最简单全面的介绍IPFS
最简单全面的介绍IPFS

I
IPFS
1. 什么是IPFS?
IPFS是一个互联网的底层协议,类似HTTP协议,上线时间是2015年的5月5号。
IPFS不是区块链项目,没有使用任何区块链技术。所以,IPFS没有Token、没有发B、不能挖矿;Filecoin才是Token,挖的是Filecoin。
IPFS目标是打造一个更加开放、快速、安全的互联网,利用分布式哈希表解决数据的传输和定位问题,把点对点的单点传输改变成P2P(多点对多点)的传输,其中存储数据的结构是哈希链。
2. IPFS如何找到数据?
每一个IPFS节点上都会存一个地图,每个地图之间互相连接,所有IPFS节点地图加起来变成一个分布式哈希表。当我向这个网络请求数据的时候,会根据数据本身的ID哈希值,采用一种数学计算的方式,来查找你的资源在哪台机子上,然后建立起一种连接,下载你需要的数据。
3. IPFS能不能加密文件?
IPFS不加密文件,加密任务是应用层的事情,所以,你需要的话可以自己去开发一个。之前HTTP也是不包含加密功能,加密是靠HTTPS实现的。
4. IPFS的数据永久保存?
不是,是可以永久保存数据,不是所有数据都是永久保存。
5. IPFS可以防止内容窜改吗?
IPFS不能防窜改,你只要一改,哈希值就变了。并且,你自己节点存储的数据,你有绝对权限,可以对文件进行删、存、添加的操作。
Filecoin
1. Filecoin的技术难点?

Filecoin的技术难点是数据持有证明、防止作弊和攻击、零知识证明。
Filecoin有很多共识机制的可选择,但是协议实验室不希望像Bitcoin那样通过消耗计算资源与能源的方式去建立共识,所以,采用了复制证明和时空证明来做数据持有证明。
复制证明是向系统证明自己确实在矿机上储存数据,时空证明是在复制证明的基础上加上时间戳的相关技术,用来证明矿工在一段时间内存储数据的证明,这样既可以做到持有验证,同时也可以防止作弊。
零知识则是通过数据局部抽查的方式来验证数据的真伪,零知识本质上是一个概率问题,但是却能解决数据验证的问题。
2. Filecoin的未来到底会怎样?
目前Filecoin的存储成本是中心化存储成本的1/3,而Filecoin的初心想通过共享硬盘和共享带宽,为世界提供价格更低的存储和网络。
Filecoin的未来是可以期待的,但是不排除未来可能系统内耗过高,导致成本和中心化相差不大,甚至成本超过中心化的成本。所以,未来Filecoin可能也会面临被淘汰,但还是要相信Filecoin整体的经济模型和能力,可以冲破质疑。
3. Filecoin的经济体系是怎样运行的?
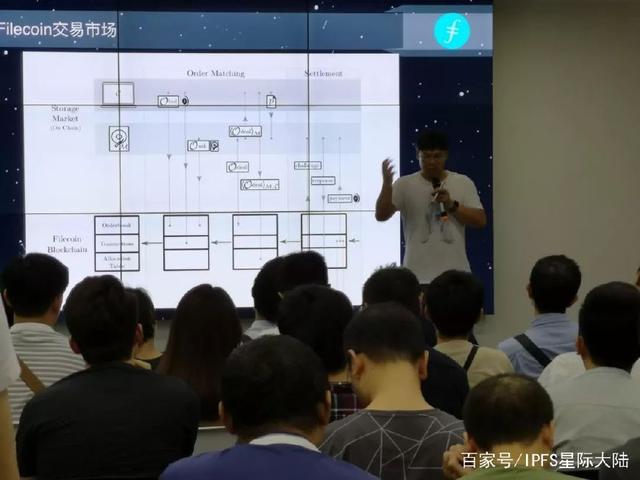
Filecoin的网络中包含矿工与用户,矿工对整体网络的贡献是提供存储空间及网络带宽,用户则是付费使用存储空间及网络带宽,Filecoin网络充当资源交易市场的角色。
在中心化的世界我们看似不用付费就可以得到存储空间,其实成本是被解构了无形的加在我们身上。举个例子,就像我们去京东上购买商品,京东首先是为自己存储的网页数据付费了,我们去访问的同时,我们也需要像网络运营商支付网络流量费用。
4. IPFS与Filecoin的关系
IPFS和Filecoin是两个不一样的项目,Filecoin是一个区块链项目,但未来所使用的网络是同一个。IPFS和Filecoin所使用的技术(除了Libp2p)几乎是不重叠的。
IPFS使用的越多,Filecoin的需求更大;Filecoin的矿工越多,对IPFS的支持越大。
IPFS的核心是一个BT,Filecoin就是帮IPFS做“种子”,让IPFS变得更加快速。
IPFS+Filecoin共享存储方式可能是未来物联网成功的一个关键因素。
Libp2p和IPLD
1. 什么是Libp2p?

