HOG+SVM行人检测
前言
在前面的博客:HOG特征检测学习笔记中,介绍了HOG特征,也附有代码实现。这篇博客中将会使用HOG+SVM这一经典的目标检测算法来进行行人检测,但是不会讨论HOG或者SVM的理论部分,如果有不懂的请自行查阅以前的博客。我分别写了python版本和C++版本的demo,数据集是直接下载了别人的,这些都会附在文章的最后。
网上也有很多介绍HOG的不错的文章:
HOG+SVM行人检测的两种方法
目标检测的图像特征提取之(一)HOG特征
python+opencv3.4.0 实现HOG+SVM行人检测
程序实现
基于python和c++写的demo思想上都是一样的,无非就是从数据集读入正负样本,提取HOG特征,送入SVM训练。而检测时,则使用训练好的SVM来识别滑动窗口中的ROI,也可以设置多尺寸,即使用滑动窗口中的ROI的图像金字塔,对多尺寸图像进行检测。这些在OpenCV中都实现好了,我们就不重复造轮子了。
python版本demo
直接上代码:
# *_*coding:utf-8 *_*
import os
import sys
import cv2
import logging
import numpy as np
def logger_init():
'''
自定义python的日志信息打印配置
:return logger: 日志信息打印模块
'''
# 获取logger实例,如果参数为空则返回root logger
logger = logging.getLogger("PedestranDetect")
# 指定logger输出格式
formatter = logging.Formatter('%(asctime)s %(levelname)-8s: %(message)s')
# 文件日志
# file_handler = logging.FileHandler("test.log")
# file_handler.setFormatter(formatter) # 可以通过setFormatter指定输出格式
# 控制台日志
console_handler = logging.StreamHandler(sys.stdout)
console_handler.formatter = formatter # 也可以直接给formatter赋值
# 为logger添加的日志处理器
# logger.addHandler(file_handler)
logger.addHandler(console_handler)
# 指定日志的最低输出级别,默认为WARN级别
logger.setLevel(logging.INFO)
return logger
def load_data_set(logger):
'''
导入数据集
:param logger: 日志信息打印模块
:return pos: 正样本文件名的列表
:return neg: 负样本文件名的列表
:return test: 测试数据集文件名的列表。
'''
logger.info('Checking data path!')
pwd = os.getcwd()
logger.info('Current path is:{}'.format(pwd))
# 提取正样本
pos_dir = os.path.join(pwd, 'Positive')
if os.path.exists(pos_dir):
logger.info('Positive data path is:{}'.format(pos_dir))
pos = os.listdir(pos_dir)
logger.info('Positive samples number:{}'.format(len(pos)))
# 提取负样本
neg_dir = os.path.join(pwd, 'Negative')
if os.path.exists(neg_dir):
logger.info('Negative data path is:{}'.format(neg_dir))
neg = os.listdir(neg_dir)
logger.info('Negative samples number:{}'.format(len(neg)))
# 提取测试集
test_dir = os.path.join(pwd, 'TestData')
if os.path.exists(test_dir):
logger.info('Test data path is:{}'.format(test_dir))
test = os.listdir(test_dir)
logger.info('Test samples number:{}'.format(len(test)))
return pos, neg, test
def load_train_samples(pos, neg):
'''
合并正样本pos和负样本pos,创建训练数据集和对应的标签集
:param pos: 正样本文件名列表
:param neg: 负样本文件名列表
:return samples: 合并后的训练样本文件名列表
:return labels: 对应训练样本的标签列表
'''
pwd = os.getcwd()
pos_dir = os.path.join(pwd, 'Positive')
neg_dir = os.path.join(pwd, 'Negative')
samples = []
labels = []
for f in pos:
file_path = os.path.join(pos_dir, f)
if os.path.exists(file_path):
samples.append(file_path)
labels.append(1.)
for f in neg:
file_path = os.path.join(neg_dir, f)
if os.path.exists(file_path):
samples.append(file_path)
labels.append(-1.)
