吴恩达机器学习:支持向量机
这次的课程笔记和上次隔了好久,因为为了搞懂 SVM 花了不少时间。和之前 神经网络 课程一样,Ng 在 Coursera 上讲述的内容非常有限,要搞懂 SVM 你只能寻求于其他方面的资料。经过对网上一些内容的对比后发现斯坦福的 CS229 讲义写得非常清晰。CS229 是 Andrew Ng 在斯坦福大学开设的机器学习课程,Coursera 上的课程可以说是 CS229 的简化版本,而且整个课程的内容还在不断更新,有兴趣的同学可以把它作为更进一步的参考资料。( 我已经将讲义和 SMO 算法的论文与代码放在一起了方便大家下载 )
这次的课程笔记会阐述 SVM 的主要思路,从 最大间距分类器 开始,然后通过 拉格朗日对偶 得到原问题的 对偶 问题,使得我们可以应用 核技巧( kernel trick ),用高效的方式解决高维问题。
点击 课程视频 你就能不间断地学习 Ng 的课程,关于课程作业的 Python 代码已经放到了 Github 上,点击 课程代码 就能去 Github 查看( 无法访问 Github 的话可以点击 Coding 查看 ),代码中的错误和改进欢迎大家指出。
以下是 Ng 机器学习课程第六周的笔记。
最大间距分类器
考虑 逻辑回归 的 预测函数 hθ(x)=g(θTx) h θ ( x ) = g ( θ T x ) 。当 θTx≫0 θ T x ≫ 0 或 θTx≪0 θ T x ≪ 0 时,就能十分确信 预测函数 的分类,因为 hθ(x) h θ ( x ) 接近于 1 和 0。直观的表达就是样本越是远离 决策边界,就越确信它的分类。所以自然想到如果在多个 决策边界 之间选择,我们会选择离所有样本都比较远的那个( 考虑线性的情况 )。

为了得到这样的决策边界,我们首先来看看如何用数学方式表达这个问题。通过一些简单的 计算几何 知识可以计算出每个样本到 决策边界 的距离( geometric margin ), γ(i) γ ( i ) 。为了方便之后的推导,还需要定义一个 functional margin, γ̂ (i) γ ^ ( i ) 。
在接下来的 SVM 讨论中 y(i) y ( i ) 的取值为 {1,−1} { 1 , − 1 } ( 表示在决策边界的哪一侧,并使得距离的计算都是正的 ),当 wTx+b≥0 w T x + b ≥ 0 时取 1 1 , wTx+b<0 w T x + b < 0 时取 −1 − 1 。还需要定义 γ̂ γ ^ 为所有 γ̂ (i) γ ^ ( i ) 中最小的值, γ γ 为所有 γ(i) γ ( i ) 中最小的值。于是要求离所有样本都比较远的决策边界问题就成为了在给定约束条件下求最值的问题。
然而上面的问题还不是一个直接可解的 优化问题,需要对它进行转化( 思路是把它转化为标准的 凸优化问题 )。首先我们用 functional margin 来替换 geometric margin,原问题变为:
这个问题的解和原先的相同,不同点是在这个问题里,我们可以对 w,b w , b 随意加倍而不用考虑 ||w|| | | w | | 的大小了。为了剔除 γ̂ γ ^ 项的干扰,我们适当地选取 w,b w , b 的倍数使得 γ̂ =1 γ ^ = 1 ,再加上最大化 1||w|| 1 | | w | | 相当于最小化 ||w||2 | | w | | 2 ,于是 优化问题 的最终形式可以化为:
对于这样的问题,已经可以用已知的 优化问题 算法来解决。不过对于 SVM,我们会考察一个与之相对应的问题。为了得到这个问题我们需要先了解下 拉格朗日对偶。
拉格朗日对偶
对于 拉格朗日对偶 涉及的问题很多,具体细节我推荐大家看 C299 的讲义和 这篇博客。考虑一般的 凸优化问题:
设它的 拉格朗日函数 为:
考虑函数:
在 w w 满足约束条件的时候 θ(w)=f(w) θ P ( w ) = f ( w ) ,在不满足时 θ(w)=∞ θ P ( w ) = ∞ 。所以下式中的 p∗ p ∗ 的结果与原问题相同。
有意思的是对于这样的问题,总有一个与之对应问题( 对偶问题 ),并且在特定条件下相同。要得到 对偶问题,我们只需要交换 min,max m i n , m a x 的顺序,考虑函数:
对偶问题 的结果 d∗ d ∗ 满足下式,并且由不等式看出它是原问题的一个下界。
最后来看下 对偶问题 的解在什么情况下与 原问题 相同。如果函数 f,g f , g 都是 凸函数, h h 是 放射函数( 线性的 ),并且存在 w w 使得 gi(w)<0 g i ( w ) < 0 ,则优化问题有解 w∗,α∗,β∗ w ∗ , α ∗ , β ∗ ,并有 d∗=p∗=(w∗,α∗,β∗) d ∗ = p ∗ = L ( w ∗ , α ∗ , β ∗ ) 。 这时我们的解满足 KKT 条件,反之满足 KKT 条件的解也是优化问题的解( KKT 条件如下 )。
