图像处理(二十一)基于数据驱动的人脸卡通动画生成-Siggraph Asia 2014
基于数据驱动的人脸卡通动画生成
原文地址:http://blog.csdn.net/hjimce/article/details/47083321
作者:hjimce
在现实生活中,我们经常会去评价一个人,长得是否漂亮、是不是帅哥美女,然而如何用五官的数据去评价一个人是否长得五官比例协调,我们却很难说出来,也就是你为什么觉得某个人长得漂亮?是因为她眼睛大,嘴巴小,还是她五官位置符合江湖传说中的黄金比例呢?我今天要讲的这篇paper的创新点就是回答了这些问题,通过这篇paper的算法,你可以找一堆非常漂亮的美女作为训练数据库,然后用于评价一个输入的照片的五官位置是否长得比例协调,也就是实现一个最简单的长相评分系统,当然这个评分功能不涉及皮肤纹理等,只是用于评价一个人五官位置、大小比例是否协调。
这篇paper还有一个可能的工程应用点,如果你的训练数据足够perfect的话,那么你可以实现这样的一个App功能:智能整容算法。也就是用户输入一张照片,我们可以根据paper的算法,预测五官的正确位置,以这些正确位置为控制顶点,利用图像变形算法,实现五官的自动整容,当然这个最后整容效果的好坏,很依赖于训练数据,正面照片实现估计会比较简单,但是实现各种角度的照片的整容,那就……
不过因为paper的五官位置调整算法,给我的感觉不咋地,所以具体是否经过整容后,真的变得漂亮,实在很难判断……。还有学习这篇paper的意义:通过学习这篇paper,我们可以推测腾讯的天天P图的人脸整形、眼睛放大、嘴巴微笑等算法有可能用了《移动最小二乘的变形》算法实现的,还有天天p图的头发识别,有可能是采用了本文的头发识别方法,也就是借助于模板发型进行头发区域的识别。
OK,回到本篇博文的主题,《基于数据驱动的卡通动画生成》是由腾讯优图团队发表的一篇paper,英文名为:《Data-Driven Face Cartoon Stylization 》,是2014年Siggraph Asia 上的一篇paper,其实现了人像卡通动画的生成:

也就是用户输入一张图片,然后根据算法,它会自动生成用户对应的卡通动画图。看起来是不是高大上的样子,看了paper的效果图是不是感觉很牛逼的样子,然而其实我这篇paper算法的鲁棒性很差,这篇文章能够被Siggraph Asia录用,唯一的亮点是因为它提出来了一个五官位置、比例自动调整算法,利用SVM算法进行五官比例、位置等数据拟合。
这个功能好像曾经在世界杯期间,被应用于“天天p图”的世界杯互动功能中,当然估计是因为鲁棒性问题,所以……。整个过程的算法除了发型识别、单眼皮双眼皮识别、性别识别这三个算法没有去做,其他的都验证了,算法的鲁棒性确实很差,心塞啊,OK,接着我们就讲解一些paper的算法实现。
这篇paper,分为三个步骤:1、创建训练数据,也就是卡通动画的五官库。2、用户输入一张照片,进行最近邻相似搜索。3、五官位置摆放,比例算法等。下面是我根据paper讲解过程进行翻译讲解。
一、卡通动画各个器官库的创建方法

器官库
这一步工作量非常大,如果你要搞这样的一个项目,单单这一步就要就要耗费很多人力物力了,因为艺术家要绘制一个五官库,相当不容易啊,不是一两天可以搞定的事。库的具体创建方法如下:
(1)从网上下载足够多的人脸库
(2)从步骤1中的人脸库挑选300张男性、220张女性的照片,当然这520张照片要具有代表性(每张照片的五官长相,照片表情等尽量不一样),使得数据分布合理。这520张照片用符号P表示。
(3)通过对P的每张照片器官进行分解,构建人脸五官库Fr(Fr是可以重组成完整的一幅P中照片的)。