# labels 要转换成numpy数组,类型为np.int32
labels = np.int32(labels)
labels_len = len(pos) + len(neg)
labels = np.resize(labels, (labels_len, 1))
return samples, labels
def extract_hog(samples, logger):
'''
从训练数据集中提取HOG特征,并返回
:param samples: 训练数据集
:param logger: 日志信息打印模块
:return train: 从训练数据集中提取的HOG特征
'''
train = []
logger.info('Extracting HOG Descriptors...')
num = 0.
total = len(samples)
for f in samples:
num += 1.
logger.info('Processing {} {:2.1f}%'.format(f, num/total*100))
hog = cv2.HOGDescriptor((64,128), (16,16), (8,8), (8,8), 9)
# hog = cv2.HOGDescriptor()
img = cv2.imread(f, -1)
img = cv2.resize(img, (64,128))
descriptors = hog.compute(img)
logger.info('hog feature descriptor size: {}'.format(descriptors.shape)) # (3780, 1)
train.append(descriptors)
train = np.float32(train)
train = np.resize(train, (total, 3780))
return train
def get_svm_detector(svm):
'''
导出可以用于cv2.HOGDescriptor()的SVM检测器,实质上是训练好的SVM的支持向量和rho参数组成的列表
:param svm: 训练好的SVM分类器
:return: SVM的支持向量和rho参数组成的列表,可用作cv2.HOGDescriptor()的SVM检测器
'''
sv = svm.getSupportVectors()
rho, _, _ = svm.getDecisionFunction(0)
sv = np.transpose(sv)
return np.append(sv, [[-rho]], 0)
def train_svm(train, labels, logger):
'''
训练SVM分类器
:param train: 训练数据集
:param labels: 对应训练集的标签
:param logger: 日志信息打印模块
:return: SVM检测器(注意:opencv的hogdescriptor中的svm不能直接用opencv的svm模型,而是要导出对应格式的数组)
'''
logger.info('Configuring SVM classifier.')
svm = cv2.ml.SVM_create()
svm.setCoef0(0.0)
svm.setDegree(3)
criteria = (cv2.TERM_CRITERIA_MAX_ITER + cv2.TERM_CRITERIA_EPS, 1000, 1e-3)
svm.setTermCriteria(criteria)
svm.setGamma(0)
svm.setKernel(cv2.ml.SVM_LINEAR)
svm.setNu(0.5)
svm.setP(0.1) # for EPSILON_SVR, epsilon in loss function?
svm.setC(0.01) # From paper, soft classifier
svm.setType(cv2.ml.SVM_EPS_SVR)
logger.info('Starting training svm.')
svm.train(train, cv2.ml.ROW_SAMPLE, labels)
logger.info('Training done.')
pwd = os.getcwd()
model_path = os.path.join(pwd, 'svm.xml')
svm.save(model_path)
logger.info('Trained SVM classifier is saved as: {}'.format(model_path))
return get_svm_detector(svm)
def test_hog_detect(test, svm_detector, logger):
'''
导入测试集,测试结果
:param test: 测试数据集
:param svm_detector: 用于HOGDescriptor的SVM检测器
:param logger: 日志信息打印模块
:return: 无
'''
hog = cv2.HOGDescriptor()
hog.setSVMDetector(svm_detector)
# opencv自带的训练好了的分类器
# hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
pwd = os.getcwd()
test_dir = os.path.join(pwd, 'TestData')
cv2.namedWindow('Detect')
for f in test:
file_path = os.path.join(test_dir, f)
logger.info('Processing {}'.format(file_path))
img = cv2.imread(file_path)
rects, _ = hog.detectMultiScale(img, winStride=(4,4), padding=(8,8), scale=1.05)
for (x,y,w,h) in rects:
cv2.rectangle(img, (x,y), (x+w,y+h), (0,0,255), 2)
cv2.imshow('Detect', img)
c = cv2.waitKey(0) & 0xff
if c == 27:
break
cv2.destroyAllWindows()
if __name__ == '__main__':
logger = logger_init()
pos, neg, test = load_data_set(logger=logger)
samples, labels = load_train_samples(pos, neg)
train = extract_hog(samples, logger=logger)
logger.info('Size of feature vectors of samples: {}'.format(train.shape))
logger.info('Size of labels of samples: {}'.format(labels.shape))
svm_detector = train_svm(train, labels, logger=logger)
test_hog_detect(test, svm_detector, logger)
补充说明
代码中将每部分功能都分成了各个函数,并附有注释。这里不对全部代码进行说明了,而是补充几个重要的地方。
1、数据集
Positive文件夹中存放正样本图片。这里要做行人检测,所以正样本理应是行人。一般大小为64*128,如果尺寸不一致,可以在程序中调整大小为64*128.
