库存系统难破题?且看京东到家如何破
京东到家库存系统架构设计
目前,京东到家库存系统经历两年多的线上考验与技术迭代,现服务着万级商家十万级店铺的规模,需求的变更与技术演进,我们是如何做到系统的稳定性与高可用呢,下面将会给你揭晓答案
库存系统技术架构图

上图如果进行总结下,主要体现出以下几个方面
- 完善的基础设施
强大的基础服务平台让应用、JVM、Docker、物理机所有健康指标一目了然,7*24小时智能监控告警让开发无须一直盯着监控; - 数据驱动
数据与业务相辅相成,用数据验证业务需求,迭代业务需求,让业务需求都尽可能的收益最大化,库存系统的开发同学只需要关注业务需求; - 健全的测试团队
大版本上线前相应的测试同学会跟进帮你压测,防止上线后潜在的性能瓶颈。
库存系统技术架构图解释说明
Portal
通过提供商家PC端、App端解决大部分中小商家的日常运营需求,另外提供开放平台满足大中型商家系统对接与数据共享互通的问题。
Service
这个板块涵盖了整个库存最核心的C&B数据业务。
1.业务类
- C正常流程:用户下单-商家拣货-快递员妥投
- C异常流程-缺货:用户下单-商家缺货-用户协商-调整订单缺货商品-商家拣货-快递员妥投
- C异常流程-取消:用户下单-用户反悔-订单取消
- C异常流程-风控:用户下单-风控拦截-订单锁定-客服审核-订单取消/继续生产
- B正常流程:商家维护可售库存数量,即时或者定时生效
2.数据类
除了业务类需求外,京东到家还提供了大量有商业价值的数据供商家作业务决策,比如
- 商品销量Top榜-支持分城市分类目筛选
- 热销商品库存不足预警-商家App版本Push通知及待办事项中可以醒目识别这部分商品并进行维护
- 红黄线自动下架-近七日订单量大于5单,并且被踩率大于等于20%的商品,进行下架操作,每日执行。
- 库存交易流水
3.中间件类
古人行军打仗,兵马未动,粮草先行,对于系统来说亦是如此,编码未动架构先行,架构的技术选型非常重要,在这里给大家分享京东技术体系上万码农都在使用的几个中间件。
- JSF,类似于DUBBO,是一款非常优秀的RPC层框架,可以解决应用间的数据通信问题,它最主要的优势是长连接的实现以及高效的序列化组件。
- JMQ,JMQ是京东自主研发的一款消息中间件系统,具有高可用、数据高可靠等特性。广泛应用于公司内部系统,包括订单、支付、库房、交易等场景。在库存系统中会优先更新Redis缓存数据,并发送变更MQ,供MySQL及ES异步更新。
- O2OWORKER,早期淘宝开源的一款产品TBSCHEDULE,不这个只适用于单项目管理,多个系统使用的话权限无法隔离,另外参数配置过于繁琐,结合这两点进行了重构,从而形成了现在的整个京东到家都在使用的任务管理平台。
DB
1.MYSQL
京东到家库存系统使用的关系型数据库是MYSQL,低成本、低耦合、轻量级,总之优势多多。
2.REDIS
丰富的数据结构&众多的原子性命令支持,非常适合库存系统进行缓存查询及扣减操作。
3.ES