∂∂wi(w∗,α∗,β∗)=0,i=1,...,m ∂ ∂ w i L ( w ∗ , α ∗ , β ∗ ) = 0 , i = 1 , . . . , m
∂∂βi(w∗,α∗,β∗)=0,i=1,...,l ∂ ∂ β i L ( w ∗ , α ∗ , β ∗ ) = 0 , i = 1 , . . . , l
α∗igi(w∗)=0,i=1,...,k α i ∗ g i ( w ∗ ) = 0 , i = 1 , . . . , k
gi(w∗)≤0,i=1,...,k g i ( w ∗ ) ≤ 0 , i = 1 , . . . , k
αi≥0,i=1,...,k α i ≥ 0 , i = 1 , . . . , k
对偶问题
通过 拉格朗日对偶 我们了解到之前的最大间距问题有一个与它对应的 对偶 问题。接下去我们就通过 拉格朗日对偶 来得到这个问题。
对于之前的问题令 gi(w)=−y(i)(wTx(i)+b)+1≤0 g i ( w ) = − y ( i ) ( w T x ( i ) + b ) + 1 ≤ 0 ,并设 拉格朗日函数 为:
根据对偶问题的定义,我们先对于 w,b w , b 求 (w,b,α) L ( w , b , α ) 的最小值,也就是分别对 w w 和 b b 进行求导得到:
将 w w 带入 (w,b,α) L ( w , b , α ) 进行化简得到:
再加上 αi≥0 α i ≥ 0 与 ∑i=1mαiy(i)=0 ∑ i = 1 m α i y ( i ) = 0 的约束条件,我们得到了最终的 对偶 问题:
红色正是最重要的部分( 尖括号表示内积 ),它使得我们可以运用 核函数 的技巧来降低计算的复杂度,特别是需要将特征映射到很高维甚至是无限维的情况。
核函数
假设每个样本有三个特征 x1,x2,x3 x 1 , x 2 , x 3 ,通常需要把它们映射到更高维来拟合更复杂的函数,让我们假设 映射函数 为:
在映射后两个不同样本间的内积为:
不难发觉映射后 9 个特征之间的内积就等于原先 3 个特征间的内积的平方。其实等式最后的 (xTz)2 ( x T z ) 2 就是 核函数 中的一种。对于有 n n 个特征的情况 核函数 K(x,z)=(xTz)2 K ( x , z ) = ( x T z ) 2 的计算值等于特征映射为 n2 n 2 个时的内积值。对于原本需要计算 n2 n 2 次的内积,通过 核函数 只需要计算 n n 次。更一般的, 核函数 K(x,z)=(xTz+c)d=⟨ϕ(x),ϕ(z)⟩ K ( x , z ) = ( x T z + c ) d = ⟨ ϕ ( x ) , ϕ ( z ) ⟩ 相当于把特征映射到 (n+dd) ( n + d d ) 维。 核函数 中有个非常有意思的 高斯核,它相当于把特征映射到无限维。
所以现在可以理解 核函数 的意义了。由于在 对偶问题 中只涉及特征内积的计算,而 核函数 在低维计算的值等于特征映射到高维后的内积值,因此我们能够获得相当高效的方法来求解我们的问题。( 关于 核函数 更详细的讨论请看 C299 的讲义 )
正则化
简单说说 SVM 的正则化,为了解决数据集线性不可分的情况,我们适当调整原问题,使得间距可以比 1 小,但相应的在优化目标中加入一定的代价。
同样使用 拉格朗日对偶 可以找到它的对应问题,这个问题也就是 SVM 算法所要解决的问题:
SMO 算法
这里介绍一下 SMO 的主要想法,算法的具体细节可以参考论文。对于没有约束条件的优化问题 maxαW(α1,α2,...,αm) max α W ( α 1 , α 2 , . . . , α m ) ,我们可以依次选取 αi α i 并固定其它变量来取得函数的最值,不断这样重复直到函数的值收敛( 如下图 )。
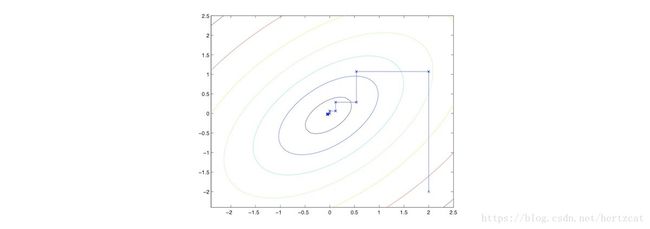
对于 SVM 中的 对偶 问题,思路差不多,每次选取两个变量 αi,αj α i , α j ,固定其它的变量。由于要满足一定的约束条件, αi α i 可以由 αj α j 表示 αi=(ζ−αjy(j))y(i) α i = ( ζ − α j y ( j ) ) y ( i ) 。从而优化目标可以化为一个关于 αj α j 的二次多项式 aα2j+bαj+c a α j 2 + b α j + c 求得最值。当然这里还需要考虑 αj α j 的约束范围,对结果进行剪裁。最后不断重复这个过程直到优化目标收敛。
So~,第六周的内容就是这些了,谢谢大家耐心阅读。
P.S. 这周的内容压缩的有些严重,建议大家好好阅读下 CSS229 的讲义。随着 Andrew Ng 的课程即将接近尾声,我准备开始做一些小项目练练手,毕竟能够学以致用才是真正的学习。对于平时看到啥有意思的东西,有啥有意思的想法都会发在 微博 上,欢迎大家一同学习 (●—●)~