Negative文件夹中存放负样本图片。负样本可以采用一些无关背景图片。
TestData文件夹中存放测试图片。
再来看看运行程序时的log信息。

可以看到程序自动检查上述几个文件夹,统计的结果为:Positive目录中有924个正样本,Negative目录中有924个负样本,TestData目录中有179个样本。
这里用到的数据集是我从网上下载的。数据量较小,所以一定程度上会限制训练出的模型的准确率,如果要求更高的精度需要增加样本数量。另外一点,我们应该尽量增加负样本的多样性,相比行人的特征,负样本的多样性高得多,所以我们可以预见,最后训练的结果很可能会有一些没能识别为负样本的情况,而这个问题可以通过增加负样本数量和多样性来缓解。
2、HOG特征维度
运行过程中提取出的每张图片对应的HOG特征维度为:(3780,1)。

将所有图片的HOG特征向量组合成待训练的特征向量和其对应的标签。
![]()
可以看出特征向量维度为:(1848,3780),标签维度为:(1848,1)。
总共有924个正样本和924个负样本,每个样本的HOG特征向量维度为(3780,1)。正好对应。
将训练样本送入SVM训练即可,数据集较小,很快就能迭代出结果。
训练好的SVM也会保存为svm.xml。
![]()
3、检测结果
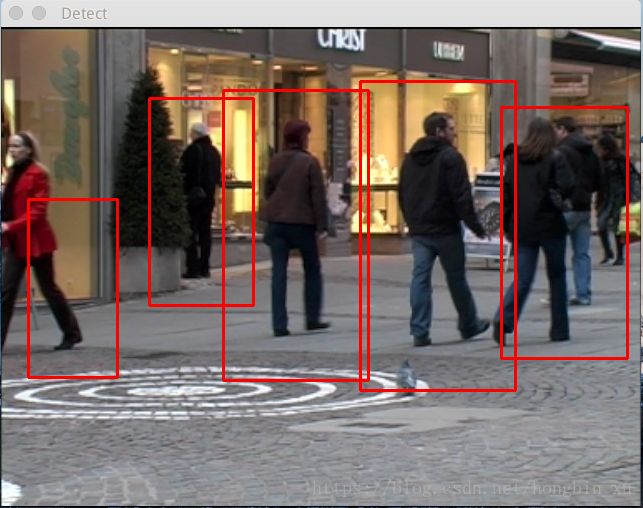
使用自己训练的检测器:


虽然人都检测出来了,但是发现有些多出来的框了吧,这个正好就是前面说到的负样本不足的问题。我使用的负样本数据集很小并且多样性不好,所以会有一些样本不能正确分类为负样本。正如图中所示。
使用opencv自带的检测器:
修改代码:
hog.setSVMDetector(svm_detector)为:
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())其他不变,运行代码:
跟前面自己训练的检测器的结果差不多,除了右边几个人重合的部分。

看得出效果比用自己的数据集训练的好一些。
C++版本demo
套路上来说跟python版本的基本一致,除了C++读取数据集的图片时的操作是借助制作好的txt文件之外。代码也不难理解,不做赘述了。文件路径请自行更改。
#include "opencv2/opencv.hpp"
#include "opencv2/ml.hpp"
#include svm = cv::ml::SVM::create();
svm->setType(cv::ml::SVM::C_SVC);
svm->setKernel(cv::ml::SVM::LINEAR);
svm->setTermCriteria(cv::TermCriteria(CV_TERMCRIT_ITER, 1000, FLT_EPSILON));
//训练SVM
svm->train(featureVectorOfSample, cv::ml::ROW_SAMPLE, classOfSample);
//保存训练好的分类器(其中包含了SVM的参数,支持向量,α和rho)
svm->save(string(FILEPATH) + "classifier.xml");
/*
SVM训练完成后得到的XML文件里面,有一个数组,叫做support vector,还有一个数组,叫做alpha,有一个浮点数,叫做rho;
将alpha矩阵同support vector相乘,注意,alpha*supportVector,将得到一个行向量,将该向量前面乘以-1。之后,再该行向量的最后添加一个元素rho。
如此,变得到了一个分类器,利用该分类器,直接替换opencv中行人检测默认的那个分类器(cv::HOGDescriptor::setSVMDetector()),
*/
//获取支持向量
cv::Mat supportVector = svm->getSupportVectors();
//获取alpha和rho
cv::Mat alpha;
cv::Mat svIndex;
float rho = svm->getDecisionFunction(0, alpha, svIndex);