(4)挑选Fr中,具有代表性的:20个脸型、30个眉毛、30个眼睛、16个鼻子、30个嘴巴、75中类型的头发。注意各个器官男性、女性要分开,即男的20个脸型、女的20个脸型……。
(5)艺术家对(4)中挑选得到的五官图片进行绘制,结果库符号记为Fc。需要注意,艺术家绘制时,眼睛要分为单眼皮和双眼皮进行绘制。
(6)绘制完了以后,我们再手动用这些卡通五官库组合成人脸。组合出P中每张照片的卡通动画图。通过这一步,Fr中的,每个器官都将找到Fc中最为相似的卡通器官图片。(通过这一步创建的P对应的卡通动画图,也将用于后续作为训练数据,后续讲到训练算法的时候,会进行详细讲解)。其实前面的绘制五官卡通图都是小事,这一步人工组合出P中照片的卡通图,才是最不容易的事。
上面Fr、P、Fc的代号需要记清楚,后面直接用代号表示这三部分。
二、算法实现部分
现在假设用户输入一张人脸照片,算法总的过程就是先通过特征点检测出88个人脸特征点,然后对各个器官进行分解,接着:
(1)根据分解的各个器官在Fr库(真实的五官库)中,寻找最相似的器官。然后因为Fr(真实图片的五官库)中的每个图都有对应的Fc(卡通五官图库),据此我们就可以得到用户输入照片五官的对应卡通图Fc。
(2)根据寻找到的最相似的五官卡通图,进行组装。
上面黑色字体部分,就是文献的创新点,也就是回答了如下两个问题:如何寻找最相似的器官(不仅仅用特征点进行查找)?如何进行五官重组(重组起来,使得卡通动画漂亮,五官协调)?接着我将对这两个问题进行详细讲解。
1、五官自动重组算法实现:
这里我根据文献的讲解顺序,先回答第一个问题:如何进行五官重组(使得重组后卡通动画漂亮,五官比例位置协调)?当然这一步的是需要先找到用户输入照片的对应最相似的五官。
A、训练数据获取。
五官重组需要用到机器学习的算法,因此需要训练数据,同时训练数据必须是五官协调的,漂亮的模型。创建方法:根据1中卡通图库创建过程中,我们可以获得人脸库P的每个人脸对应的卡通图库Pc,然后我们请艺术师对Pc的五官位置、比例进行调整,使得Pc中的每张图片都更加漂亮,因为我们将用漂亮的卡通图进行训练。
B、特征提取。
对于每张训练数据卡通图,我们假设图片五官都是对称的,我们创建如下图所示的坐标系:
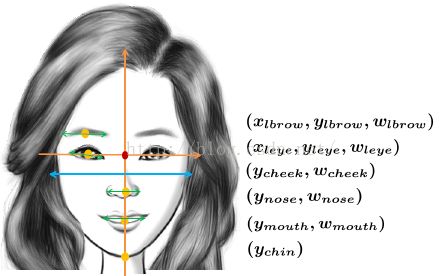
坐标系的原点:两个眼睛位置的中点O;坐标系的Y轴:O点与鼻子的中心的连线的方向。根据创建的坐标系,我们定义一个十三维的特征向量X=(x1,x2,……,x13),其中:
(x1,x2,x3)=(左眉毛位置的x坐标,左眉毛位置的y坐标,眉毛的长度);
(x4,x5,x6)=(左眼睛位置的x坐标,左眼睛位置的y坐标,左眼睛的长度);
(x7,x8)=(鼻子位置的y坐标,鼻子的宽度);
(x9,x10)=(嘴巴位置的y坐标,嘴巴的宽度);
(x11,x12)=(脸颊位置的y坐标,脸颊的宽度);(图中浅蓝色的线)
(x13)=(下巴位置的y坐标);(人脸特征点的最下点)
因此根据P的卡通图,我们可以得到如下训练数据:![]() ,其中X为卡通图的特征,Z为卡通图的风格数据。在paper中,卡通图库包含如下三种形式的风格:
,其中X为卡通图的特征,Z为卡通图的风格数据。在paper中,卡通图库包含如下三种形式的风格:

