基于时序差分的无模型强化学习:Q-learning 算法详解
目录
- 一、无模型强化学习中的时序差分方法与Q-learning
-
- 1.1 时序差分法
- 1.2 Q-learning算法
-
-
- 状态-动作值函数(Q函数)
- Q-learning 的更新公式
- Q-learning 算法流程
- Q-learning 的特点
-
- 1.3 总结
一、无模型强化学习中的时序差分方法与Q-learning
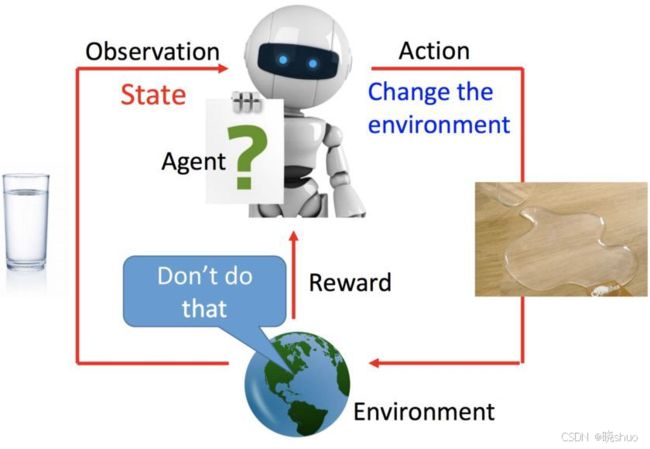
动态规划算法依赖于已知的马尔可夫决策过程(MDP),在环境的状态转移概率和奖励函数完全明确的情况下,智能体无需与环境进行实际交互,即可通过解析方法计算出最优策略或价值函数。然而,现实中的大多数强化学习问题通常无法明确环境的状态转移模型或奖励函数,这使得动态规划在许多复杂场景下难以应用。为了应对这一局限,无模型强化学习(model-free reinforcement learning)应运而生,智能体通过与环境的交互采样数据,并依据采样结果进行学习,从而实现策略优化。无模型强化学习不依赖于对环境的精确建模,这使其在复杂的物理环境或电子游戏等应用场景中具有更广泛的适用性。
在无模型强化学习中,基于时序差分(temporal difference, TD)的方法得到了广泛的应用,代表性算法包括 Sarsa 和 Q-learning。它们通过在实际交互过程中逐步更新策略与价值函数,具备在线和离线策略学习的能力。在线策略学习依赖于当前策略的样本更新,而离线策略学习则通过经验回放池反复利用历史样本,减少采样的复杂度并提高学习效率。Q-learning 是其中最具代表性的算法之一,其核心思想是通过最大化状态-动作值函数(Q函数),逐步逼近最优策略,即使在策略不断变化的情况下,仍能有效地收敛至最优策略。
1.1 时序差分法
时序差分方法是一种用于估计策略价值函数的有效技术,它结合了蒙特卡洛(Monte Carlo)方法和动态规划(Dynamic Programming)思想的优势。时序差分方法与蒙特卡洛方法的相似之处在于,它能够从与环境的交互数据中学习,而不需要事先知道环境的状态转移模型。与动态规划方法的相似之处则在于,它通过贝尔曼方程的思想,利用后续状态的价值估计来更新当前状态的价值估计。
蒙特卡洛方法对价值函数的增量更新可以表示为:
V ( S t ) ⟵ V ( S t ) + α ( G t − V ( S t ) ) V(S_{t})\longleftarrow V(S_{t})+\alpha (G_{t}-V(S_{t})) V(St)⟵V(St)+α(Gt−V(St))
其中, G t G_{t} Gt是在时间步 t t t时的实际回报, α \alpha α是步长(或学习率)。在蒙特卡洛方法中,更新只能在整个序列结束之后进行,因为 G t G_{t} Gt只有在序列终止时才能计算。
然而,时序差分方法不需要等到整个序列结束,而是可以在每个时间步后立即更新。时序差分算法根据当前状态 S t S_{t} St和下一状态 S t + 1 S_{t+1} St+1的价值估计来更新当前状态的价值估计,其增量更新公式为:
V ( S t ) ⟵ V ( S t ) + α ( R t + 1 + γ V ( S t + 1 ) − V ( S t ) ) V(S_{t})\longleftarrow V(S_{t})+\alpha (R_{t+1}+\gamma V(S_{t+1})-V(S_{t})) V(St)⟵V(St)+α(Rt+1+γV(St+1)−V(St))
其中, R t + 1 R_{t+1} Rt+1是在时间步 t + 1 t+1 t+1时获得的即时奖励, γ \gamma γ是折扣因子,且 V ( S t + 1 ) V(S_{t+1}) V(St+1)是下一状态 S t + 1 S_{t+1} St+1的价值估计。公式中的
δ t = R t + 1 + γ V ( S t + 1 ) − V ( S t ) \delta_{t} = R_{t+1}+\gamma V(S_{t+1})-V(S_{t}) δt=Rt+1+γV(St+1)−V(St)