库存系统的数据量非常大,首先MYSQL数据库通过水平扩容来解决单表数据量过大的问题,水平扩容的规则采取的是按门店维度进行分表(1.目前京东到家还没有到分库的阶段,2.按门店维度进行分表数据量会相对均衡一些,所以没有按照商家维度进行划分)。那么在商家PC端上查询所有商品库存及维护库存时带来了难度,比如查询该商家下所有的商品有多少条,同时处于上架状态的商品有哪些……,为了解决这一难题,引入了ES,将数据统一存储在ES集群中,解决一些涉及到聚合查询的场景。
库存系统数据流转图
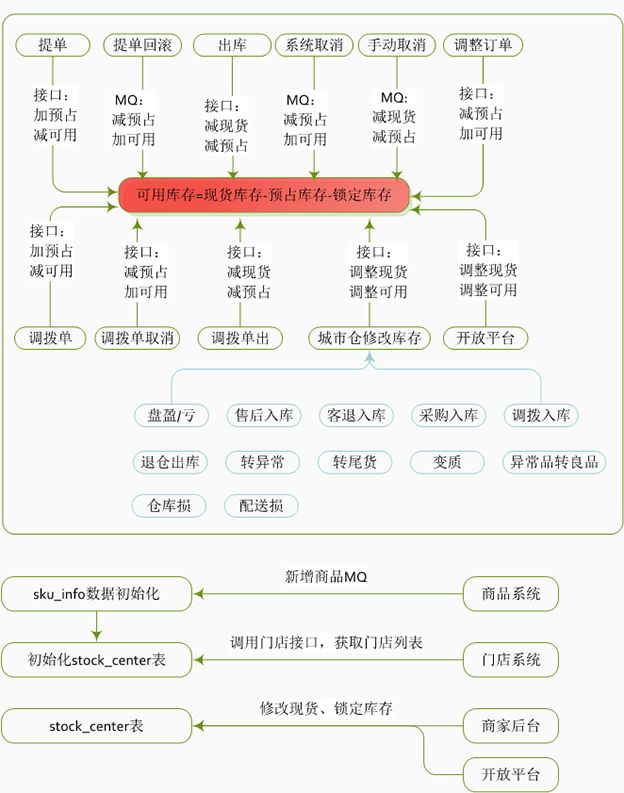
库存系统数据流转图解释说明:
- 库存系统的数据流转,指的都是销售库存的数据流转,在京东到家还有自营类业务板块,即上图中提到的城市仓,由于它涉及到采购入库及盘盈盘亏等问题所以会由一套WMS系统来支撑。
- 京东到家设计初衷就是希望商家下的商品各门店共享,带来的问题就是商家新建一个商品时,需要推送到商家下所有的门店中,即所有的门店均可以看到这个商品, 或者商家新建一个门店时,需要将商家下所有的商品均推送到这个新建的门店中,所以这采用了MQ技术进行异步化批量处理。
写到这里,相信对大家对库存系统有了初步的了解,从上图来看功能上其实并不复杂,但是他面临的技术复杂度却是相当高的,比如秒杀品在高并发的情况下如何防止超卖,另外库存系统还不是一个纯技术的系统,需要结合用户的行为特点来考虑,比如下文中提到什么时间进行库存的扣减最合适,我们先抛出几个问题和大家一起探讨下,如有有妥不处,欢迎大家拍砖。
库存什么时候进行预占(或者扣减)呢
商家销售的商品数量是有限的,用户下单后商品会被扣减,我们可以怎么实现呢?
举个例子:
一件商品有1000个库存,现在有1000个用户,每个用户计划同时购买1000个。
- (实现方案1)如果用户加入购物车时进行库存预占,那么将只能有1个用户将1000个商品加入购物车。
- (实现方案2)如果用户提交订单时进行库存预占,那么将也只能有1个用户将1000个商品提单成功,其它的人均提示“库存不足,提单失败”。
- (实现方案3)如果用户提交订单&支付成功时进行库存预占,那么这1000个人都能生成订单,但是只有1个人可以支付成功,其它的订单均会被自动取消。
京东到家目前采用的是方案2,理由:
- 用户可能只是暂时加入购物车,并不表示用户最终会提单并支付。
- 所以在购物车进行库存校验并预占,会造成其它真正想买的用户不能加入购物车的情况,但是之前加车的用户一直不付款,最终损失的是公司。
- 方案3会造成生成1000个订单,无论是在支付前校验库存还是在支付成功后再检验库存,都会造成用户准备好支付条件后却会出现99.9%的系统取消订单的概率,也就是说会给99.9%的用户体验到不爽的感觉。
- 数据表明用户提交订单不支付的占比是非常小的(相对于加入购物车不购买的行为),目前京东到家给用户预留的最长支付时间是30分钟,超过30分钟订单自动取消,预占的库存自动释放
综上所述,方案2也可能由于用户下单预占库存但最终未支付,造成库存30分钟后才能被其它用户使用的情况,但是相较于方案1,方案3无疑是折中的最好方案。
重复提交订单的问题?
