论文阅读CVPR2019——Stereo R-CNN based 3D Object Detection for Autonomous Driving
这是一篇来自DJI与港科大合作的文章,作者分别是li peiliang,陈晓智 @陈晓智(DJI,MV3D的作者)和港科大的shenshaojie老师。
论文链接:https://arxiv.org/pdf/1902.09738.pdf
摘要
这篇文章通过充分利用立体图像中的稀疏,密集,语义和几何信息,提出了一种用于自动驾驶的称为立体声R-CNN的三维物体检测方法。扩展了Faster R-CNN用于立体声输入,以同时检测和关联左右图像中的对象。 通过在立体区域提议网络(RPN)之后添加额外分支以预测稀疏关键点,视点和对象维度,其与2D左右框组合以计算粗略的3D对象边界框。 然后,通过使用左右RoI的基于区域的光度对准来恢复精确的3D边界框。 该方法不需要深度输入和3D位置,但是,效果优于所有现有的完全监督的基于图像的方法。 在具有挑战性的KITTI数据集上的实验表明,该方法在3D检测和3D定位任务上的性能优于最先进的基于立体的方法约30%AP。
1. introduction
2018年在3D检测方面的文章层出不穷,也是各个公司无人驾驶或者机器人学部门关注的重点,包含了点云,点云图像融合,以及单目3D检测,但是在双目视觉方面的贡献还是比较少,自从3DOP之后。
总体来说,图像的检测距离,图像的density以及context信息,在3D检测中是不可或缺的一部分,因此作者在这篇文章中挖掘了双目视觉做3D检测的的潜力。
2. network structure
与单帧检测器(如Faster R-CNN)相比,Stereo R-CNN可以同时检测并关联左右图像的2D边界框,并进行微小修改。使用权重共享ResNet-101和FPN 作为骨干网络来提取左右图像的一致特征。 受益于我们的训练目标设计图2,没有额外的数据关联计算。

Stereo RCNN网络结构如图:
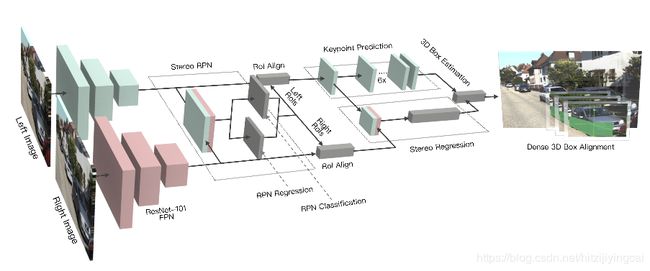
整个网络结构分为以下的几个部分。
1). RPN部分,作者将左右目的图像通过stereoRPN产生相应的proposal。具体来说stereo RPN是在FPN的基础上,将每个FPN的scale上的feature map的进行concat的结构。
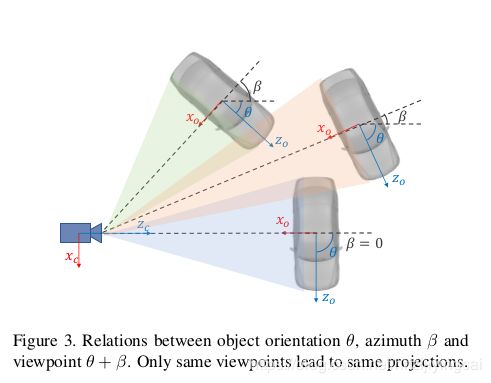
2). Stereo Regression,在RPN之后,通过RoiAlign的操作,得到each FPN scale下的left and right Roi features,然后concat相应的特征,经过fc层得到object class, stereo bounding boxes dimension还有viewpoint angle(下图所示) 的值。这里解释一下viewpoint,根据Figure3.,假定物体的朝向是 ,车中心和camera中心的方位角是 ,那么viewpoint的角度 ,当然,为了避免角度的歧义性,这边作者回归的量还是[ ]。
3). keypoint的检测。这里采用的是类似于mask rcnn的结构进行关键点的预测。文章定义了4个3D semantic keypoint,即车辆底部的3D corner point,同时将这4个点投影到图像,得到4个perspective keypoint,这4个点在3D bbox regression起到一定的作用,我们在下一部分再介绍。
在keypoint检测任务中,作者利用RoiAlign得到的14*14feature map,经过conv,deconv最后得到6 * 28 * 28的feature map,注意到只有keypoint的u坐标会提供2D Box以外的信息,因此,处于减少计算量的目的,作者aggregate每一列的feature,得到6 * 28的output,其中,前4个channel代表4个keypoint被投影到相应的u坐标的概率,后面两个channel代表是left or right boundary上的keypoint的概率。
3. 3D Box Estimation
通过网络回归得到的2D box的dimension,viewpoint,还有keypoint,我们可以通过一定的方式得到3D box的位置。定义3D box的状态x = [x, y, z, θ]。

Figure 5,给出了一些稀疏的约束。包含了特征点的映射过程。这里也体现了keypoint的用处。

上述公式即为约束方程,因此可以通过高斯牛顿的方法直接求解。具体可以参考论文的引文17。这里我们简单证明一下第一个公式。注意,这里的假设都是u,v坐标都已经经过相机内参的归一化了。

