Hbase常用操作及样例
Hbase常用操作及样例
(1)创建hbase表
可以使用命令创建一个表,在这里必须指定表名和列族名。在HBase shell中创建表的语法如下所示。
create '<table name>','<column family>'
示例
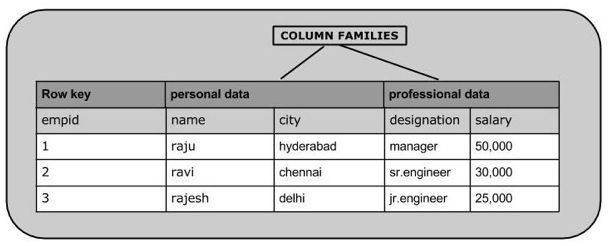
下面给出的是一个表名为emp的样本模式。它有两个列族:“personal data”和“professional data”。
|
Row key
|
personal data
|
professional data
|
|
|
|
|
|
|
|
|
在HBase shell创建该表如下所示。
hbase(main):001:0> create 'emp','personal data','professional data'
0 row(s) in 1.4790 seconds
=> Hbase::Table - emp
(2)检测hbase表是否存在
HBase Exists
可以使用exists命令验证表的存在。下面的示例演示了如何使用这个命令。
hbase(main):002:0> exists 'emp'
Table emp does exist
0 row(s) in 0.1230 seconds
(3)HBase表描述和修改
1)描述
该命令返回表的说明。它的语法如下:
hbase> describe 'table name'
下面给出的是对emp表的
describe
命令的输出。
hbase(main):003:0> desc 'emp'
Table emp is ENABLED
emp
COLUMN FAMILIES DESCRIPTION
{NAME => 'personal data', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE
=> '0'}
{NAME => 'professional data', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_S
COPE => '0'}
2 row(s) in 0.0430 seconds
2)修改
alter用于更改现有表的命令。使用此命令可以更改列族的单元,设定最大数量和删除表范围运算符,并从表中删除列家族。
更改列族单元格的最大数目
下面给出的语法来改变列家族单元的最大数目。
hbase> alter 'emp', NAME => 'personal data', VERSIONS => 5
在下面的例子中,单元的最大数目设置为5。
hbase(main):004:0> alter 'emp', NAME => 'personal data', VERSIONS => 5
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.9390 seconds
hbase(main):005:0> desc 'emp'
Table emp is ENABLED
emp
COLUMN FAMILIES DESCRIPTION
{NAME => 'personal data', BLOOMFILTER => 'ROW', VERSIONS => '5', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE
=> '0'}
{NAME => 'professional data', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_S
COPE => '0'}
2 row(s) in 0.0240 seconds
3)删除列族
使用alter,也可以删除列族。下面给出的是使用alter删除列族的语法。
hbase> alter ‘ table name ’, ‘delete’ => ‘ column family ’
下面给出的是一个例子,从“emp”表中删除列族。
假设在HBase中有一个emp
表。它包含以下数据:
hbase(main):005:0> desc 'emp'
Table emp is ENABLED
emp
COLUMN FAMILIES DESCRIPTION
{NAME => 'personal data', BLOOMFILTER => 'ROW', VERSIONS => '5', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE
=> '0'}
{NAME => 'professional data', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_S
COPE => '0'}
2 row(s) in 0.0240 seconds
现在使用alter命令删除指定的 personal data
列族。
hbase(main):007:0> alter 'emp','delete' => 'personal data'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.9460 seconds
现在验证该表中变更后的数据。观察列族“personal data
”也没有了,因为前面已经被删除了。
hbase(main):008:0> desc 'emp'
Table emp is ENABLED
emp
COLUMN FAMILIES DESCRIPTION
{NAME => 'professional data', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_S
COPE => '0'}
1 row(s) in 0.0270 seconds
4)用drop命令可以删除表。在删除一个表之前必须先将其禁用。
hbase(main):016:0> drop 'emp'
ERROR: Table emp is enabled. Disable it first.
Here is some help for this command:
Drop the named table. Table must first be disabled:
hbase> drop 't1'
hbase> drop 'ns1:t1'
hbase(main):017:0>
hbase(main):018:0> disable 'emp'0 row(s) in 1.4580 secondshbase(main):019:0> drop 'emp'0 row(s) in 0.3060 seconds
使用exists 命令验证表是否被删除。
hbase(main):020:0> exists 'emp'Table emp does not exist0 row(s) in 0.0730 seconds
5)drop_all 这个命令是用来在给出删除匹配“regex”表。
它的语法如下:
hbase> drop_all 't.*'
注意:要删除表,则必须先将其禁用。
示例
假设有一些表的名称如下:
hbase(main):079:0> list 'test0.*'
TABLE
test001
test010
test011
3 row(s) in 0.0100 seconds
=> ["test001", "test010", "test011"]所有这些表以字母test0开始。首先使用disable_all命令禁用所有这些表如下所示。
hbase(main):080:0> disable_all 'test0.*'
test001
test010
test011
Disable the above 3 tables (y/n)?
y
3 tables successfully disabled
现在,可以使用 drop_all 命令删除它们,如下所示。
hbase(main):081:0> drop_all 'test0.*'
test001
test010
test011
Drop the above 3 tables (y/n)?
y
3 tables successfully disabled
(4) 介绍如何在HBase表中创建的数据。要在HBase表中创建的数据,可以下面的命令和方法:
- put 命令,
- add() - Put类的方法
- put() - HTable 类的方法.
