推荐系统老司机的十条经验
本文来源微信公众号:ResysChina,版权归原作者所有,未经作者同意,请勿转载。
原文:推荐系统老司机的十条经验
作者:陈开江@刑无刀,金融科技公司天农科技CTO,曾任新浪微博资深推荐算法工程师,考拉FM算法主管,先后负责微博反垃圾、基础数据挖掘、智能客服平台、个性化推荐等产品的后端算法研发,为考拉FM从零构建了个性化音频推荐系统。
欢迎技术投稿、约稿、给文章纠错,请发送邮件至[email protected]
一年一度的ACM Recsys会议在9月份已经胜利闭幕,留下一堆slides和tutorials等着我们去学习。
翻看今年的各种分享,其中老司机Xavier Amatriain的分享引起了我的兴趣:Lessons Learned from Building Real-Life Recommender Systems。主要分享了作为推荐系统老司机的他,多年开车后总结的禁忌和最佳实践,这样的采坑实录显然是很有价值的。
Xavier Amatriain,曾任Netflix的算法总监,现任Quora的工程副总裁。
Xavier Amatriain在recsys上的分享,是他在推荐系统领域的十条实践经验(这位老司机同样的题目在不同渠道多次分享过,一共有三个版本,加起来去重后不止十条,同学们赚到了),本文只针对他在Recsys2016上的分享一一解读。
一、隐式反馈比显式反馈要爽
所谓隐式反馈,就是用户发出这些行为时并不是为了表达兴趣/态度,只是在正常使用产品而已,反之,显式反馈就是用户在做这个操作时就是要表达自己的态度,如评分,投赞成/反对票。
Xavier Amatriain列举了隐式反馈的以下好处:
- 数据比显式反馈更加稠密。诚然,评分数据总体来说是很稀疏的,之前netflix的百万美元挑战赛给出的数据稀疏度大概是1.2%,毕竟评分数据是要消耗更多注意力的数据。
- 隐式反馈更代表用户的真实想法,比如你不是很赞成川普的观点,但是还是想经常看到他的内容(以便吐槽他),这是显式反馈无法捕捉的。而人们在Quora上投出一些赞成票也许只是为了鼓励一下作者,或者表达一些作者的同情,甚至只是因为政治正确而投,实际上对内容很难说真正感兴趣。
- 隐式反馈常常和模型的目标函数关联更密切,也因此通常更容易在AB测试中和测试指标挂钩。这个好理解,比如CTR预估当然关注的是点击这个隐式反馈。
举个例子,IMDB的电影排名,对比一下用票房排名和用评分排名,票房其实是一种隐式反馈的量化,表示“看过”,而评分则是显式反馈。

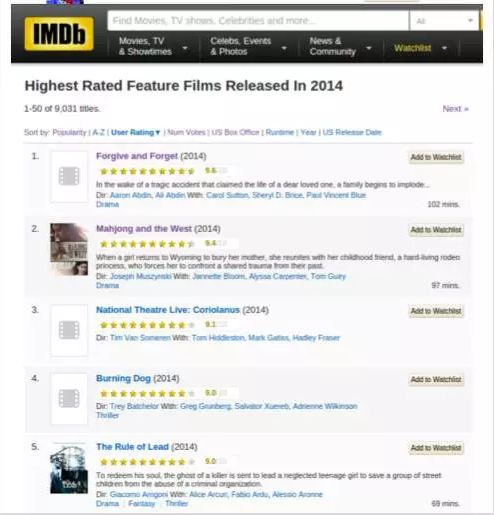
一些小众电影的评分比较少,在依靠评分排名时不太占优势,而依靠隐式反馈排名则会有所缓解。
虽然有诸多好处,但隐式反馈有个比较大的问题就是:短视。现在有很多手段来吸引用户点击,比如高亮的标题,还有一些“三俗”的图片,都会吸引用户点击,这种利用了人性弱点的隐式反馈,对平台的长期价值是有损的,所以也不能一味使用隐式反馈,而是需要隐式反馈和显式反馈结合使用,兼顾短期利益和长期价值。
二、深刻理解数据
Xavier Amatriain举了个例子,训练一个分类器,用来自动识别优质答案或劣质答案。这个问题似乎很简单,实际上你要思考,下面这些答案是好的还是不好的:
- 抖机灵的答案
- 某个领域的网红给了个很短的答案
