序。
(3)使用自定义数据类型。
(4)结合Combiner和自定义数据类型完成全球每年最高气温和最低气温的统计。
3.实现思路及步骤:
目的是选出每年的最高气温和最低气温。(因为是选择最大最小值,可以在Combiner阶段就开始选择最大最小值,以提高效率)
输出结果为包含年份+最高气温+最低气温,并按照最高气温降序排序。如果最高气温相同,则按照最低气温升序排序。
(1)自定义数据类型
相当于给此次任务设置一个实体类,作为基本数据类型。
自定义数据类型(重写值类型方法)YearMaxTandMinT继承Writable接口,在这个类里面定义出相关属性:year、Maxtemp、MinTemp以及set、get方法。
实现构造函数。
(2)自定义Mapper
命名为MaxTandMinTMapper,其主要功能是作映射,将year作为key,temp作为value输出。
(3)自定义Combiner
命名为MaxTandMinTCombiner,其主要功能是提前处理Map的一些数据,获取出年度最高和最低的温度,然后作为值输出。
(4)自定义Reducer
命名为MaxTandMinTReducer,其主要功能为对年份进行排序,排序依据如上
4.实现代码:
(1)自定义实体类:
package essential.Temperature;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//对值类型进行重写,实现Writable类
public class YearMaxTandMinT implements Writable {
private String year;
private double Maxtemp;
private double MinTemp;
public YearMaxTandMinT(){
}
public YearMaxTandMinT(String year,double maxtemp,double mintemp){
this.year=year;
this.Maxtemp=maxtemp;
this.MinTemp=mintemp;
}
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public double getMaxtemp() {
return Maxtemp;
}
public void setMaxtemp(double maxtemp) {
Maxtemp = maxtemp;
}
public double getMinTemp() {
return MinTemp;
}
public void setMinTemp(double minTemp) {
MinTemp = minTemp;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(year);
dataOutput.writeDouble(Maxtemp);
dataOutput.writeDouble(MinTemp);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.Maxtemp=dataInput.readDouble();
this.MinTemp=dataInput.readDouble();
this.year=dataInput.readUTF();
}
public String toString(){
return "Year:"+year+" ;The MaxTemperature is "+Maxtemp+" and the MinTemperature is "+MinTemp;
}
public int Compare(YearMaxTandMinT otherymm){//设置比较两对象之间的大小关系,前者与后者比较,前者较大返回1,后者较大返回-1;用于比较年份时使用
if(Maxtemp>otherymm.getMaxtemp()){
return 1;
}else if(Maxtemp==otherymm.getMaxtemp()){
if(MinTemp(2)自定义Mapper:
package essential.Temperature;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//对Mapper进行自定义
public class MaxTandMinTMapper extends Mapper {
//map处理逻辑:主要功能是作映射,将year作为key,temp作为value输出。
public void map(LongWritable key,Text value,Mapper.Context context) throws IOException, InterruptedException {
String[] datas=value.toString().split("\\s+");//多空格切割字符串
String year=datas[2].substring(0,4);
double tempdata=Double.parseDouble(datas[3]);
context.write(new Text(year),new DoubleWritable(tempdata));
}
} (3)自定义Combiner:
package essential.Temperature;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//此处的Combiner旨在完成排序筛选工作,选出气温的最大值和最小值,
//此处我我想错了,我想的是一步到位,其实应该是和Mapper的输出应该一致才对,输出的还是应该为年份+温度,只不过是一次性写两次,Combiner的键值对输入类型和输出类型应该是一致的
public class MaxTandMinTCombiner extends Reducer {
public void reduce(Text key,Iterable tempdatas,Reducer.Context context) throws IOException, InterruptedException {
YearMaxTandMinT ymm=new YearMaxTandMinT();
double maxtemp=0;//初始化温度值
double mintemp=999;
for(DoubleWritable tempdata:tempdatas){//遍历shuffle阶段组合的数组,对key值对应的最大最小值进行更新操作
if(tempdata.get()>maxtemp){
maxtemp=tempdata.get();
}else if(tempdata.get() (4)自定义Reducer:
package essential.Temperature;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.LinkedList;
//Reducer是对有Combiner部分分类好的数据进行最后的整合处理,最终要将每一年的年份和最高最低温度进行整理
