论文阅读笔记(一)细粒度图像检索
0、参考文献
[1]见微知著 http://geek.csdn.net/news/detail/191718
[2]Xiu-Shen Wei 《Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval》
[3]Lingxi Xie 《Fine-Grained Image Search》
1、细粒度图像检索
图像分析中除监督环境下的分类任务,还有另一大类经典任务——无监督环境下的图像检索。
图像检索(Image Retrieval)按检索信息的形式,分为“以文搜图”(Text-Based)和“以图搜图”(Image-Based)。在此我们仅讨论以图搜图的做法。
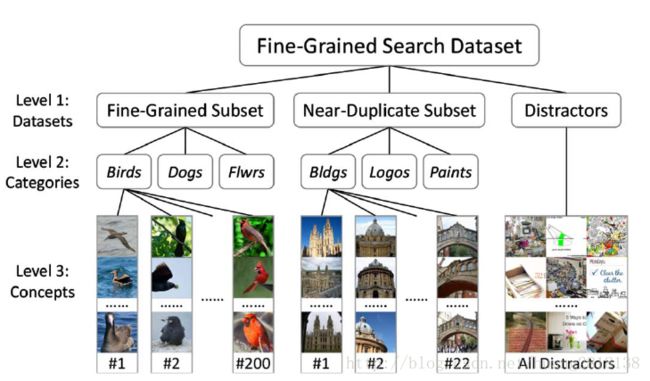
传统图像检索任务一般是检索类似复制的图像(Near-Duplicated Images),如图下图所示。

左侧单列为Query图像,右侧为返回的正确检索结果。可以看到,传统图像检索中图像是在不同光照不同时间下同一地点的图像,这类图像不会有形态、颜色、甚至是背景的差异。
而细粒度图像检索,如下图。

需要将同为“绿头鸭”的图像从众多不同类鸟类图像中返回;
同样,需要将“劳斯莱斯幻影”从包括劳斯莱斯其他车型的不同品牌不同车型的众多图像中检索出来。
细粒度图像检索的难点,一是图像粒度非常细微;二是对细粒度图像而言,哪怕是属于同一子类的图像本身也具有形态、姿势、颜色、背景等巨大差异。
可以说,细粒度图像检索是图像检索领域和细粒度图像分析领域的一项具有新鲜生命力的研究课题。
L. Xie、J. Wang等在2015年首次提出细粒度图像“搜索”的概念,通过构造一个层次数据库将多种现有的细粒度图像数据集和传统图像检索(一般为场景)融合。在搜索时,先判断其隶属的大类,后进行细粒度检索。其所用特征仍然是人造图像特征(SIFT等),基于图像特征可以计算两图相似度,从而返回检索结果,如下图所示。
SCDA(Selective Convolutional Descriptor Aggregation)是作者近期提出的首个基于深度学习的细粒度图像检索方法。
同其他深度学习框架下的图像检索工作一样,在SCDA中,细粒度图像作为输入送入Pre-Trained CNN模型得到卷积特征/全连接特征,如下图所示。
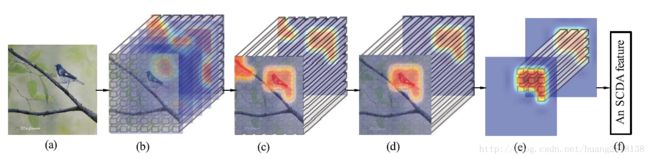
区别于传统图像检索的深度学习方法,针对细粒度图像检索问题,作者发现卷积特征优于全连接层特征,同时创新性的提出要对卷积描述子进行选择。
不过SCDA与之前提到的Mask-CNN的不同点在于,在图像检索问题中,不仅没有精细的Part Annotation,就连图像级别标记都无从获取。
这就要求算法在无监督条件下依然可以完成物体的定位,根据定位结果进行卷积特征描述子的选择。
对保留下来的深度特征,分别做以平均和最大池化操作,之后级联组成最终的图像表示。
很明显,在SCDA中,最重要的就是如何在无监督条件下对物体进行定位。
通过观察得到的卷积层特征,如下图所示,可以发现明显的“分布式表示”特性。
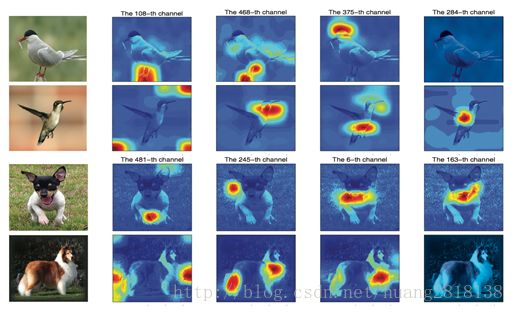
对两种不同鸟类/狗,同一层卷积层的最强响应也差异很大。如此一来,单独选择一层卷积层特征来指导无监督物体定位并不现实,同时全部卷积层特征都拿来帮助定位也不合理。例如,对于第二张鸟的图像来说,第108层卷积层较强响应竟然是一些背景的噪声。
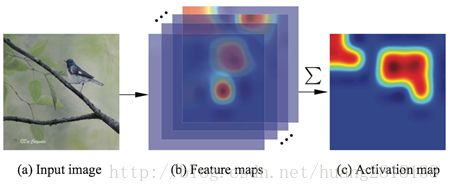
基于这样的观察,作者提出将卷积特征(HxWxD)在深度方向做加和,之后可以获得Aggregation Map(HxWx1)。
在这张二维图中,可以计算出所有HxW个元素的均值,而此均值m便是该图物体定位的关键:Aggregation Map中大于m的元素位置的卷积特征需保留;小于的则丢弃。
这一做法的一个直观解释是,细粒度物体出现的位置在卷积特征张量的多数通道都有响应,而将卷积特征在深度方向加和后,可以将这些物体位置的响应累积——有点“众人拾柴火焰高”的意味。
而均值则作为一把“尺子”,将“不达标”的响应处标记为噪声,将“达标”的位置标为物体所在。而这些被保留下来的位置,也就对应了应保留卷积特征描述子的位置。后续做法类似Mask-CNN。
实验中,在细粒度图像检索中,SCDA同样获得了最好结果;同时SCDA在传统图像检索任务中,也可取得同目前传统图像检索任务最好方法相差无几(甚至优于)的结果,如下图所示。