实时查询引擎 - 构建于HDFS之上的Greenplum: HAWQ
1. HAWQ 是什么
如果你知道Greenplum是什么,那么你就能很简单的明白HAWQ是什么。Greenplum是一个关系型的分布式MPP数据库,同样运行于X86架构的基础之上,具有查询、加载效率高,支持TB/PB级大数据量的OLAP应用, Greenplum的所有数据都存储于系统本地文件系统中。而HAWQ的最大改变就是将本地文件系统存储更换为了HDFS,成功的搭上了大数据库的班车。不过HAWQ相较于其它的SQL on Hadoop组件来说,也是具有很多优势的,比如:
- 对SQL的完善支持,以及语法上的OLAP扩展支持
- 具有比较成熟的SQL并行优化器,而这正是其它SQL on Hadoop组件比较欠缺的。
- 支持ACID事务特性,这个在其它SQL on Hadoop组件也是比较欠缺的。
- 支持多语言的UDF支持:Python, Perl, Java, C/C++, R
- 等等,反正比较牛B,原Greenplum上支持的功能在HAWQ基本都能找到。
2. HAWQ 结构
HAWQ在结构仍然是Master-Slave的主从模式,典型的部署方式仍然是在Master服务器上部署:HAWQ Master, HDFS Master, YARN ResouceManager, 在每一个SLAVE机器上部署: HAWQ segment, DataNode, NodeManager。具体结构看图:
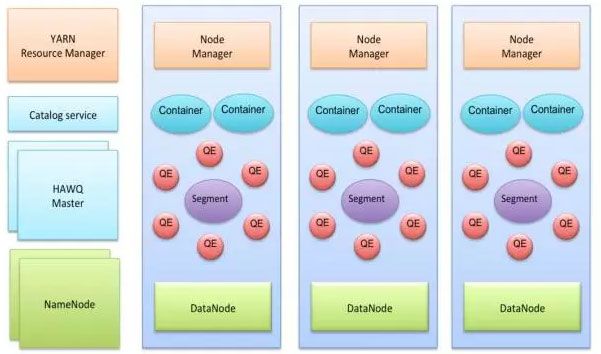
下面是一张HAWQ的软件组件图:
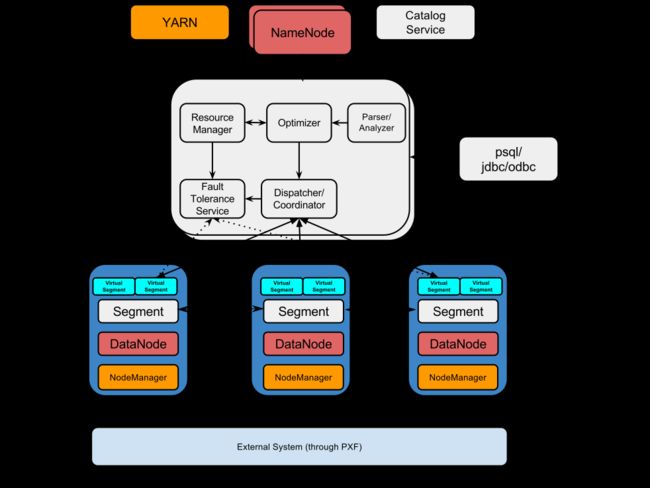
可以看出HAWQ包含了好几个重要的组件,分别是:
1. HAWQ Master
HAWQ Master是整个系统的接口,它负责接收客户端查询请求,解析SQL,优化查询,分发和协调查询的执行。当然作为老大,任务肯定不是这么简单的,它还得负责global system catalog的管理工作。
2. HAWQ Segment
Segments是并行处理数据的单元。每一个Slave机器上部署的HAWQ程序叫作物理Segment,而且第一台Slave上只能部署一个物理Segment。一个物理Segment上可以运行多个虚拟Segment(一个查询解析后的并行分片就是虚拟Segment).虚拟Segment的数量决定了一个查询的并行度。
3. HAWQ Interconnect
Segment之间的高速通信网络,默认采用UDP协议,并且HAWQ软件提供了针对UDP额外的数据包验证。使其可靠性接近于TCP,但性能和可扩展性又比TCP好。HAWQ也可以使用TCP进行通信,但有最大1000个Segment的限制。而使用UDP则没有该限制。
4. HAWQ Resource Manager
HAWQ资源管理用于从YARN获取资源并响应资源请求。同时HAWQ会缓存资源用于低延迟的查询请求。除了使用YARN来管理资源外,HAWQ还可以使用自带的资源管理器,而不需要YARN.