//并对所有年份进行比较,比较的标准为,先以最高温度为标准进行比较,如果最高温度相同,则以最低温度较高者排在前面
public class MaxTandMinTReducer extends Reducer {
private LinkedList ymmlists=new LinkedList();//用于存储Reduce整合出来的ym
public void reduce(Text key,Iterable temps,Reducer.Context context) throws IOException, InterruptedException {
//先对相同的key的最高温和最低温进行整合
System.out.println("压根没有执行我吗");
YearMaxTandMinT ym=new YearMaxTandMinT();
ym.setYear(key.toString());
double yearmintemp=999;
double yearmaxtemp=0;
for(DoubleWritable temp:temps){
if(temp.get()yearmaxtemp){
yearmaxtemp=temp.get();
}
}
ym.setMinTemp(yearmintemp);
ym.setMaxtemp(yearmaxtemp);
//到这里就实现了年份+最高温+最低温的匹配
//然后进行年份的排序,在这里需要引入链表(使用单向链表也可以),因为要存储的数据很少,所以这种方式是可以的。
//链表内数据先以最高温度为标准进行比较,如果最高温度相同,则以最低温度较高者排在前面
if(ymmlists.size()==0){//如果得到的是第一条数据直接加入表格
ymmlists.add(ym);
}else {
if(ym.Compare(ymmlists.getFirst())>0){//表示该元素为现有列表中最大
ymmlists.add(0,ym);
}if(ym.Compare(ymmlists.getLast())<0){//表示该元素在现有列表中最小
ymmlists.add(ym);
}else{//表示在最大和最小之间
for(int index=0;index0){
ymmlists.add(otherindex,ym);
break;
}
}
}
}
String printstring="";
for(YearMaxTandMinT yt:ymmlists){
printstring=printstring+yt.toString()+"\n";
System.out.println(printstring);
}
context.write(NullWritable.get(),new Text(printstring));
}
} (5)驱动类编写:
package essential.Temperature;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Properties;
//实现MapReduce任务,编写驱动类
public class MaxTandMinT {
public static void main(String [] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Properties properties = System.getProperties();
properties.setProperty("HADOOP_USER_NAME","root");
//计数器类在前面的自定义Mapper和Reducer已经写入
Job job = Job.getInstance(conf,"MaxTandMinT");
job.setJarByClass(MaxTandMinT.class);
job.setMapperClass(MaxTandMinTMapper.class);//设置自定义Mapper类
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setCombinerClass(MaxTandMinTCombiner.class);//设置自定义Combiner类
job.setReducerClass(MaxTandMinTReducer.class);//设置自定义Reducer类
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
//job.setPartitionerClass(LogCountPartitioner.class);//设置自定义分区类
job.setNumReduceTasks(1);
//job.setOutputFormatClass(GbkOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileSystem.get(conf).delete(new Path(args[1]),true);//防止文件目录重复
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}5.实现结果:

实训2.筛选15~25℃之间的数据
训练要点:掌握MapReduce参数的传递、掌握自定义计数器、掌握ToolRunner的使用和提交MapReduce任务。
7.小练习
(1)下面属于Hadoop内置数据类型的是:D
A.IntegerWritable B.StringWritable C.ListWritable D.MapWritable
(2)关于自定义数据类型,下列说法正确的是:D
A.自定义数据类型必须继承Writable接口
B.自定义键类型需要继承Writable接口
C.自定义值类型需要继承WritableComparable接口
D.自定义数据类型必须实现readFileds(DataInput datainput)方法
(3)设置MapReduce参数传递的正确方式是:基于MapReduce的API
conf.set("argName",args[n])传递
(4)在Mapper类的setup函数中,下列( )方式可以用来获取参数值。
context.getConfiguration.get("argName")
既然Hadoop的配置类Configuration里面有根据属性名称获取参数值的方法,即返回类型为String类型的get(String name)方法。在编写MapReduce程序的时候,可以在setup方法中通过上下文对象Context中的getConfiguaration()方法来获取配置对象Configuaration,再调用Configuration里面的get(String name)方法获取这些参数值。
(5)MapReduce的输入默认格式为TextInputFormat,输出默认格式为TextOutputFormat
全部基本知识到这里基本就结束了,最后一章是一个网站项目,主要的学习目标是学习KNN算法,并使用MapReduce实现KNN算法。