被称为时序差分误差(temporal difference error, TD error),它反映了当前价值估计与通过后续状态推断的修正之间的差异。时序差分算法将这一误差乘以步长 α \alpha α后, 作为更新当前状态价值的增量。
可以用下一状态的价值估计 V ( S t + 1 ) V(S_{t+1}) V(St+1)) 来代替真实的回报 G t G_{t} Gt,这一点与蒙特卡洛方法的区别在于:蒙特卡洛方法需要使用整个序列的回报来更新价值,而时序差分方法则利用近似的未来价值估计来更新。
因此,时序差分方法在每一步与环境的交互中,即可通过上述公式进行状态价值估计的更新。尽管时序差分方法依赖于当前状态的估计值,但在适当的条件下可以证明其收敛性,即它能够收敛到当前策略下的真实价值函数,尽管具体的证明在此不作展开。
1.2 Q-learning算法
Q-learning 是一种无模型(model-free)的强化学习算法,旨在通过学习状态-动作值函数(Q函数),找到在给定环境中执行任务的最优策略。它的核心思想是通过直接迭代近似贝尔曼最优方程,从而逐步学习最优的动作选择策略。Q-learning 属于离线策略(off-policy)方法,这意味着在学习的过程中,它所使用的更新策略可以与实际执行过程中所采用的行为策略不同。Q-learning 不需要对环境的状态转移概率或奖励函数有任何先验知识,它仅仅通过与环境交互、采样到的经验进行学习。这个特性使得 Q-learning 适用于复杂环境中的学习任务,如游戏中的智能体控制或机器人导航等场景。
状态-动作值函数(Q函数)
在 Q-learning 中,目标是学习一个状态-动作值函数 Q ( s , a ) Q(s,a) Q(s,a),它表示在状态 s s s下选择动作 a a a后所能获得的预期累积奖励。该累计奖励考虑了未来的所有可能回报,折扣因子 γ \gamma γ用来平衡即时奖励和未来奖励:
Q ( s , a ) = E [ R t + γ R t + 1 + γ 2 R t + 2 + . . . ] Q(s,a)= \mathbb{E}[R_{t}+\gamma R_{t+1}+\gamma^{2}R_{t+2}+...] Q(s,a)=E[Rt+γRt+1+γ2Rt+2+...]
通过学习 Q ( s , a ) Q(s,a) Q(s,a),智能体能够确定每个状态下的最优动作,并以此找到最优策略。
Q-learning 的更新公式
Q-learning 的更新基于贝尔曼最优方程,该方程指出,对于任意状态 s s s和动作 a a a,该状态-动作值应当等于在当前状态执行该动作后所得到的即时奖励,加上进入下一状态后所能获得的最大未来奖励的折扣值。其更新公式为:
Q ( s t , a t ) ⟵ Q ( s t , a t ) + α ( R t + 1 + γ m a x a ′ Q ( s t + 1 , a ′ ) − Q ( s t , a t ) ) Q(s_{t},a_{t})\longleftarrow Q(s_{t},a_{t})+\alpha (R_{t+1}+\gamma \underset{a^{'}}{max} Q(s_{t+1},a^{'})-Q(s_{t},a_{t})) Q(st,at)⟵Q(st,at)+α(Rt+1+γa′maxQ(st+1,a′)−Q(st,at))
在该公式中:
- Q ( s t , a t ) Q(s_{t},a_{t}) Q(st,at)表示当前状态 s t s_{t} st和动作 a t a_{t} at的 Q Q Q值。
- R t + 1 R_{t+1} Rt+1是智能体在执行动作 a t a_{t} at后得到的即时奖励。
- γ \gamma γ是折扣因子,范围在[0,1]之间,表示对未来奖励的重视程度。
- α \alpha α是学习率,控制更新的步幅大小,范围在[0,1]之间。
- m a x a ′ Q ( s t + 1 , a ′ ) \underset{a^{'}}{max} Q(s_{t+1},a^{'}) a′maxQ(st+1,a′)表示智能体在下一状态 s t + 1 s_{t+1} st+1所能获得的最大未来奖励。