重复提交订单造成的库存重复扣减的后果是比较严重的。比如商家设置有1000件商品,而实际情况可能卖了900件就提示用户无货了,给商家造成无形的损失
可能出现重复提交订单的情况:
- (1、用户善意行为)app上用户单击“提交订单”按钮后由于后端接口没有返回,用户以为没有操作成功会再次单击“提交订单”按钮
- (2、用户恶意行为)黑客直接刷提单接口,绕过App端防重提交功能
- (3、提单系统重试)比如提单系统为了提高系统的可用性,在第一次调用库存系统扣减接口超时后会重试再次提交扣减请求
好了,既然问题根源缕清楚了,我们一一对症下药
- (1、用户善意行为)app侧在用户第一次单击“提交订单”按钮后对按钮进行置灰,禁止再次提交订单
- (2、用户恶意行为)采用令牌机制,用户每次进入结算页,提单系统会颁发一个令牌ID(全局唯一),当用户点击“提交订单”按钮时发起的网络请求中会带上这个令牌ID,这个时候提单系统会优先进行令牌ID验证,令牌ID存在&令牌ID访问次数=1的话才会放行处理后续逻辑,否则直接返回
- (3、提单系统重试)这种情况则需要后端系统(比如库存系统)来保证接口的幂等性,每次调用库存系统时均带上订单号,库存系统会基于订单号增加一个分布式事务锁,伪代码如下:
int ret=redis.incr(orderId);
redis.expire(orderId,5,TimeUnit.MINUTES);
if(ret==1){
//添加成功,说明之前没有处理过这个订单号或者5分钟之前处理过了
boolean alreadySuccess=alreadySuccessDoOrder(orderProductRequest);
if(!alreadySuccess){
doOrder(orderProductRequest);
}else{
return "操作失败,原因:重复提交";
}
}else{
return "操作失败,原因:重复提交";
}库存数据的回滚机制如何做
需要库存回滚的场景也是比较多的,比如:
- (1、用户未支付)用户下单后后悔了
- (2、用户支付后取消)用户下单&支付后后悔了
- (3、风控取消)风控识别到异常行为,强制取消订单
- (4、耦合系统故障)比如提交订单时提单系统T1同时会调用积分扣减系统X1、库存扣减系统X2、优惠券系统X3,假如X1,X2成功后,调用X3失败,需要回滚用户积分与商家库存。
其中场景1,2,3比较类似,都会造成订单取消,订单中心取消后会发送mq出来,各个系统保证自己能够正确消费订单取消MQ即可。而场景4订单其实尚未生成,相对来说要复杂些,如上面提到的,提单系统T1需要主动发起库存系统X2、优惠券系统X3的回滚请求(入参必须带上订单号),X2、X3回滚接口需要支持幂等性。
其实针对场景4,还存在一种极端情况,如果提单系统T1准备回滚时自身也宕机了,那么库存系统X2、优惠券系统X3就必须依靠自己为完成回滚操作了,也就是说具备自我数据健康检查的能力,具体来说怎么实现呢?
可以利用当前订单号所属的订单尚未生成的特点,可以通过worker机制,每次捞取40分钟(这里的40一定要大于容忍用户的支付时间)前的订单,调用订单中心查询订单的状态,确保不是已取消的,否则进行自我数据的回滚。
多人同时购买1件商品,如何安全地库存扣减
现实中同一件商品可能会出现多人同时购买的情况,我们可以如何做到并发安全呢?
