强化学习之无模型方法一:蒙特卡洛
无模型方法(model-free)
无模型方法是学习方法的一种,MDPs中如果P,R未知,则用无模型方法。该方法需要智能体与环境进行交互(交互的方式多样),一般采用样本备份,需要结合充分的探索。
由于未知环境模型,则无法预知自己的后继状态和奖励值,通过与环境进行交互然后观察环境返回的值。本质上从概率分布 Pass′ P s s ′ a 和 Ras R s a 中进行采样。对于随机变量 S′ S ′ 和R的采样,需要实现完整的轨迹还需要确定A,采样足够充分时,可以使用样本分布良好刻画总体分布
无模型学习 vs 动态规划
| 无模型学习 | 动态规划 |
|---|---|
| 未知环境模型 | 已知环境模型 |
| 需要与环境进行交互,有交互成本 | 不需要直接交互,直接利用环境模型推导 |
| 样本备份 | 全宽备份 |
| 异步备份 | 同步和异步 |
| 需要充分探索 | 无探索 |
| 两个策略(行为策略和目标策略) | 一个策略 |
行为策略 vs 目标策略
行为策略是智能体与环境交互的策略,目标策略是我们要学习的策略。
| 在策略(on-policy)学习 | 离策略(off-policy)学习 |
|---|---|
| 行为策略和目标策略是一个策略 | 行为策略和目标策略不是同一个策略 |
| 直接使用样本统计属性去估计总体 | 一般行为策略 μ μ 选用随机性策略,目标策略 π π 选用确定性策略,需要结合重要性采样才能使用样本估计总体 |
| 更简单,收敛性更好 | 方差更大,收敛性更差 |
| 数据利用性更差(只有智能体当前交互的样本能够被利用) | 数据利用性更好(可以使用其他智能体交互的样本) |
| 限定了学习过程中的策略是随机性策略 | 行为策略需要比目标策略更具备探索性。在每个状态下,目标策略的可行动作是行为策略可行动作的子集: π(a|s)>0==>μ(a|s)>0 π ( a | s ) > 0 ==> μ ( a | s ) > 0 |
重要性采样
重要性采样是一种估计概率分布期望的技术,使用了来自其他概率分布的样本,主要用于无法直接采样原分布的情况,估计期望值是,需要加权概率分布的比值(称为重要性采样率)
例:估计全班身高,总体男女比例1:2,由于某些限制,只能按男女比例2:1去采样,如果不考虑采样的分布形式,直接平均得到的值就有问题,因此需要加权,加权比例是1:4去加权
考虑t时刻之后的动作状态轨迹 ρt=At,St+1,At+1,...,ST ρ t = A t , S t + 1 , A t + 1 , . . . , S T ,可以得到该轨迹出现的概率为:
相应的重要性采样率为
如上可知即便未知环境模型,也能得到重要性采样率
蒙特卡洛方法(Monte-Carlo,MC)
MC方法可以被用于任意设计随机变量的估计,这里MC方法指利用统计平均估计期望值的方法。强化学习中存在很多估计期望值的计算 vπ,v∗ v π , v ∗ ,使用MC方法只需要利用经验数据,不需要P,R。MC方法从完整的片段中学习,该方法仅用于片段性任务(必须有终止条件)
下图分别为蒙特卡罗方法采样和动态规划采样的示意图
- 蒙特卡洛方法指采取一条完整的链路,未考虑全局,只通过一条链路的平均回报来估计值函数,方差较大
- 动态规划方法使用所有后继状态进行全宽备份