这个公式表示,Q-learning 使用当前的奖励和下一步的最优 Q 值来更新当前状态-动作对的估计值。通过反复应用这一更新,Q-learning 最终能够逼近最优的 Q 函数。
Q-learning 算法流程
-
初始化
- 对每个状态 s s s和动作 a a a,初始化 Q ( s , a ) Q(s,a) Q(s,a)为任意值(通常为0或小随机值)。
- 设定学习率 α \alpha α、折扣因子 γ \gamma γ,以及探索率 ϵ \epsilon ϵ(用于 ϵ − \epsilon- ϵ−贪婪策略)。
-
算法主循环
-
for 每一轮(episode):
-
初始化起始状态 s 0 s_{0} s0。
-
for 每个时间步 t t t:
- 根据 ϵ − \epsilon- ϵ−贪婪策略选择动作 a t a_{t} at,即以概率 ϵ \epsilon ϵ随机选择动作,以概率 1 − ϵ 1-\epsilon 1−ϵ选择当前最优动作 a = a r g m a x a ′ Q ( s t , a ′ ) a=arg\underset{a^{'}}{max} Q(s_{t},a^{'}) a=arga′maxQ(st,a′)。
- 执行动作 a t a_{t} at,从环境获得即时奖励 R t + 1 R_{t+1} Rt+1并进入下一个状态 s t + 1 s_{t+1} st+1。
- 使用Q-learning更新公式更新Q值:
Q ( s t , a t ) ⟵ Q ( s t , a t ) + α ( R t + 1 + γ m a x a ′ Q ( s t + 1 , a ′ ) − Q ( s t , a t ) ) Q(s_{t},a_{t})\longleftarrow Q(s_{t},a_{t})+\alpha (R_{t+1}+\gamma \underset{a^{'}}{max} Q(s_{t+1},a^{'})-Q(s_{t},a_{t})) Q(st,at)⟵Q(st,at)+α(Rt+1+γa′maxQ(st+1,a′)−Q(st,at)) - 将状态更新为 s t + 1 s_{t+1} st+1。
-
如果达到终止状态(终点或其他设定条件),结束该轮。
-
-
-
策略改进:
- 根据学习到的 Q 函数,逐步改进策略。在任意状态 s s s 下,选择动作的策略为:
π ( s ) = a r g m a x a Q ( s , a ) \pi (s)=arg \underset{a}{max} Q(s,a) π(s)=argamaxQ(s,a) - 随着时间的推移,智能体在学习过程中逐渐减少探索(降低 ϵ − \epsilon- ϵ− 值),最终逐渐收敛于最优策略。
- 根据学习到的 Q 函数,逐步改进策略。在任意状态 s s s 下,选择动作的策略为:
Q-learning 的特点
-
离线策略(Off-policy):Q-learning 的一个显著特征是它不依赖于行为策略来更新 Q 值。它通过最大化未来回报更新 Q 值,而不关心实际执行的动作。这意味着行为策略和目标策略可以不同,从而允许 Q-learning 使用历史数据进行学习,能够更好地重复利用样本。
-
探索与利用的平衡:在实际的学习过程中,Q-learning 需要在探索(选择随机动作,获得更多的状态-动作信息)和利用(使用当前学到的最优策略)之间保持平衡。通常通过 ϵ − \epsilon- ϵ−贪婪策略来实现,其中 ϵ − \epsilon- ϵ−控制探索的概率,并随着学习进程逐渐减少。
-
样本复杂度:由于 Q-learning 是离线策略,能够重复利用行为策略下的样本,具有更低的样本复杂度。智能体无需严格依赖当前策略采样的数据,可以有效利用以前的经验数据进行更新。
1.3 总结
Q-learning 是一种无模型的强化学习算法,旨在通过迭代估计状态-动作值函数,逐步逼近最优策略。作为离线策略算法,Q-learning 不依赖于当前的行为策略,能够利用最大化未来回报的估计进行更新,具备更高的样本效率和灵活性。通过与环境交互,智能体不断调整 Q 值,使其最终收敛到最优策略。该算法广泛应用于复杂的决策任务中,尤其是在状态和动作空间较大且模型未知的情况下表现优异。