C、学习自动进行五官比例、位置等调整。
采用ε-SVR算法(参考文献:Libsvm: a library for support vector machines)进行训练学习。我的简单理解就是算法通过SVM算法,进行五官位置比例的预测拟合。因为我们要五官自动重组,使得重组后的模型更美观。因此我们可以通过输入训练数据,得到相关的拟合函数的参数。然后当我们输入一个新的模型后,我们就可以进行拟合预测出新模型。
这一步具体算法的实现参考paper中的:Adjustment of facial compositions。给定大于零的参数C>0、ε>0,ε-SVR归结为求解如下最小优化问题:
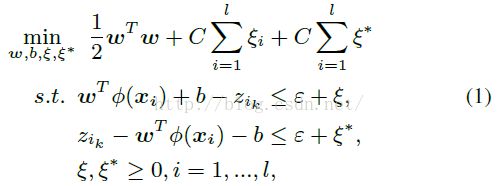
W就是我们需要通过训练数据,得到的参数。Φ(xi)表示映射变换函数。公式(1)的拉格朗日对偶问题为:
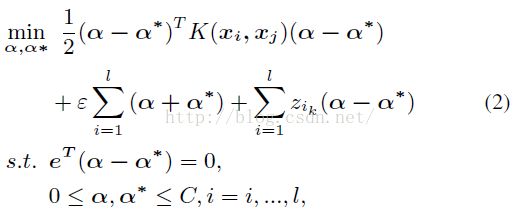
Paper中,径向基函数K选择高斯核函数,即:
![]()
通过求得上面的拉格朗日乘子,ɑ、ɑ*,我们就可以进行预测了,ε-SVR的预测公式如下:
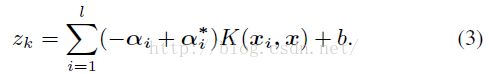
到这里算法的第一部分就翻译结束了。具体的器官自动组合的细节,在paper的倒数第二段还有讲解。通过公式(3),我们可以预测每个器官的合适位置和合适大小比例。
个人总结:上面的公式是不是看起来好深奥的样子,最优化问题,其实如果你已经非常了解SVM算法,上面那些公式根本不用看,也不用自己写代码实习,因为求解SVM,直接用libsvm库就好了,十分钟搞定的事,而文献作者提到了,他也是直接调用了libsvm库的,因此甚至你不需要懂上面的一坨公式,你只需要网上下载libsvm,看看怎么调用,怎么传入参数就可以实现这一步的。为了测试这一步,我先简单随便找了50张明星美女照片,作为训练数据,然后输入一张用户照片,进行五官位置预测。训练数据:

训练数据
因为训练数据比较少,将就一下,并且有的训练数据也不一定是漂亮的,我是看着顺眼的,然后训练数据也就那几个明星的图片。因为我们只是用于初步的测试,看一下SVM算法是否真的能够通过训练数据学习出:美丽特征。看一下效果:
声明:测试图片是网上下载,如有侵权请联系作者删除之。
上面的测试图片中,蓝色的点是原来的人脸特征点,我只显示了一些五官的关键点,如眼睛、眉毛、嘴巴的中心位置,还有下巴的最下点。然后红色的点代表新的五官位置,可以看到,这张图片预测后的新五官的位置是貌似很不错的样子。下巴、嘴巴、鼻子都需要稍微下移进行整容才能比较漂亮一些,当然五官的大小也可以预测,我这边为了方便,所以才没有显示新的五官大小。这个需要用图像变形算法,进行五官位置整容,比较懒,所以就懒得弄变形算法了。在测试一张本来就长得很漂亮的人,如果五官的位置发生比较大的偏移

可以看到对于长得五官比例协调的人脸来说,其五官位置的偏移基本上非常小。
2、寻找最相似的器官。
在开始看这篇paper前,可能我们会想直接用各个器官的识别检测到的特征点,直接进行计算两图片特征点间的欧式距离就可以了,然而通过特征点计算相似度首先要识别足够多的特征点才行。通过这篇paper我们可以学到一些图片相似搜索的简单算法。
具体的算法实现如下:
A、眼睛和鼻子。
文献中使用了HOG描述算子(参考文献:Histograms of oriented gradients for human detection),作为这两个部位的特征。眼睛部位:眼睛部位的图片统一归一化到62*100大小的图片,然后进行计算HOG特征。这样就可以计算两找眼睛图片的特征向量间的欧式距离。鼻子部位:统一归一化到71*200大小的图片。HOG算子直接调用Opencv库就好了,所以这一步也不需要我们自己去写代码。
B、眉毛部位。
首先眉毛统一归一化到66*200大小的图片;因为眉毛和皮肤可以说是混合在一起的,所以paper接着用高斯模糊对其进行预处理;然后把66*200的图像划分成6*20个块,最后统计每个块的颜色信息总和xi;最后以(x1,x2……x120)作为特征向量,计算特征向量间的欧式距离,这个思想是图像相似搜索给我最简单的方法了,在好几篇paper中遇到这个算法,然而效果当然不咋地,因为图片搜索领域,现在即便是百度识图,给我的感觉效果也一般般。
C、脸庞和嘴巴。
这两个部位是直接用人脸识别到的特征点作为特征向量,进行计算相似度的。需要注意的一个小细节:在计算脸庞相似度时,由于图片大小、旋转角度不一样,因此一开始我的思路是用相似变换的方法,求解相似变换矩阵,然后在对根据相似变换结果计算欧式距离;然而文献中不是用这种方法,它是以固定脸庞的其中两个顶点,计算变换矩阵,最后进行变换。这种小细节不知道是不是效果比较好,不然一般人的思路,应该是用相似变换的方法。我验证之后,感觉效果还不如直接进行放射变换,这一步也可以直接用opencv库的函数就好了。
D、发型识别。