伪代码片段1:
synchronized(this){
long stockNum = getProductStockNum(productId);
if(stockNum>requestBuyNum) {
String sql=" update stock_main "+
" set stockNum=stockNum-"+requestBuyNum +
" where productId="+productId;
int ret=updateSQL(sql);
if(ret==1){
return "扣减成功";
}else {
return "扣减失败";
}
}
} 伪代码片段1的设计思想是所有的请求过来之后首先加锁,强制其串行化处理,可见其效率一定不高,
伪代码片段2:
String sql=" update stock_main "+
" set stockNum=stockNum-"+requestBuyNum +
" where productId="+productId+
" and stockNum>="+requestBuyNum;
int ret=updateSQL(sql);
if(ret==1){
return "扣减成功";
}else {
return "扣减失败";
}这段代码只是在where条件里增加了and stockNum>=”+requestBuyNum即可防止超卖的行为,达到了与上述伪代码1的功能
如果商品是促销品(比如参与了秒杀的商品)并发扣减的机率会更高,那么数据库的压力会更高,这个时候还可以怎么做呢
海量的用户秒杀请求,本质上是一个排序,先到先得.但是如此之多的请求,注定了有些人是抢不到的,可以在进入上述伪代码Dao层之前增加一个计数器进行控制,比如有50%的流量将直接告诉其抢购失败,伪代码如下:
public class SeckillServiceImpl{
private long count=0;
public BuyResult buy(User user,int productId,int productNum){
count++;
if(count%2=1){
Thread.sleep(1000);
return new BuyResult("抢购失败");
}else{
return doBuy(user,productId,productNum);
}
}
}另外同一个用户,不允许多次抢购同一件商品,我们又该如何做呢
public String doBuy(user,productId,productNum){
//用户除了第一次进入值为1,其它时候均大于1
int tmp=redis.incr(user.getUid()+productId);
if(tmp==1){
//1小时后key自动销毁
redis.expire(user.getUid()+productId,3600);
return doBuy1(user,productId,productNum);
}else{
return new BuyResult("抢购失败");
}
}如果同一个用户拥有不同的帐号,来抢购同一件商品,上面的策略就失效了
一些公司在发展早期几乎是没有限制的,很容易就可以注册很多个账号。也即是网络所谓的“僵尸账号”,数量庞大,如果我们使用几万个“僵尸号”去混进去抢购,这样就可以大大提升我们中奖的概率,那我们如何应对呢
public String doBuy1(user,productId,productNum){
String minuteKey=DateTimeUtil.getDateTimeStr("yyyyMMddHHmm");
String minuteIpCount=redis.incr(minuteKey+user.getClientIp());
// threshold为允许每分钟允许单个ip的最大访问次数
if(minuteIpCount>threshold){
//识别到这部分潜在风险用户时,会让这部分用户强制跳转到验证码页面进行校验
//校验通过后才能继续抢购商品
return getAndSendVerificationCode(user);
}else{
return doBuy2(user,productId,productNum);
}
}库存系统的核心表结构设计
下面列出了库存系统的核心表结构,提供出来供大家在工作中能够有所参考
库存主表,命名规则:stock_center_00~99

库存流水表,命名规则:stock_center_flow_00~99

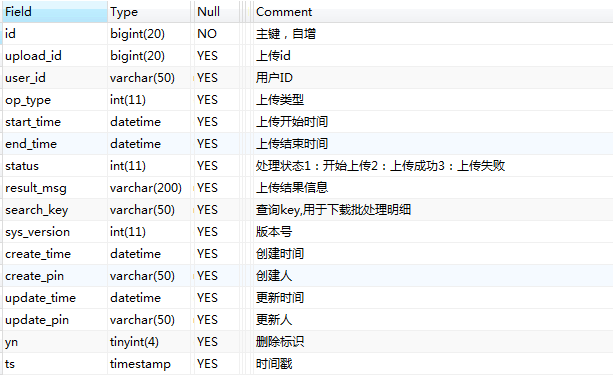
库存批量操作日志表,命名规则:batch_upload_log
作者介绍
柳志崇,2008 年计算机专业毕业,一直从事于移动互联网及 O2O 新零售业务领域的工作,参与过京东到家多个亿级 PV 系统的研发与架构,对高并发有着丰富的实战经验。
如下是聊聊架构社群分享的内容。如果你也有好内容,欢迎你也来社群分享。
Q&A
Q:
亿级 PV 系统的架构能否介绍下,怎么做到高并发的?
