分布式深度学习的两种集群管理与调度的实现方式简介
为什么需要集群管理与调度
上文我们简单介绍了深度学习、分布式CPU+GPU集群的实现原理,以及分布式深度学习的原理,我们简单回顾一下:
分布式CPU+GPU集群的实现:

GPU集群并行模式即为多GPU并行中各种并行模式的扩展,如上图所示。节点间采用InfiniBand通信,节点间的GPU通过RMDA通信,节点内多GPU之间采用基于infiniband的通信。
分布深度学习框架的实现:
如下图所示,在tensorflow中,计算节点称做worker节点,Worker节点主要完成模型的训练与计算。参数服务器可以是多台机器组成的集群,类似分布式的存储架构,涉及到数据的同步,一致性等等, 一般是key-value的形式,可以理解为一个分布式的key-value内存数据库,然后再加上一些参数更新的操作,采取这种方式可以几百亿的参数分散到不同的机器上去保存和更新,解决参数存储和更新的性能问题。


在分布式深度学习框架运行时,可以将深度学习框架部署到具体的物理集群,PS服务器可以挑选如下图中的node0、node1…,worker节点可以挑选如下图中的node i,node N-1

集群的具体配置,参数服务器可以不用GPU,worker节点因为需要进行模型计算,所在的服务器需要配置GPU卡。
至此,我们基本搭建了一个深度学习的硬件集群,同时也将深度学习框架部署到了深度学习的服务器集群,但是,整个深度学习集群(包括软硬件),可能是公司内部的共享资产,每个项目组都需要使用,那么,采取上述方式部署便会带来如下问题:
1. 要求项目组必须使用统一的深度学习框架,统一的深度学习框架的版本,否则不同项目组完成的训练代码有可能不工作,如果每次为了适应某个项目组的要求去重新部署框架,工作量巨大,而且耗时耗力;
2. 其中一个项目组在使用集群时,其他项目组往往需要等待,导致集群的资源使用率较低;
3. 服务器集群中任何一台硬件出现问题,都会影响整个集群的使用。
集群管理与调度实现的两种思路
基于Kubernetes平台
Kubernetes是Google开源的容器集群管理系统,其提供应用部署、维护、 扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用,其主要功能如下:
1) 使用Docker对应用程序包装(package)、实例化(instantiate)、运行(run)。
2) 以集群的方式运行、管理跨机器的容器。
3) 解决Docker跨机器容器之间的通讯问题。
4) Kubernetes的自我修复机制使得容器集群总是运行在用户期望的状态。
Kubernetes自1.3开始支持GPU,但当时只能最多支持单GPU的调度,自1.6开始,已经支持多GPU的调度,更多关于Kubernetes的与GPU介绍可以参考本系列未来的第3篇:分布式机器学习的两种集群方案介绍之基于Kubernetes的实现,这里不太多赘述。
如果要完成基于Kubernetes的集群调度管理深度学习框架,需要将深度学习框架运行到容器之中。系统整体架构图将变为:
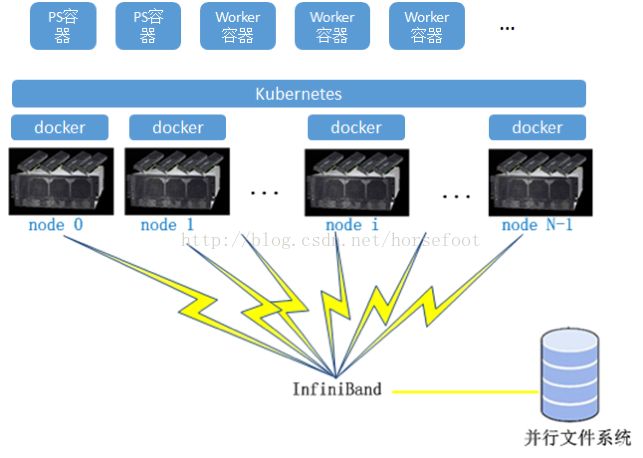
这里面涉及到一个Kubernetes集群调度的问题,即Kubernetes如何将ps、worker所在容器所需要的CPU、GPU、内存、存储进行调度,以满足需求。
集群经过Kubernetes进行管理以后,分布式深度学习框架运行在容器中,容器通过Kubernetes进行调度以满足所需的模型训练资源,因此能够很好的满足集群资源多部门共享的要求。我们看对以下问题的解决。
1. 要求项目组必须使用统一的深度学习框架,并要求统一版本,否则不同项目组完成的训练代码有可能不工作,如果每次为了适应某个项目组的要求去重新部署框架,工作量巨大,而且耗时耗力;
解决:基于容器+ Kubernetes平台,每个项目组可以很容易的申请自己所需要的深度学习框架,tensorflow、caffe等,同时同一种深度学习框架的多种版本支持也不在话下。
2. 其中一个项目组在使用集群时,其他项目组往往需要等待,即使集群的资源使用率较低;
解决:只要集群有利用率没达到100%,便可以方便地为其他项目组部署深度学习环境。
3. 服务器集群中任何一台硬件出现问题,都会影响整个集群的使用;
解决:通过Kubernetes的调度,完成底层硬件的容错。
天云软件基于Kubernetes平台研发的SkyForm ECP平台,已经完整的支持了GPU调度,同时也集成了tensorflow,caffe等深度学习框架。
基于MPI并行调度
我们此处引入HPC领域中的MPI集群作业调度管理解决方案,因为在神经元网络(也包括含更多隐层的深度学习场景下),上一层神经元计算完成以后才能进行下一层神经元网络的计算,这与MPI的计算思路不谋而合。MPI是高性能计算(HPC)应用中广泛使用的编程接口,用于并行化大规模问题的执行,在大多数情况下,需要通过集群作业调度管理软件来启动和监视在集群主机上执行的MPI任务。此方法的主要目标是使集群作业调度管理软件能够跟踪和控制组成MPI作业的进程。
一些集群作业调度管理软件,如IBM Platform LSF、天云软件SkyForm OpenLava等,可以跟踪MPI任务的CPU、内存、GPU的使用。我们把每个深度学习的计算作为MPI作业,通过天云软件OpenLava作业调度管理软件进行集群统一的资源管理与分配,具体的实现思路如下:

基于集群作业调度管理的解决方案,也能很好的满足深度学习集群多部门共享,多作业并发运行的特性,且能兼顾效率。
其中天云软件SkyForm Openlava是一个增强的、基于开源OpenLava并兼容IBM® Spectrum LSFTM的企业级工作负载调度器,并针对半导体研发、深度学习等的工作负载做了设计与优化。不论是现场物理集群部署,虚拟基础设施部署,还是云中部署,客户都不用支付高昂的许可证费用。具体的openlava介绍,可参考网站openlava.net。
另外,在深度学习框架需要基于MPI方式运行时,往往需要进行重新编译,并不是所有的版本都支持。