Alexnet训练Cifar10
Alexnet作为经典网络,值得深度学习。通过实验,(1)尽可能的加深对paper一些创新点理解。AlexNet谜一般的input是224*224,实际上应该是227*227。在实验中,我采用的是cifar10,输入是32*32。所以将网络参数同比简化。(2)尽可能理解不同训练方法带来的区别。
数据集:http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
训练用的代码: https://github.com/diudiuzhi/TensorAlexnet
python train.py
Alexnet特点:
- 1 引入relu
- 2 GPU并行计算
- 3 LRN
- 4 Overlapping Pooling
- 5 引入Dropout
- 6 Data Augmentation
第一点,不验证,之后的网络都是使用relu。MSRAnet提出的Prelu也是为了解决relu负域梯度0的问题。
第二点,不验证,Alex当时单块GPU内存3Gb,不足以训练网络,于是采用两块GPU并行。另外他的架构中存在网络不对称性。并宣称这一点对他结果有贡献。
第三点,实验验证:带LRN和不带LRN训练结果差距,时间开销。后续论文评价LRN,对结果并没有特别的贡献,但是极费时间。
第四点,不验证。
第五点,dropout用于防止过拟合,在这里测试不同的 dropout对结果和时间的影响。
第六点,测试数据增强对网络的影响。
本篇博客将从以下几点实验:
1)验证不同学习率对网络的影响。
2) 验证不同的优化器对网络的影响。
3)验证LRN对网络的影响。
4)验证dropout对网络的影响。
5)验证不同初始化方式对网络的影响。(MSRA提出)
6)验证数据增强对网络的影响。
网络基础结构:
Input: 32*32*3
Padding: SAME
kernel: 3*3
stride: 1
Conv1:
channel: 24
lrn
max pool: 2*2
Conv2:
channel: 96
lrn
max pool: 2*2
Conv3:
channel: 192
Conv4:
channel: 192
Conv5:
channel: 96
max_pool: 2*2
FC1:
98304 * 1024
FC2:
1024*1024
FC3:
1024*10
实验1:
训练集: 45k
验证集: 5k
测试集: 10k
Momentum 0.9
epoch: 60
batch size: 64
dropout: 0.9
权值初始化:(MSRA)sqrt(2/n)
1).
learning rate: 0.001
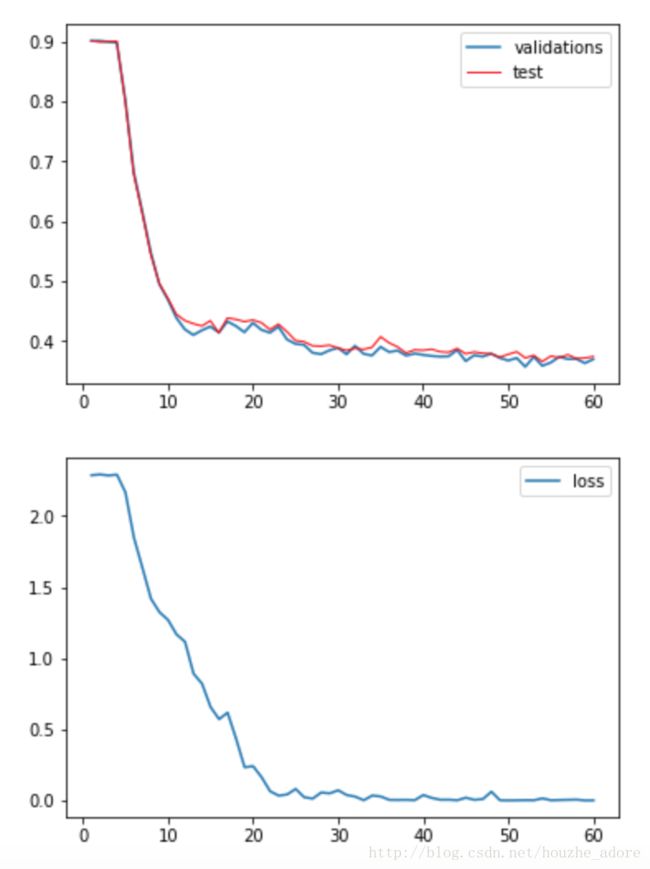
最后一轮训练数据:
Validation: 0.63
Test: 0.625
Loss: 0.000547
训练时间: 3895.7s
2).