5. HAWQ Catalog Service
元数据服务存在于HAWQ Master中。作用肯定就是用于存储metadata.比如UDF,表信息等。以及提供元数据的查询服务。
6. HAWQ Fault Tolerance Service
容错服务自然就是针对各个Segment节点的状态监控和失败处理等工作。
7. HAWQ Dispatcher
HAWQ分发器是则是分发查询到指定的Segment上和coordinates上进行执行。
3. HAWQ 安装
如果你安装过Greenplum,那么你会发现HAWQ的安装过程与Greenplum是极期相似,必竟它们两可以说是不同存储的版本。而整个安装过程相对其它实时组件来说,还是比较繁琐的。同时也可以看出来HAWQ是基于HDFS的独立数据库。而不像其它实时查询组件除了HDFS,可能还需要依赖于其它Hadoop组件。
本文的测试环境为基于CDH 5.5的Hadoop集群环境的安装和测试。HAWQ的版本为:2.0.0, 另外HAWQ还可以使用Ambari图形界面安装。发竟安装过程请看:
1. 设置系统参数,更改文件/etc/sysctl.conf,增加内容:
kernel.shmmax = 1000000000
kernel.shmmni = 4096
kernel.shmall = 4000000000
kernel.sem = 250 512000 100 2048
kernel.sysrq = 1
kernel.core_uses_pid = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.msgmni = 2048
net.ipv4.tcp_syncookies = 0
net.ipv4.ip_forward = 0
net.ipv4.conf.default.accept_source_route = 0
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_syn_backlog = 200000
net.ipv4.conf.all.arp_filter = 1
net.ipv4.ip_local_port_range = 1281 65535
net.core.netdev_max_backlog = 200000
vm.overcommit_memory = 50
fs.nr_open = 3000000
kernel.threads-max = 798720
kernel.pid_max = 798720
# increase network
net.core.rmem_max=2097152
net.core.wmem_max=2097152 然后使用命令sysctl -p生效
2. 更改文件/etc/security/limits.conf,增加内容:
* soft nofile 2900000
* hard nofile 2900000
* soft nproc 131072
* hard nproc 1310723. 安装epel-release包。该包在 http://fedoraproject.org/wiki/EPEL 官网下载后,安装到每一台集群节点上:
rpm -ivh epel-release-latest-6.noarch.rpm4. 选择一台服务器上,配置HAWQ安装的YUM源
#启动httpd 服务,如果没有安装使用yum安装并启动:
service httpd start
#解压hdb 包:
tar -xzvf hdb-2.0.0.0-22126.tar.gz
cd hdb-2.0.0.0 #进到解压后的目录
./setup_repo.sh #执行脚本创建YUM源
#将生成的/etc/yum.repos.d/HDB.repo源文件拷由到每台集群节点上5. 先只在主节点上安装HAWQ:
yum install hawq6. 在主节点上创建主机名文件
创建文件 hostfile包含集群所有主机(包含MASTER),如:
[root@master hzh]# cat hostfile
master
slave2
slave3
slave4
5.创建文件仅包含seg(Slave)主机,如:
[root@master hzh]# cat seg_hosts
slave2
slave3
slave47. 打通各主机root用户ssh
source /usr/local/hawq/greenplum_path.sh
hawq ssh-exkeys -f hostfile #这里的hostfile就是上面创建的那个文件8. 然后在每个节点上安装hawq:
source /usr/local/hawq/greenplum_path.sh
hawq ssh -f hostfile -e "yum install -y epel-release"
hawq ssh -f hostfile -e "yum install -y hawq"9. 在每个节点上增加gpadmin用户,并设置密码
hawq ssh -f hostfile -e '/usr/sbin/useradd gpadmin'
hawq ssh –f hostfile -e 'echo -e "changeme\changeme" | passwd gpadmin'10. 在主节点上切换到gpadmin 用户,打通每个节点的ssh
su - gpadmin
source /usr/local/hawq/greenplum_path.sh
hawq ssh-exkeys -f hostfile11. 检查安装是否完成,在gpadmin用户下执行:
hawq ssh -f hostfile -e "ls -l $GPHOME" #如有输出目录文件则安装成功12. 创建hawq的数据存储目录:
hawq ssh -f hostfile -e 'mkdir -p /hawq/master' #主节点目录数据存放位置
hawq ssh -f hostfile -e 'mkdir -p /hawq/segment' #segment 节点数据存放目录
hawq ssh -f hostfile -e 'mkdir -p /hawq/tmp' #spill临时数据存放目录,每台服务器可以建多个
hawq ssh -f hostfile -e 'chown -R gpadmin /hawq'13.编辑hawq-site.xml文件在 $GP_HOME/etc/, 如果文件不存在,直接从template-hawq-site.xml复制一个出来就是,属性设置包括:
<property>
<name>hawq_dfs_urlname>
<value>localhost:8020/hawqvalue> # hdfs的URL, 也可以设置成HDFS HA: <value>hdpcluster/hawqvalue>
#注意前面不要带hdfs://前缀
<description>URL for accessing HDFS.description>
property>另外还要包括属性:
| Property | Example Value |
|---|---|
| hawq_master_address_host | mdw |
| hawq_master_address_port | 5432 |
| hawq_standby_address_host | smdw |
| hawq_segment_address_port | 40000 |
| hawq_master_directory | /data/master |
| hawq_segment_directory | /data/segment |
| hawq_master_temp_directory | /data1/tmp,/data2/tmp |
| hawq_segment_temp_directory | /data1/tmp,/data2/tmp |
| hawq_global_rm_type | none |
* 注意如果你需要安装HAWQ在 secure mode (Kerberos-enabled),则需要设置hawq_global_rm_type为none,来避开已知的安装问题。 这里设置为none,就是没有采用YARN来作资源管理,而使用了自带的标准模式。
14. 创建HDFS /hawq数据目录
hadoop fs -mkdir /hawq
hadoop fs -chown gpadmin /hawq15. 创建 $GPHOME/etc/slaves文件包含所有segment机器的主机名,如:
[root@master etc]# cat slaves
slave2
slave3
slave416.如果HDFS是使用的HA模式,则需要在${GPHOME}/etc/hdfs-client.xml下配置一个hdfs-client.xml文件。幸好这里是单机,少配一个.
17. 将以上的hawq-site.xml slaves hdfs-client.xml文件拷贝到集群的每个节点上。
18. 准备工作终于作完了,接下来开始干正事了,初始化HAWQ
chown -R gpadmin /usr/local/hawq-2.0.0.0 #先要给安装目录授权,在每一台
#仅在主节点上,使用gpadmin 用户执行:
hawq init cluster初始后后,HAWQ就安装完成啦,你可以使用以下命令检查集群状态:
[gpadmin@master ~]$ hawq state
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:--HAWQ instance status summary
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:------------------------------------------------------
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Master instance = Active
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- No Standby master defined
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total segment instance count from config file = 3
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:------------------------------------------------------
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Segment Status
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:------------------------------------------------------
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total segments count from catalog = 3
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total segment valid (at master) = 3
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total segment failures (at master) = 0
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total number of postmaster.pid files missing = 0
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total number of postmaster.pid files found = 34. 使用HAWQ
在HAWQ的使用上跟Greenplum基本就一样一样的了。比如:
1. 创建表空间
#选创建filespace,生成配置文件
[gpadmin@master ~]$ hawq filespace -o hawqfilespace_config
Enter a name for this filespace
> hawqfs
Enter replica num for filespace. If 0, default replica num is used (default=3)
> 0
Please specify the DFS location for the filespace (for example: localhost:9000/fs)
location> master:8020/fs
#执行创建
[gpadmin@master ~]$ hawq filespace --config ./hawqfilespace_config
Reading Configuration file: './hawqfilespace_config'
CREATE FILESPACE hawqfs ON hdfs
('slave2:8020/fs/hawqfs')
20161121:11:26:25:122509 hawqfilespace:master:gpadmin-[INFO]:-Connecting to database
20161121:11:27:38:122509 hawqfilespace:master:gpadmin-[INFO]:-Filespace "hawqfs" successfully created
#再创建表空间
[gpadmin@master ~]$ psql template1
psql (8.2.15)
Type "help" for help.