- 很长、很有料的答案,但是没有人点赞
- 内容有料,但是错别字多
这些都是需要我们去深入业务理解,到底什么样的数据才是我们要找的。
三、为模型定义好学习任务
一个机器学习模型有三个因素构成:
- 训练数据(隐式反馈或者显式反馈)
- 目标函数(比如用户阅读一篇回答的概率)
- 衡量指标(比如准确率或者召回率)
假如现在有这么一个问题:用用户的购物历史以及历史评分,去优化用户走进电影院看完一部电影并且给出高分的概率,NDCG作为模型的评价指标,4分以上作为正样本。
这样就比较清晰的定义了学习任务的三元素:
- 训练数据:用户购物历史和历史评分
- 目标函数:用户走进电影院看完电影且给出高分的概率
- 衡量指标:NDCG
如果定义评价指标时模糊不清,如不说明是4分以上的作为正样本的话,就失去了显式反馈的信息,失去了对平台长期利益的关注。
还有个例子,Quora的兴趣feed排序。

Quora的首页是结合了多个用户隐式反馈的排序模型,给每一种用户行为建立一个预测模型,预测它发生的概率,结合每一种行为带来的长期价值大小,然后加权,即期望价值。这个例子里面的三元素也可定义清楚:
- 训练数据:用户的显式反馈和隐式反馈
- 目标函数:一个story的展示价值,量化定义为用户行为的期望价值
- 衡量指标:任何排序模型指标都可以
四、推荐可解释比精准更有意义
这里其实就是说推荐要展示出理由给用户,让用户知道每一项推荐的项目是怎么得到的。
比如Quora的feed推荐给出的“被你关注的人投票”的理由: 
比如Quora给出的推荐话题给出的“被你关注的人关注”的理由: 
比如Netflix给出的“因为看过给出好评的电影而推荐”的理由: 
五、矩阵分解大法好
Xavier Amatriain很推崇Matrix Factorization,因为它既有监督学习,又有无监督学习。 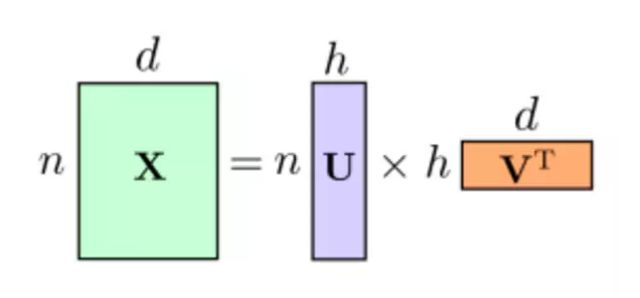
两种学习方法就这样结合在一个算法里:
- 它可以用来降维,这部分通常是PCA这样的无监督学习算法承担的,矩阵分解得到的隐因子就是降维后的特征,可以直接作为其他学习算法的输入;
- 它还可以做聚类,比如Non-negative Matrix Factorization就常常用来做聚类;
- SVD就是一种回归,标准的监督学习。
矩阵分解还有一些变种:ALS(交替最小二乘),SVD++(结合特征的SVD),FM(因子机),TF(张量分解)。
总之,在推荐系统里,使劲压榨矩阵分解的效果。
六、万能的集成方法
Netflix的冠军模型,那可是100多种算法集成在一起的,真是应了那句话:比你效果好的模型还比你更努力。
实际上任何推荐系统也不可能是单一算法在起作用,而是多种算法集成在一起。集成方法理论上不会比你其中那个最好的算法差。在推荐系统中,你至少可以集成基于内容推荐和协同过滤两种。
本质上,集成算法是把某个模型的输出变成另一个模型的特征。如果你很难决策到底用哪个算法时,千万不要纠结,所有的都用,然后集成之。
集成还有一个好处就是:某个推荐算法可能更适合某个场景下,这样被集成的算法就可以各自handle各自擅长的场景,最后集大成。
具体集成方法可选的很多,如logistic regression,GBDT,Random Forest,ANN。
七、推荐系统也不能免俗之特征工程