作为一个例子,我们将在HBase中创建下表。
1)使用put命令,可以插入行到一个表。它的语法如下:
put '<table name>','row1','<colfamily:colname>','<value>'
插入第一行
将第一行的值插入到emp表如下所示。
hbase(main):005:0> put 'emp','1','personal data:name','raju'
0 row(s) in 0.6600 seconds
hbase(main):006:0> put 'emp','1','personal data:city','hyderabad'
0 row(s) in 0.0410 seconds
hbase(main):007:0> put 'emp','1','professional data:designation','manager'
0 row(s) in 0.0240 seconds
hbase(main):007:0> put 'emp','1','professional data:salary','50000'
0 row(s) in 0.0240 seconds
以相同的方式使用put命令插入剩余的行。如果插入完成整个表格,会得到下面的输出。
hbase(main):033:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1526107123317, value=hyderabad
1 column=personal data:name, timestamp=1526107114531, value=raju
1 column=professional data:designation, timestamp=1526107149015, value=manager
1 column=professional data:salary, timestamp=1526107161142, value=50000
1 row(s) in 0.0420 seconds
2)可以使用put命令更新现有的单元格值。按照下面的语法,并注明新值,如下图所示。
put 'table name','row ','Column family:column name','new value'
新给定值替换现有的值,并更新该行。
示例
假设HBase中有一个表emp拥有下列数据
hbase(main):038:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1526107123317, value=hyderabad
1 column=personal data:name, timestamp=1526107114531, value=raju
1 column=professional data:designation, timestamp=1526107149015, value=manager
1 column=professional data:salary, timestamp=1526107161142, value=50000
1 row(s) in 0.0190 seconds
以下命令将更新名为“Raju'员工的城市值为'Delhi'。
hbase(main):039:0> put 'emp','1','personal data:name','Delhi'
0 row(s) in 0.0050 seconds
更新后的表如下所示,观察这个城市Raju的值已更改为“Delhi”。
hbase(main):040:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1526107123317, value=hyderabad
1 column=personal data:name, timestamp=1526107469019, value=Delhi
1 column=professional data:designation, timestamp=1526107149015, value=manager
1 column=professional data:salary, timestamp=1526107161142, value=50000
1 row(s) in 0.0120 seconds
3)get命令和HTable类的get()方法用于从HBase表中读取数据。
使用 get 命令,可以同时获取一行数据。它的语法如下:
get '<table name>','row1'
下面的例子说明如何使用get命令。扫描emp表的第一行。
hbase(main):041:0> get 'emp','1'
COLUMN CELL
personal data:city timestamp=1526107123317, value=hyderabad
personal data:name timestamp=1526107469019, value=Delhi
professional data:designation timestamp=1526107149015, value=manager
professional data:salary timestamp=1526107161142, value=50000
4 row(s) in 0.0370 seconds
hbase(main):043:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1526107123317, value=hyderabad
1 column=personal data:name, timestamp=1526107469019, value=Delhi
1 column=professional data:designation, timestamp=1526107149015, value=manager
1 column=professional data:salary, timestamp=1526107161142, value=50000
1 row(s) in 0.0230 seconds
4)读取指定列
下面给出的是语法,使用get方法读取指定列。
hbase>get 'table name', 'rowid', {COLUMN => 'column family:column name'}
下面给出的示例,是用于读取HBase表中的特定列。
hbase(main):044:0> get 'emp', '1', {COLUMN=>'personal data:name'}
COLUMN CELL
personal data:name timestamp=1526107469019, value=Delhi
1 row(s) in 0.0110 seconds
5)从表删除特定单元格
使用 delete 命令,可以在一个表中删除特定单元格。 delete 命令的语法如下:
delete '<table name>', '<row>', '<column name >', '<time stamp>'
下面是一个删除特定单元格和例子。在这里,我们删除salary
hbase(main):043:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1526107123317, value=hyderabad
1 column=personal data:name, timestamp=1526107469019, value=Delhi
1 column=professional data:designation, timestamp=1526107149015, value=manager
1 column=professional data:salary, timestamp=1526107161142, value=50000
1 row(s) in 0.0230 seconds
hbase(main):044:0> get 'emp', '1', {COLUMN=>'personal data:name'}
COLUMN CELL
personal data:name timestamp=1526107469019, value=Delhi