template1=#
template1=# CREATE TABLESPACE hawqts FILESPACE hawqfs;
CREATE TABLESPACE2. 创建数据库
template1=# CREATE DATABASE testdb WITH TABLESPACE=hawqts; #指定存储表空间为hawqts
CREATE DATABASE3. 创建表到新的数据库中
[gpadmin@master ~]$ psql testdb //这里指定连接到新的数据库中
testdb=# create TABLE books(
testdb(# id integer
testdb(# , isbn varchar(100)
testdb(# , category varchar(100)
testdb(# , publish_date TIMESTAMP
testdb(# , publisher varchar(100)
testdb(# , price money
testdb(# ) DISTRIBUTED BY (id); #指定表的数据打散列
CREATE TABLE 创建的表默认都创建在了public schema中,也就是所有用户都可以访问,但可以在建表时指定schema. 如: testschema.books
4. 加载数据文件到表中
testdb=# COPY books(id,isbn,category,publish_date,publisher,price)
testdb-# FROM '/tmp/books'
testdb-# WITH
testdb-# DELIMITER AS '|'
testdb-# ;
COPY 15970428
Time: 41562.606 ms 加载速度达到了 380248条/秒. 还是不错的
5. 查询表, HAWQ作为主用于数据仓库的数据库在SQL支持方面非常丰富,在标准SQL基础上,还支持OLAP的窗口函数,窗口函数等。
testdb=# SELECT COUNT(*) FROM books;
count
----------
15970428
(1 row)
Time: 4750.786 ms
//求每个类别下的最高价,最低价
testdb=# SELECT category, max(price) max_price, min(price) min_price
testdb-# FROM books
testdb-# group by category
testdb-# LIMIT 5;
category | max_price | min_price
----------------+-----------+-----------
COMPUTERS | $199.99 | $5.99
SELF-HELP | $199.99 | $5.99
COOKING | $199.99 | $5.99
SOCIAL-SCIENCE | $199.99 | $5.99
SCIENCE | $199.99 | $5.99
(5 rows)
Time: 4755.163 ms
//求每类别下的最高,最小价格,及对应的BOOK ID
testdb=# SELECT category
testdb-# , max(case when desc_rn = 1 then id end) max_price_id, max(case when desc_rn = 1 then id end) max_price
testdb-# , max(case when asc_rn = 1 then id end) min_price_id, max(case when asc_rn = 1 then id end) min_price
testdb-# FROM (
testdb(# SELECT id, category, price
testdb(# , row_number() over(PARTITION BY category ORDER BY price desc) desc_rn
testdb(# , row_number() over(PARTITION BY category ORDER BY price asc) asc_rn
testdb(# FROM books
testdb(# ) t
testdb-# WHERE desc_rn = 1 or asc_rn = 1
testdb-# GROUP BY category
testdb-# limit 5;
category | max_price_id | max_price | min_price_id | min_price
----------------+--------------+-----------+--------------+-----------
CRAFTS-HOBBIES | 86389 | $199.99 | 7731780 | $5.99
GAMES | 5747114 | $199.99 | 10972216 | $5.99
STUDY-AIDS | 2303276 | $199.99 | 13723321 | $5.99
ARCHITECTURE | 9294400 | $199.99 | 7357451 | $5.99
POETRY | 7501765 | $199.99 | 554714 | $5.99
(5 rows)
Time: 23522.772 ms5. 使用HAWQ查询HIVE数据
HAWQ是一个基于HDFS的一个独立的数据库系统,若需要访问其它第三方数据,则还需要再安装HAWQ Extension Framework (PXF) 插件。PXF支持在HDFS上的HIVE, HBASE数据,还支持用户开发自定义的其它并行数据源的连接器。
6. 问题
7. 最后
HAWQ作为一个从Greenplum更改过来的系统,在功能上支持上还是非常丰富的,除了上面介绍的查询功能外,还支持像PL/Java, PL/Perl, PL/pgSQL, PL/Python, PL/R等存储过程。但个人觉得,它最大的缺点就是这是一个独立的数据库,在当前的这样一个具有多种多样组件的HADOOP平台上,不能实现数据共享,进而根据不同场景采用多种数据处理方式着实是一大遗憾。