Policy Gradient 和 Value based 方法的区别
[Value Based 方法]
(1) Value based的方法的背景知识
对于MDP, S,A,P,R,r来说,首先是定义了value function, V(s)和Q(s,a),
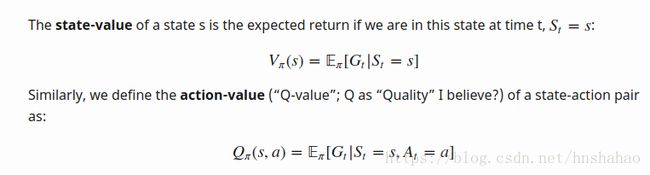
在有了value function的定义以后,就可以得到
Optimal value
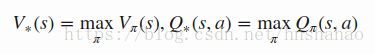
Optimal policy
![]()
然后又引出了Bellman Equation,Bellman Equation 又可以推导出Bellman Expectation Equation 和 Bellman Optimal Equation. 一共是3组公式.
Value based的方法主要是求 V(s) 和 Q(s,a)。计算的是各个state或者action的值。在求得这些值以后,在计算策略的时候,使用的 a = argmax Q(s,a),即对于当前状态s, 遍历其所有的Q(s,a)获得当前状态下应该采用的a值。
实际上这里的V(s)和Q(s,a)都是附加在特定的策略Pi(s)上的,不同的策略有不同的价值函数
(2) Value based的方法
1:Dynamic Programming - 以及GPI (Generalized Policy Iteration)
如果当前环境的模型是已知的,即P(s',r|s,a)和r都已知,那么可以用解方程或者动态规划的方法求出结果。
动态规划这里采取的是一种迭代的形式来解,迭代的时候采用的是一个叫做Generalized Policy Iteration的方法,
In GPI, the value function is approximated repeatedly to be closer to the true value of the current policy and in the meantime, the policy is improved repeatedly to approach optimality. This policy iteration process works and always converges to the optimality, but why this is the case?

这里的核心是 Pi(s)的生成,是对值函数取argmax,对于value based的方法,都是采用这样的策略来求得action.
2: Monte-Carlo Methods
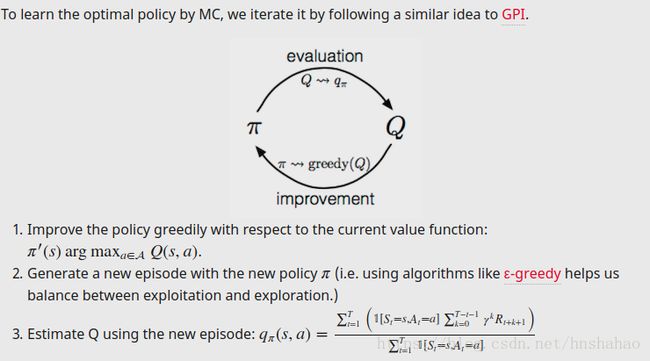
就是做多个rollout来算平均,核心的点也是action = argmax....
3: Temporal - Difference Learning
包括SARSA和Q learning, DQN
Important Notice
1): 在实际实现的时候,对于Value based的方法,在算loss的时候,比如DQN 实际上是一个回归的loss, 比如Smoth L1 loss
loss = F.smooth_l1_loss(state_action_values,expected_state_action_values.unsqueeze(1))2): Value based 方法只适合离散的action情况,因为要取argmax_a Q(s,a)
3): Value based 方法只适合 deterministic policy的情况,policy based 方法适合 stochastic policy 也适合于deterministic policy. 另外对于value based 的方法,针对action增加 exploration 的效果是采用的 e greedy 方法来做, 如下面这段代码。而policy based 方法,本身就带有随机探索的功能。
if sample > eps_threshold:
with torch.no_grad():
return policy_net(state).max(1)[1].view(1, 1)
else:
return torch.tensor([[random.randrange(2)]], device=device, dtype=torch.long)Deterministic Policy: PI(s) = a
Stochastic Policy: PI(a|s) = P_pi[A=a|S=s]
这里还需要对于policy gradient方法来做deterministic policy的情况进行了解,主要是,参考文献3问答的一个参考链接中的论文
[Policy Based 方法]

Policy based 方法是直接 maximize the expected return
policy-based methods find the optimal policy by directly optimizing for the long term reward. How you choose to optimize the policy parameters then becomes the different branches within policy based methods
policy gradient methods try to learn a policy function directly (instead of a Q function), and are typically on-policy, meaning you need to learn from trajectories generated by the current policy. One way to learn an approximation policy is by directly maximizing expected reward using gradient methods, hence "policy gradient" (the gradient of the expected reward w.r.t. the parameters of the policy can be obtained via the policy gradient theorem[1] for stochastic policies, or the deterministic policy gradient theorem[2] for deterministic policies
[比较总结]
在sutton的书里面,总结的是
(1) So far in this book almost all the methods have learned the values of actions and then selected actions based on their estimated action values; their policies would not even exist without the action-value estimates. In this chapter we consider methods that instead learn a parameterized policy that can select actions without consulting a value function. A value function may still be used to learn the policy parameter, but is not required for action selection.
(2) 下面提到了一个Maximize performace, 所以policy gradient也是有一个目标函数

(3)Methods that learn approximations to both policy and value functions are often called actor–critic methods, where ‘actor’
is a reference to the learned policy, and ‘critic’ refers to the learned value function, usually a state-value function.
(4) 来自网上一个比较
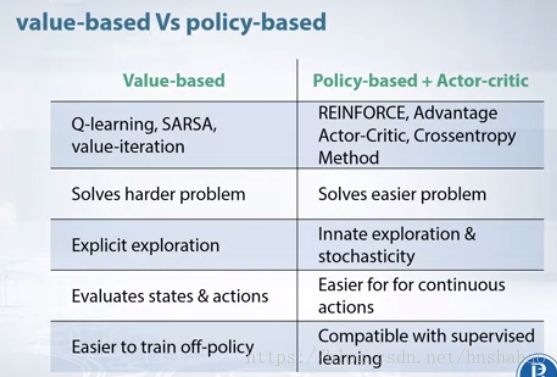
参考文献:
(1) Sutton 的书
(2) https://lilianweng.github.io/lil-log/2018/02/19/a-long-peek-into-reinforcement-learning.html#value-function
(3) https://www.quora.com/What-is-difference-between-DQN-and-Policy-Gradient-methods#KoFXD