learning rate: 0.001 -> 0.0001

第一图纵坐标是错误率
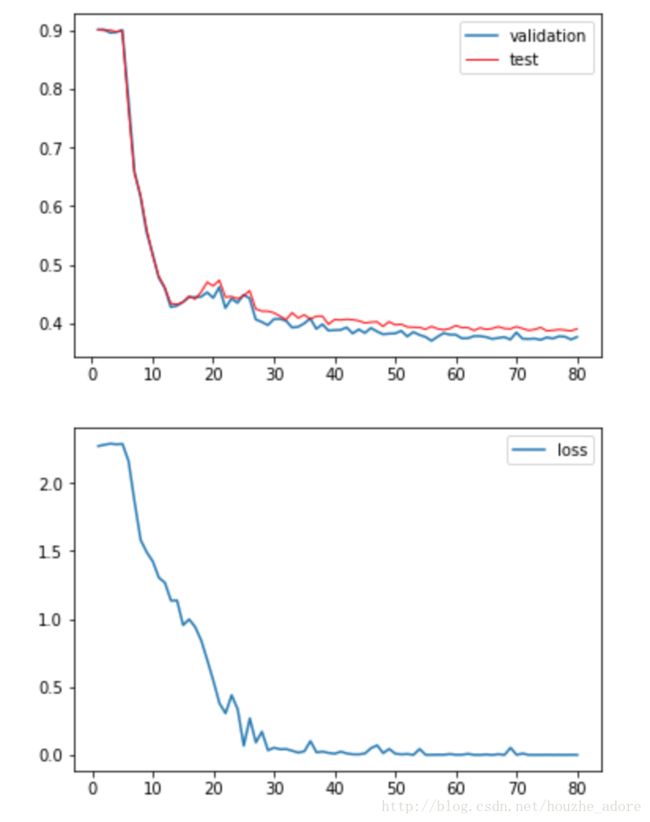
3)
learning_rate初始化为0.001,然后采用指数衰减模式,在第60个迭代时,降低到0.0001。之后在多训练20个迭代。(本次比上两次多训练20个迭代)
第60轮迭代数据:
validation: 0.619800
test: 0.604200
loss: 0.001159
对比一下在60迭代,learning固定为0.001和用指数衰减(实验1-1,1-3)的测试集精确度变化图:

80轮迭代数据:
Validation: 0.623600
test: 0.609900
loss: 0.000418
总训练时间:5593.91s
实验二:
(1)数据集增强
将image set减去训练集均值后,随机裁剪为24*24,然后随机翻转,随机调整对比度,亮度。
学习率初始化为0.01, 按照0.9995指数衰减。
训练次数改为 80 epochs
其余参数和之前实验一样
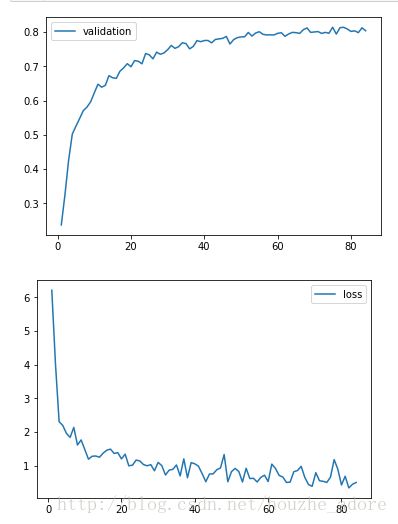
可以看到验证集准确率已经突破80%了
实验三:
(1)更换优化器
原:GradientDescentOptimizer
新:AdamOptimizer
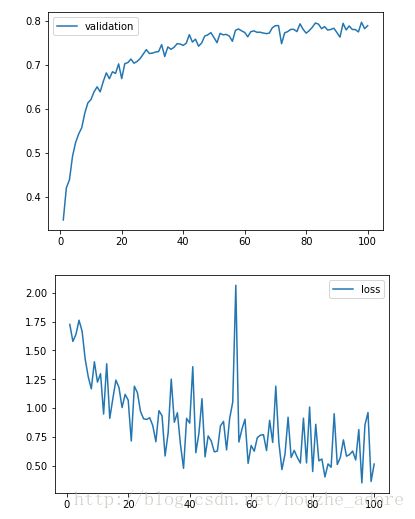
最终测试集准确率为 0.79347
实验四:
(1) 去掉LRN
优化器:GradientDescentOptimizer
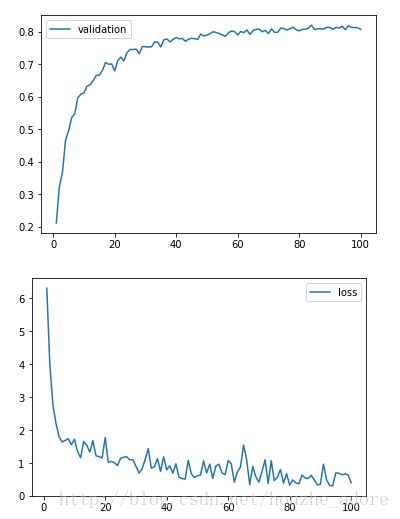
测试集精度: 0.811599
运行时间:3010s
(2)前两层加上LRN
测试集精度:0.806290
运行时间4225s
与之前实验对比:
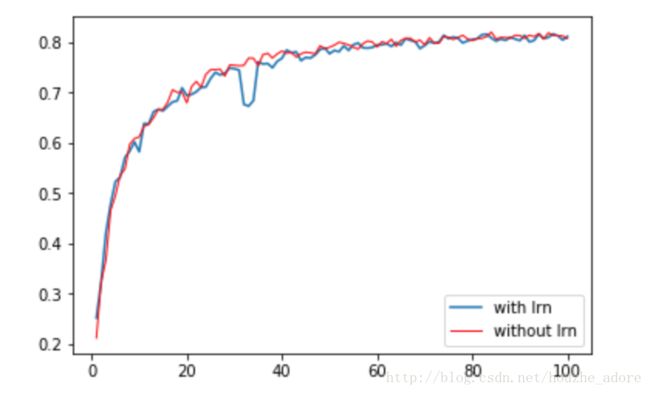
LRN对于精度影响不大,从单次实验看,不带LRN精度反而更好。从时间来看,LRN计算量很大,以至于运算时间明显增长。在之后的paper中,几乎没见过人有用LRN的。更不用说BN提出后。再之后实验中,去掉LRN。
实验五:
与实验四相比,除了Dropout参数改变外,其余不变。
Dropout: 0.9 -> 0.5
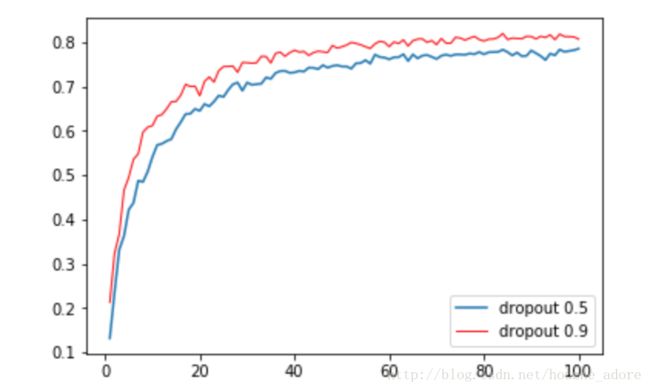
测试集精度:0.78526
按照paper中描述,dropout 0.5会增加一倍的收敛时间。因此将迭代次数增加一倍,看看效果。
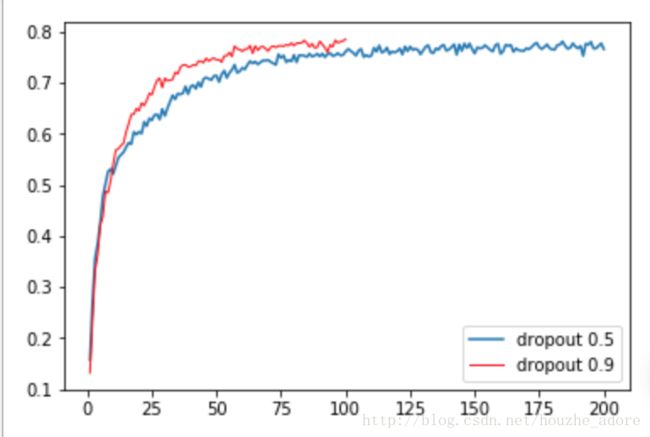
测试集精度:0.769331
实验六:
使用global average pooling代替fc
忘记截图了,去掉fc1,fc2.用global average pooling 替换。精度是0.75,少了2层fc,计算速度非常快,也许是目前用的姿势不对,按照paper说,精度应该不受影响,如果我加上2层fc,会遇到梯度弥散,网络不收敛的问题。
实验七:
添加bn
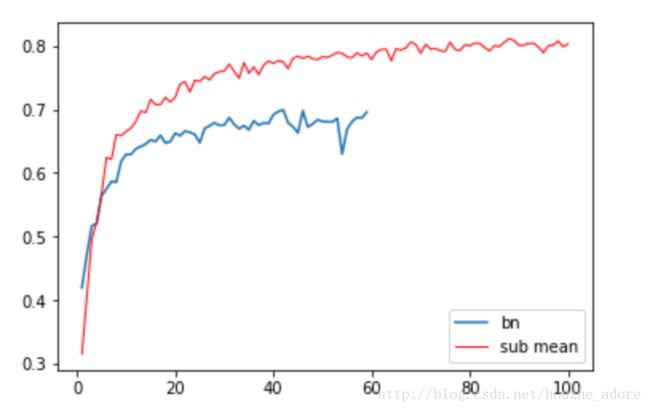
感觉侮辱了BN。。。。应该是工程实现上有问题。之后弄明白会来重补这次实验。
总结:
说是Alexnet训练cifar10,但是还是情不自禁尝试了一些后续paper的技术。实验中并没有用到alex的overlapping pooling。
- LRN没有什么卵用,反而增大了计算量。去掉2层lrn,训练时间显著减少三分之一。
- 在没有用数据集增强时,精度一直在65左右。用了之后,精度显著的飞跃,到达80.说明数据集对于网络精度至关重要。
- 学习率控制非常重要,如果过大,训练结果可能会非常糟糕,过小的话容易进入局部最小。总结一下众多paper中训练方法,初始0.01开始训练,validation acc不变时,除以10,一直到0.00001停止。
- 权值初始化,何凯明在MSRA提出来一种初始化方法,可能因为cifar10维度太小,并没有感到什么优点。但是何凯明在Resnet中提到使用自己的方法,还是有用的。在使用BN之后,权值初始化就不是那么的重要了。
- 深度调参,随意更改每一层卷积核,明显的遇到了梯度弥散问题,非常尴尬。同时感到VGG中使用的pre-training的重要性。在resnet中和InceptionV3两篇论文中给出了一些非常不错的设计准则,可以参考调优网络。