谈机器学习必谈特征工程,虽然深度学习的大火让某些领域的机器学习应用更加端到端了,但是推荐系统这个王国里面,特征工程还是要谈一谈,
好的特征有以下特点:
- 可复用。可复用就是说不止一个模型可以用,换个模型一样用。
- 可转换。特征是既可以直接使用,也可以进行一些尺度转换的,比如对数转换等。
- 可解释。特征的物理意义需要很清楚。
- 可靠。特征出现异常的话需要能及时监控到,也要容易调试。
Xavier以Quora的答案排序为例,举了一些他们现在用到的特征算是好特征:
一个是答案本身的特征,如回答的质量;第二个是互动类型的特征,如投票,评论;还有用户特征,如他在某个话题下的专业程度。
深度学习给了另一种全新的特征工程之路,也是值得探索的,或许是人工特征工程的终结者,拭目以待。
八、对你的推荐系统要了如指掌
推荐系统里面,模型对于很多人来说都是黑盒子,甚至对于算法工程师自己来说也是黑盒子,并不太清楚某个东西为什么被推出来,某个东西为什么用户没买帐或者买帐。
通常产品经理对推荐系统都有一定的预期,推荐的东西不能让他们理解,解释起来也比较麻烦,也是通常算法工程师和PM产生争端的原因所在。对于黑盒一般的模型,我们要能够做到可以回答任何人的任何问题。模型应该做到“可调试”(debuggability)。
举个例子,一个决策树算法,从根节点开始,一步一步经过了哪些决策节点得到了最终的预测结果呢?如果有工具可以直观展现出来,我们就能知道哪些特征起了更重要的作用,是不是合理的。

Xavier 提到在Quora内部就有个工具,可以看到某个人的首页feed的每一个内容的分数,以及每个分数计算所依赖的特征,这样就很清楚知道为什么你“看到/没看到”某个人的回答或问题。 

九、数据和模型是重要,但正确的演进路径更不容忽视
老司机说,这条经验他很看重。这条经验告诉我们,一个推荐系统的产品功能如何一步一步从0到上线的。 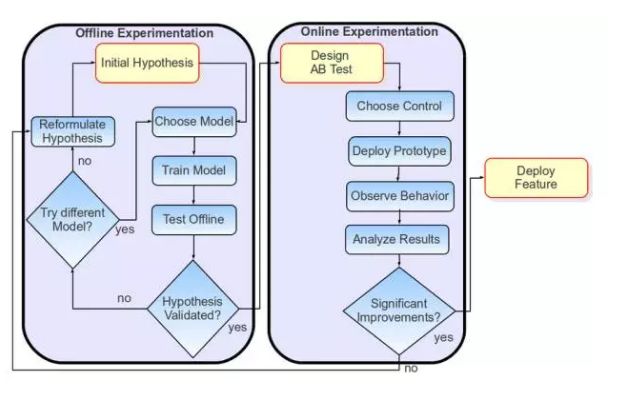
通常,正确的演进路径是这样:
- 首先提出一个假设,可以通俗的说是对问题的一个猜想。
- 针对这个假设,我们要选择用什么模型。
- 模型选定后训练模型,离线测试,如果验证通过就要上AB测试,否则要么换个模型,要么重新审视一下你的假设是不是站得住脚;
- 上AB测试,测试结果明显提升的话就上线,否则滚回去再看看最开始你那个假设是不是靠谱。
这个过程有几个地方比较难。
第一个就是离线模型评价指标的选择,不同的指标可能包含不同的意义,例如同样是Learn to rank的排序评价,MRR和NDCG这两个指标对于排序靠前的项目权重就会更大,而FCP(Fraction of Concordant Pairs)就更看重排序靠中间的项目。所以选择什么指标要仔细思考,离线评价表现好才有机会有必要上AB测试。
第二个就是离线评价(通常是技术性或者学术性的,比如准确率)和在线产品指标(通常是商业性的,比如留存率)之间通常是存在鸿沟的。模型的离线评价效果可能很好,但是在线去测试,产品指标可能表现不好,可以离线的时候换一个与直接产品指标更相关的评价指标。