发型识别
我们知道,前面我们创建的卡通动画的发型,包含75种发型。对于发型的相似度计算,paper也是以HOG算子作为特征,计算欧式距离。具体它分为两个步骤:局部匹配、全局匹配。发型识别的细节比较多,这里只讲大体的流程。
第一步过程,得到K近邻发型。这一步跟上面眉毛部位的计算方法类似:首先就是对卡通图和真实图进行阈值分割,得到二值化图像,并进行图像大小归一化,具体归一化的图片大小文章没有具体详细说明;最后对归一化图像进行分块,统计每个块的颜色信息总和xi,并以(x1,x2……xn)作为特征向量,计算特征向量间的欧式距离。这样我们可以得到k近邻发型,![]() 。
。
第二步过程,这一步就是要从k近邻中,寻找最接近的发型了。这一步的计算方法与眼睛的计算方法类似,也是通过计算HOG特征,作为特征向量,并计算欧式距离。这样我们就可以从这K个近邻中找到最相似的发型了。
E、性别识别。
文献参考《Evaluation of gender classification methods with automatically detected and aligned faces》的方法,总的过程,是通过SVM训练一个分类器,然后进行男女性别的分类判别。
F、眼镜检测。
对于是否戴眼镜,paper首先在眼镜的中间位置取一块区域,然后对把这一块区域转换成灰度图像,最后计算垂直方向上的梯度值。
根据梯度值,得到上下梯度值最大的像素集A、B(图中红色的像素点),然后统计A、B的方差:
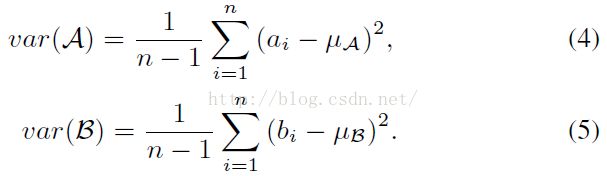
最后根据sum of var(A)、var(B)的大小,进行阈值判断其是否戴眼镜。根据文献的最后几句话:The glass color is obtained from the region between two set of pixels。好像也可以通过A、B的颜色信息,进行判断眼镜边框的颜色

判断是否戴眼镜
G、双眼皮检测。
判断一个眼镜是否有双眼皮,这篇paper给出了貌似很简单的算法,可惜这一步我看不懂。paper只是说了,根据边缘检测算子Candy算子得到梯度图像,然后根据判断眼镜的上半部分,是否有两个pulsers(if two pulses are detected on the left-top part of its gradient image),判断是否双眼皮。
到了这里可以说从卡通五官库中,挑选最相似的卡通器官算法已经结束了,接着需要补充后续的细节。补充细节:
1、五官组合。这一步前面已经讲了大体的算法过程,通过支持向量机预测拟合算法,可以预测出每个器官的大小及其位置,然后文献直接用ɑ融合进行图片合成。
2、图像变形。对于某些器官,我们很难在库里找到相似的模型,文章发现,脸型和眼睛部位是否相似,非常重要,因此文献只对眼睛和脸庞进行变形,变形算法采用移动最小二乘的方法。这一步的相关细节也很多,写到这里已经没有力气了,就这样吧,写了这么多好累。
总结与心得:
1、识别方面。这篇paper给出了很多算法,比如眼镜判别、双眼皮判别、各个五官相似度判别、发型识别,对于我这种菜鸟感觉看起来相当爽、学到了好多。虽然有的算法,估计效果不好,但是至少让我看到除了用深度学习的方法,我们还是有其它的路可以走的。如果不用深度学习,这些方法值得一试,当然算法效果精度,很差,鲁棒性也很差。
2、如何通过机器学习的方法判断一个人的五官大小、位置是否协调?是这篇paper的主要思想,其实通过SVM算法,进行预测拟合的。这个思路是很新颖,只能说是一个很不错的想法,然而要进行工程应用,要对一个用户输入照片进行自动五官整容,还很难达到商用的地步。
最后还要说一下,别看paper的那几张图效果那么好,那是因为paper估计是测试图片就是库里面已有的图片,所以相似性搜索看起来才会那么牛逼。
参考文献:
1、《Data-Driven Face Cartoon Stylization 》
**********************作者:hjimce 时间:2015.8.1 联系QQ:1393852684 地址:http://blog.csdn.net/hjimce 转载请保留本行信息********************