1 row(s) in 0.0110 seconds
hbase(main):045:0> delete 'emp', '1', 'personal data:city'
0 row(s) in 0.0470 seconds
hbase(main):046:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:name, timestamp=1526107469019, value=Delhi
1 column=professional data:designation, timestamp=1526107149015, value=manager
1 column=professional data:salary, timestamp=1526107161142, value=50000
1 row(s) in 0.0210 seconds
6)删除表的所有单元格
使用“deleteall”命令,可以删除一行中所有单元格。下面给出是 deleteall 命令的语法。
deleteall '<table name>', '<row>',
这里是使用“deleteall”命令删去 emp 表 row1 的所有单元的一个例子。
hbase(main):047:0> deleteall 'emp','1'
0 row(s) in 0.0150 seconds
使用scan命令验证表。表被删除后的快照如下。
hbase(main):048:0> scan 'emp'
ROW COLUMN+CELL
0 row(s) in 0.0220 seconds
(5)HBase扫描
1)scan
命令用于查看HTable数据。使用
scan
命令可以得到表中的数据。它的语法如下:
scan '<table name>'
下面的示例演示了如何使用scan命令从表中读取数据。在这里读取的是emp表。
scan 'emp'
2)count
可以使用count命令计算表的行数量。它的语法如下:
count ‘<table name>’
表emp就只有1行。验证它,如下图所示。
hbase(main):062:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1526108340886, value=hyderabad
1 column=personal data:name, timestamp=1526108331176, value=raju
1 column=professional data:designation, timestamp=1526108351404, value=manager
1 column=professional data:salary, timestamp=1526108361753, value=50000
1 row(s) in 0.0160 seconds
hbase(main):063:0> count 'emp'
1 row(s) in 0.0060 seconds
=> 1增加两行之后,会变成3行。
hbase(main):064:0> put 'emp','2','professional data:designation','manager'
0 row(s) in 0.0080 seconds
hbase(main):065:0> put 'emp','3','professional data:designation','manager'
0 row(s) in 0.0570 seconds
hbase(main):066:0> count 'emp'
3 row(s) in 0.0180 seconds
=> 3
hbase(main):067:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1526108340886, value=hyderabad
1 column=personal data:name, timestamp=1526108331176, value=raju
1 column=professional data:designation, timestamp=1526108351404, value=manager
1 column=professional data:salary, timestamp=1526108361753, value=50000
2 column=professional data:designation, timestamp=1526108497801, value=manager
3 column=professional data:designation, timestamp=1526108507588, value=manager
3 row(s) in 0.0090 seconds
(6)runcate
此命令将禁止删除并重新创建一个表。truncate 的语法如下:
hbase> truncate 'table name'
下面给出是 truncate 命令的例子。在这里,我们已经截断了emp表。
hbase(main):067:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1526108340886, value=hyderabad
1 column=personal data:name, timestamp=1526108331176, value=raju
1 column=professional data:designation, timestamp=1526108351404, value=manager
1 column=professional data:salary, timestamp=1526108361753, value=50000
2 column=professional data:designation, timestamp=1526108497801, value=manager
3 column=professional data:designation, timestamp=1526108507588, value=manager
3 row(s) in 0.0090 seconds
hbase(main):068:0> truncate 'emp'
Truncating 'emp' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 3.4100 seconds
截断表之后,使用scan 命令来验证。会得到表的行数为零。
hbase(main):069:0> scan 'emp'
ROW COLUMN+CELL
0 row(s) in 0.1370 seconds
(7) HBase安全
我们可以授予和撤销HBase用户的权限。也有出于安全目的,三个命令:grant, revoke 和 user_permission.。
1) grant
grant命令授予特定的权限,如读,写,执行和管理表给定一个特定的用户。 grant命令的语法如下:
hbase> grant
我们可以从RWXCA组,其中给予零个或多个特权给用户
- R - 代表读取权限
- W - 代表写权限
- X - 代表执行权限
- C - 代表创建权限
- A - 代表管理权限
下面给出是为用户“Tutorialspoint'授予所有权限的例子。
hbase
(
main
):
018
:
0
>
grant
'Tutorialspoint'
,
'RWXCA'
2) revoke
revoke命令用于撤销用户访问表的权限。它的语法如下:
hbase> revoke
下面的代码撤消名为“Tutorialspoint”用户的所有权限。
hbase
(
main
):
006
:
0
>
revoke
'Tutorialspoint'
3) user_permission
此命令用于列出特定表的所有权限。 user_permission的语法如下:
hbase>user_permission 'tablename'
下面的代码列出了“emp”表的所有用户权限。
hbase
(
main
):
013
:
0
>
user_permission
'emp'