第三个就是AB测试的时候一定注意要有一个总体评价指标( Overall Evaluation Criteria),很多人(通常是产品经理)会同时关注一个AB测试的很多指标,点击率上去了,多样性又下去了,这种测试结果你很难说是该上线还是该下线,所以说需要一个 Overall Evaluation Criteria,如果你有多个目标,就想法把多个目标整合成一个数值指标,这样才能够最终决定AB测试是成功还是失败。 Overall Evaluation Criteria通常是更接近商业目标和平台长期价值的数值,要定义出来需要深度的思考。
最后提一下,AB测试并不是唯一确定新算法是否上线的方式,还有一种方法是bandit算法,见专治选择困难症——bandit算法。
十、别一言不合就要上分布式
Hadoop,spark,mapreduce,这些名词背后有一个共同的概念:分布式。
现在,所谓的大数据项目也是言必称分布式,那么是不是都需要分布式呢?尤其是模型部分?老司机Xavier认为,大多数推荐算法不需要分布式,毕竟我们的推荐系统中很少会有训练计算机从海量视频中识别什么是猫这样的算法。
Xavier说,很多算法其实都是可以在单机上完成的(多核的单机),那为什么大家又很少这样做呢?究其原因有几个:
- 分布式平台的确降低了处理大数据的门槛,稍微写点胶水代码就可以操作成T上P的数据,工程师们不用懂太多分布式本身的知识;
- 一些在单机上并行处理数据的方法不为人知,比如像C++中的openmp这样的库,很多人并不知道,它可以充分发挥多核机器的作用。还有Linux本身有很多并行化的命令,比如grep,wc等;
- 掌握的数据采样方法不够不精。对全量数据采样,以使之在单机上能够计算且不明显损失信息,这是一门精致的手艺,很多人并不掌握。
Xavier说在Quora,曾经用Spark实现了一个计算任务,需要15台机器跑6小时才能跑完,而某个工程师花了四天时间研究spark慢在哪,然后用C++写了一个单机版,只用10分钟就跑完整个任务。说到这里,我也同样的经验,曾经用Spark跑协同过滤,四个小时没有跑完,组内的董玮博士用C++写了一个单机版,用openmp库把所有的核都用上,30分钟就计算完了。
说到这里,常见的推荐算法有很多分布式的库,比如Spark中就有MLib库,但是也可以试试一些著名的单机版,如GraphChi。
参考资料:
[1]http://www.slideshare.net/xamat/recsys-2016-tutorial-lessons-learned-from-building-reallife-recommender-systems
[2]http://www.slideshare.net/xamat/strata-2016-lessons-learned-from-building-reallife-machine-learning-systems
[3]https://chatbotnewsdaily.com/10-more-lessons-learned-from-building-real-life-ml-systems-part-i-b309cafc7b5e#.vmuuaznyk
[4]https://medium.com/@xamat/10-more-lessons-learned-from-building-real-life-machine-learning-systems-part-ii-93fe7008fa9#.e4p4bl23f
[5]https://www.youtube.com/watch?v=88tzDSOzVUQ