Libp2p是一个P2P的网络,分为网络层、路由层、交换层。
Libp2p是IPFS和Filecoin的基础设施,也是未来所有P2P和区块链、物联网的基础设施。Libp2p是与IPFS、Filecoin同等重要的一个项目。

2. 什么是IPLD?
IPLD是一个哈希链数据统一格式,是Fielcoin项目的重要的一环。
现在已经统一的格式有比特币的数据格式、以太坊数据格式、Git的数据格式。
挖矿

1. Filecoin矿机的算力与Bitcoin矿机的算力有何不同?
Bitcoin矿机的算力是根据矿机的CPU等性能来确定且也是恒定的,也就说Bitcoin矿机在未接入Bitcoin网络时就已经知道算力,矿工的预期挖矿效益是相对明确的。
Filecoin矿机的算力取决于矿机存储数据量的大小,一台Filecoin矿机刚接入Filecoin系统是算力为零,随着存储数据增多算力增大,矿机在不同地方不同网络收益都是不一样的,矿机的预期收益目前是不可预测的。
Filecoin矿机算力是指你存储的数据量占全网存储数据总量的比例,即代表你矿机的算力,算力越高新币分发得到的奖励越高。我们知道用户在存储数据时一般都是有时间限制的,数据存储时间到期后,若未续约,这部分是存储数据将不再为矿机带来算力。
2. 存储矿工与检索矿工的区别?

Filecoin有两个市场,存储市场与检索市场。
两个市场虽然技术结构相同,但是在经济模型上设计却有大不同。两个市场分别形成了存储矿工和检索矿工。
在存储市场里用户需要为存储数据而向矿工付费;检索市场里则是用户需要为矿工提供的检索数据传递而付费。
存储市场是在Filecoin链上进行交易的,存储矿工向系统提交复制证明,复制证明就像存储数据以后的收据,向系统证明矿工有存储数据,从而参与新币的分发。
检索市场是在Filecoin链下进行的,检索市场选择链下交易是为了用户快速得到数据,快速完成交易,同时采用微支付形式进行支付,避免提供服务后用户拒绝付费和用户付费后没有得到检索服务。
即将检索的数据打散成小块,交付一部数据块就得到一部分金额,直到钱货两清。
而存储矿工与检索矿工最大的区别就是存储矿工可以参与新币的分发,而检索矿工只能为用户提供检索服务。
3.矿机硬件配置与挖矿的影响因素是什么?

矿机的配置取决于复制证明的实现方式,目前协议实验室还在调试优化,很多矿机厂商是根据复制证明来推测矿机配置的,Filecoin测试完成后,官方会公布矿机推荐配置和最佳配置,同时,协议实验室想尽可能的使现有设备不经修改即可用于Filecoin体系,用来减少资源浪费;也会尽可能的降低Filecoin挖矿系统最低需求,降低Filecoin整个网络成本。

目前,Filecoin整体网络对矿机只有一个要求就是稳定,硬盘要用7*24小时运行的硬盘,网络要用稳定的,同时也需要静态IP,也就是说目前家庭矿机是不能进行挖矿(原因后面会说)。
为了让矿机更容易挖矿,矿机还需要离用户更近,因为数据在存储时有一个临近存储的原则,矿机离用户(节点)越近越有机会挖到矿。
目前矿机的CPU还是需要等待官方的消息才能确定。
4. 应用开发与挖矿的关系?
应用开发商可以说是矿工的衣食父母,矿工离应用开发商越近也就越容易接到应用开发商的存储订单。国内目前的应用开发不多,国内需要加快应用开发的脚步,届时矿工才能拥有更好的挖矿环境。
5. 国内家庭矿机可以挖矿吗?
由于国内静态IP地址缺少,并且 ICE NAT框架在国内的实现的情况不理想,很多家庭网络连接不上,所以很多Filecoin家庭矿机是挖不了矿的。并且如果 ICE NAT框架在Filecoin主网上线前未实现的话,中国矿工是竞争不过国外矿工的。不过,董老师和协议实验室正在想办法解决这个问题。