4. Dense 3D Box Alignment
这里就回到shenshaojie老师比较熟悉的BA的过程了,由于part 3仅仅只是一个object level的深度,这里文章利用最小化左右视图的RGB的值,得到一个更加refine的过程。定义如下的误差函数
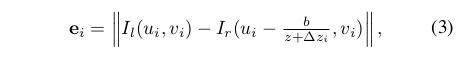
其中 代表第i个pixel的深度与相对应的3D box的深度差。而这一块的求解利用G20或者ceres也可以完成。整个alignment过程其实相对于深度的直接预测是更加robust的,因为这种预测方法,避免了全局的depth estimation中的一些invalid的pixel引起的ill problem的问题。
5. experiment
作者在实验这块达到了双目视觉的state of art,同时对于各个module也做了很充足的实验。在具有挑战性的KITTI物体检测基准上评估该方法。 为了全面评估基于Stereo R-CNN的方法的性能,通过与现有技术和自我消融进行比较,使用2D立体回忆,2D检测,立体关联,3D检测和3D定位指标进行实验。
Stereo Recall and Stereo Detection:Stereo R-CNN旨在同时检测和关联左右图像的对象。 除了评估左右图像上的2D平均重呼叫(AR)和2D平均精度(AP 2d)之外,还定义了立体声AR和立体声AP度量。

stereo AR和stereo AP度量共同评估2D检测和关联性能。 如表1所示,stereo R-CNN在单个图像上具有与Faster R-CNN相似的提议回忆和检测精度,同时在左右图像中产生高质量的数据关联而无需额外的计算。 虽然stereo AR略低于RPN中的左AR,但在R-CNN之后观察到几乎相同的左,右和stereo AP,这表明左右图像上的一致检测性能以及几乎所有真正的正向盒子。 左图有相应的正阳性右框。 还测试了左右特征融合的两种策略:元素均值和通道级联。 如表1所示,通道串联显示出更好的性能,因为它保留了所有信息。
3D Detection and 3D Localization.
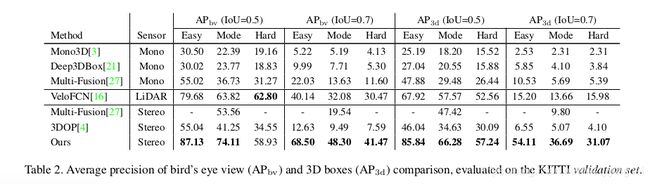
如表2,使用针对鸟瞰图(AP bv)和3D框(AP 3d)的平均精度来评估我们的3D检测和3D定位性能。
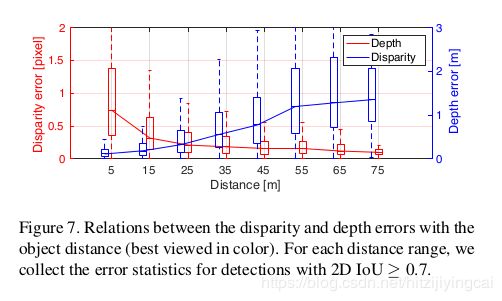
请注意,KITTI 3D检测基准测试很难用于基于图像的方法,随着物体距离的增加,3D性能会逐渐降低。 在图7中可以直观地观察到这种现象,尽管该方法实现了子像素视差估计(小于0.5像素),但是由于视差和深度之间的反比关系,随着物距增加,深度误差变得更大。 对于具有明显差异的对象,基于严格的几何约束实现高精度的深度估计。 这就解释了为什么更高的IoU阈值,对象所属的更容易的制度,与其他方法相比,该方法获得了更多的改进。
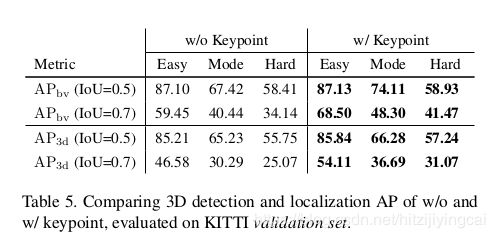
Benefits of the Keypoint.如表5所示,关键点的使用通过非平凡边缘改善了所有难度制度下的AP bv和AP 3D。 由于关键点除了2D盒级测量之外还为3D盒角提供像素级约束,因此它可确保更准确的本地化性能。
Benefits of the Dense Alignment.该实验显示了密集对齐带来的显着改进。 评估粗3D盒(无对齐)的3D性能,其中深度信息是根据盒级视差和2D盒尺寸计算的。 即使1像素视差或2D盒子错误也会导致远距离物体的大距离误差。 结果,虽然粗糙的3D盒子在图像上具有我们预期的精确投影,但它对于3D定位来说不够准确。 详细统计数据见表6。

6. Conclusion and Future Work
首先,整个文章将传统的detection的任务,结合了geometry constraint优化的方式,做到了3D位置的估计,想法其实在不少文章sfm-learner之类的文章已经有体现过了,不过用在3Ddetection上面还是比较新颖,避免了做双目匹配估计深度的过程。也属于slam跟深度学习结合的一篇文章,感兴趣的朋友可以继续看看arxiv.org/abs/1802.0552等相关文章.
在本文中,提出了一种基于立体声R-CNN的自动驾驶场景中的三维物体检测方法。 将3D对象定位表示为学习辅助几何问题,方法利用了语义属性和对象的密集约束。 如果没有3D监督,在3D检测和3D定位任务上的表现优于所有现有的基于图像的方法,甚至优于基线LiDAR方法。
3D对象检测框架灵活实用,可以扩展和进一步改进每个模块。 例如,立体声R-CNN可以扩展用于多个物体检测和跟踪。 我们可以用实例分割替换边界关键点,以提供更精确的有效RoI选择。 通过学习物体形状,3D检测方法可以进一步应用于一般物体。
谈几点个人意义上的不足吧,首先耗时过程0.28s的inference time,不过可能作者的重点也不在这个方面,特征的利用上可以更加有效率,在实现上。其次,能不能采用deep3dbox的方式预测dimension,然后添加入优化项呢...总体来说,是一篇不错的值得一读的文章!