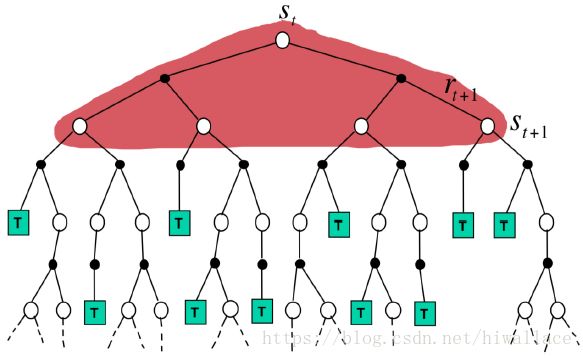
蒙特卡洛策略评价
MC利用了值函数的定义
MC策略评价使用回报值得经验平均来估计实际期望值,而不用贝尔曼期望方程
首次拜访(First-visit)MC策略评价
为了评价状态s,使用给定的策略 π π 采样大量的轨迹,在每一条轨迹中,对于状态s 首次出现的时间t,增加状态数量N(s) ← ← N(s)+1,增加总回报值 Gsum(s)←Gsum(s)+Gt G s u m ( s ) ← G s u m ( s ) + G t ,计算平均值得到值函数的估计 V(s)=Gsum(s)N(s) V ( s ) = G s u m ( s ) N ( s ) 。由于每条轨迹都是独立同分布的,根据大数定律,随着 N(s)→∞,V(s)→vπ(s) N ( s ) → ∞ , V ( s ) → v π ( s ) ,在MC方法下,V(s)是 vπ(s) v π ( s ) 是无偏估计每次拜访(Every-visit)MC策略评价
如上方法,统计在一条轨迹中,对于状态s 每次出现的时间t的状态和回报进行统计,统计均值估计总体。收敛性的证明不如首次拜访MC策略评价直观,更容易拓展函数逼近和资格迹对Q函数的MC方法
一般没有模型的时候,一般我们选择估计Q函数,因为我们可以通过Q函数直接得到贪婪的策略,最优的Q函数可以得到最优的策略(离策略MC策略评价
在采样轨迹使用策略 μ μ ,计算值函数是 π π ,使用重要性采样率去加权回报值
Gπμt=∏k=tT−1π(Ak|Sk)μ(Ak|Sk)Gt G t π μ = ∏ k = t T − 1 π ( A k | S k ) μ ( A k | S k ) G t
将所有在策略的MC算法中的 Gt G t 替换成 Gπμt G t π μ ,使用重要性采样会显著增加方差,可能得到无限大
Var[X]=E[X2]−X2 V a r [ X ] = E [ X 2 ] − X 2
MC的特点小结
- 偏差为0,是无偏估计
- 方差较大,需要大量数据去消除
- 收敛性较好
- 容易理解和使用
- 没有利用马尔可夫性,有时可以用在非马尔可夫环境
增量式蒙特卡洛算法
之前的蒙特卡洛算法需要采样大量轨迹之后再统一计算平均值,能否在每一条轨迹之后都得到值函数的估计值,以节省内存呢?
平均值以增量形式进行计算:
增量式MC更新,采样轨迹 S1,A1,S2,A2,...,ST S 1 , A 1 , S 2 , A 2 , . . . , S T ,对于每一个状态 St S t 统计回报值 Gt G t ,
其中 1N(St) 1 N ( S t ) 可以认为是更新的步长
常量步长
很多时候我们采用常量步长 α∈(0,1] α ∈ ( 0 , 1 ] ,
常量步长的意思表示会逐渐遗忘过去的轨迹
由于 (1−α)k+∑ki=1α(1−α)n−i=1 ( 1 − α ) k + ∑ i = 1 k α ( 1 − α ) n − i = 1 ,所以也可以认为常步长是回报值的指数加权,倾向于最近的回报
对比均值步长,常量步长仍然是回报值的加权平均
- 对初始值敏感度更小
- 更简单,不用使用 N(St) N ( S t ) (计数器)
- 适用于不稳定的环境,不稳定的环境更依赖于近况,过去的数据意义不大
- 使回报值不一定收敛(不收敛不一定是一个坏事,对于不稳定环境,如果早早收敛万一环境变了就不适用了,时刻处于学习的状态是好的)
蒙特卡洛优化
广义策略迭代

MC中的广义策略迭代

- V函数需要环境模型,需要P和R,而Q函数不需要,适用于无模型
- MC虽然利用了过去的经验数据,但是默写状态并未遍历到,遍历不够充分置信度不高
ϵ ϵ -贪婪探索
为了保证智能体一直在探索新的策略,最简单的做法是保证所有的m个动作都有一定的概率被采样,用1- ϵ ϵ 的概率选择贪婪动作,用 ϵ ϵ 的概率从m个动作中选择
能同时解决对Q函数的蒙特卡洛策略评价中的探索开始假设
ϵ ϵ -贪婪策略提升
定理:
对于任意 ϵ ϵ -贪婪策略 π π ,使用相应的 qπ q π 得到的 ϵ ϵ -贪婪策略 π′ π ′ 是在 π π 上的一次策略提升,即 vπ′(s)≥vπ(s) v π ′ ( s ) ≥ v π ( s )
证明过程:
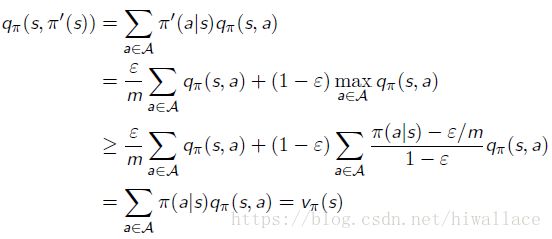
MC的策略迭代

- 策略评价:蒙特卡洛策略评价, Q=qπ Q = q π
- 策略提升: ϵ ϵ -贪婪策略提升
增量式策略评价

每条轨迹:
- 策略评价:蒙特卡洛策略评价, Q≈qπ Q ≈ q π
- 策略提升: ϵ ϵ -贪婪策略提升
无限探索下的极限贪婪(GLIE)
无限探索下的极限贪婪(Greedy in the Limit with Infinite Exploration),意义在于通过对 ϵ ϵ 的衰减,控制无效探索,在极限的情况下将随机策略收敛为确定策略
- 无限探索:所有的状态动作对能够被探索无穷次
limk→∞Nk(s,a)=∞ l i m k → ∞ N k ( s , a ) = ∞ - 极限贪婪:在极限的情况下,策略会收敛到一个贪婪的策略
limk→∞πk(a|s)=1(a=argmaxa′∈AQk(s,a′)) l i m k → ∞ π k ( a | s ) = 1 ( a = a r g m a x a ′ ∈ A Q k ( s , a ′ ) ) - 设置 ϵ ϵ 逐渐衰减到0,比如 ϵk=1/k ϵ k = 1 / k , ϵ ϵ -贪婪策略是GLIE的
定理:
GLIE蒙特卡洛优化能收敛到最优的Q函数
GLIE蒙特卡洛优化

蒙特卡洛算法引申