//转换类型:这里一定要注意,需要转换为32的
cv::Mat alpha2;
alpha.convertTo(alpha2, CV_32FC1);
//结果矩阵,两个矩阵相乘
cv::Mat result(1, 3780, CV_32FC1);
result = alpha2 * supportVector;
//乘以-1,这里为什么会乘以-1?
//注意因为svm.predict使用的是alpha*sv*another-rho,如果为负的话则认为是正样本,在HOG的检测函数中,使用rho+alpha*sv*another(another为-1)
//for (int i = 0;i < 3780;i++)
//result.at(0, i) *= -1;
//将分类器保存到文件,便于HOG识别
//这个才是真正的判别函数的参数(ω),HOG可以直接使用该参数进行识别
FILE *fp = fopen((string(FILEPATH) + "HOG_SVM.txt").c_str(), "wb");
for (int i = 0; i<3780; i++)
{
fprintf(fp, "%f \n", result.at<float>(0, i));
}
fprintf(fp, "%f", rho);
fclose(fp);
}
void Detect()
{
cv::Mat img;
FILE* f = 0;
char _filename[1024];
// 获取测试图片文件路径
f = fopen((string(FILEPATH) + "TestData.txt").c_str(), "rt");
if (!f)
{
fprintf(stderr, "ERROR: the specified file could not be loaded\n");
return;
}
//加载训练好的判别函数的参数(注意,与svm->save保存的分类器不同)
vector<float> detector;
ifstream fileIn(string(FILEPATH) + "HOG_SVM.txt", ios::in);
float val = 0.0f;
while (!fileIn.eof())
{
fileIn >> val;
detector.push_back(val);
}
fileIn.close();
//设置HOG
cv::HOGDescriptor hog;
//hog.setSVMDetector(detector);
hog.setSVMDetector(cv::HOGDescriptor::getDefaultPeopleDetector());
cv::namedWindow("people detector", 1);
// 检测图片
for (;;)
{
// 读取文件名
char* filename = _filename;
if (f)
{
if (!fgets(filename, (int)sizeof(_filename) - 2, f))
break;
if (filename[0] == '#')
continue;
//去掉空格
int l = (int)strlen(filename);
while (l > 0 && isspace(filename[l - 1]))
--l;
filename[l] = '\0';
img = cv::imread(filename);
}
printf("%s:\n", filename);
if (!img.data)
continue;
fflush(stdout);
vector 完整工程下载
我把完整工程和数据集一起放到了github上:
Python版本的demo:https://github.com/ToughStoneX/hog_pedestran_detect_python
C++版本的demo:https://github.com/ToughStoneX/hog_pedestran_detect_c_plus_plus