A:
高并发这个词业内外使用得很泛滥,因为并没有一个统一的定义,比如 qps、tps 达到多少就是高并发了。
一个系统设计的早期更多地关注功能迭代,随着平台的发展,用户、商家、商品数据的持续增长,直到有一天有人告诉你,说你的系统太慢了,或者程序处理上的数据不对时,表明你是时候该重视高并发了。
接下来我谈谈关于库存系统这块高并发的思路,供参考。
服务接口的无状态化设计,方便随时随地可以水平扩容
服务接口的幂等性设计,防止重复提交造成的重复扣减
服务接口的限流与截流设计,应对异常流量造成整个系统瘫痪
针对读多写少的场景进行数据缓存,缓存时还应该注意缓存击穿的问题
库存数据持续增多时势必会考虑数据库分库分表,分库分表路由规则设计:1、一定要紧贴业务,否则在一些聚合查询上非常麻烦;2、避免短期内出现二次扩容的可能性
关于库存分库或分表使用什么策略,京东到家接入的商家多半是优质商家,通常一个商家会有多个门店,目前库存系统采用的门店维度进行分表:
1、目前的体量还没有进行分库;
2、分表路由算法是门店编号取模 + 大门店定向路由组合,来避免简单的取模算法造成表数据分布可能出现的严重不平衡问题
Q:
为什么京东到家的库存和京东商城的库存要单独的呢?
A:
京东商城与京东到家是两款 App,两款有着各自独立的消费场景与目标人群,系统设计上是有些差异化的,如果我们从架构的角度来说,他们之间是解耦的,带来显而易见的好处就是其中一个挂了不会影响到另外一个。
京东到家比京东商城起步晚了整整 12 年,所以设计之初是借鉴了京东商城的库存系统的,但是京东到家中涵盖的服务类商品 (比如上门美甲按摩库存是具体的人,而一个人是不能同时被预约提供服务的)、外卖类商品 (库存相对更加简单,通常只有货品充足、货品紧张、无货几种状态) 是京东商城中没有的。
另外京东到家处于一个产品高速迭代期,可能一周就一个版本,由于与京东商城相互独立,有问题了影响也可以控制到很小。
Q:
1、定时 40 分捞取,万一 39 分那时候服务重启了,错过这个定时任务捞取,怎么办?
2、同一局域网中,如果对外 IP 都是同一个,受到限制那怎么办?
3、取模限制一部分流量抢购失败,万一流量在促销库存量之内,那是不是最多只能卖出一半?从取模看,也就是 userID 被模为 1 的用户,总是抢不到了?
A:
1、这个问题很好,问得很仔细,这一块就考验定时任务的调度机制了,首先调度策略是每分钟执行,检测前 40 分钟到前 50 分钟之间订单
2、看 doBuy1 方法,这里其实提到了,当同一个公网 IP 访问请求量超过了预设阈值,就会增加一个验证码环节
3、京东到家 App 目前 DAU 过百万了,取模机制造成的只能卖出一半这个问题还没有遇到过,不过有这个担心是好的,实际开发过程中可以设这个取模的值为动态放行流量即可;另外你提到的 userId 被模 1,这个问题是不存在的,因为我不是用 userId 来取模的,请重新读 buy 方法。
Q:
请问一下在高峰期每秒以下这个表会有多少的 tps?“库存主表,命名规则:stock_center_00~99”
A:
首先这个表是异步更新的,不会阻塞主流程,目前观察 tps 可以达到 800
Q:
如果是异步的话,就会有可能出现查库存和实际库存有差异。你是先把库存都放 redis 然后再用 mq 扣减吗?或者还是有其它解决方案?
A:
对外提供的 curd 都是基于 redis 的,所以不会出现不一致的问题,mysql 异步更新只是为了数据的持久化。
Q:
异地多活,用户维度单元化下库存是怎么处理的?
A:
异地多活,目前我们做到了服务的扩机房部署,数据的扩机房准实时备份,还没有进行用户维度的单元化。我也没有实战过,不过我觉得异地多活,架构设计有几点需要关注:
1、避免冷备,即如果一个机房不出意外,另外一个机房永远就是一个 backup,对于大型互联网公司这个成本是非常高的;
2、机房同源策略,一个网络请求可能涉及到几个几十个系统的协同,应当将这部分处理控制到同一个机房处理;
3、就近访问策略,通过智能 DNS,路由到离用户最近的机房机房。