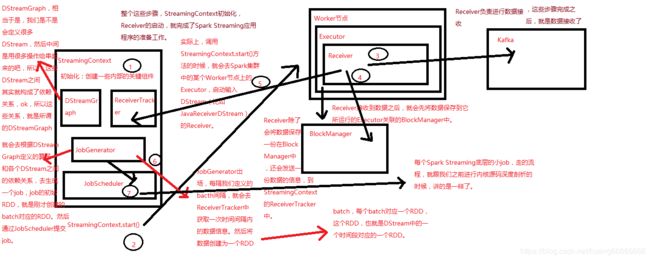
SparkStream 性能调优思路以及原理图
一、确保HA高可用性:High Availability
如果有些数据丢失,或者节点挂掉;那么不能让你的实时计算程序挂了;必须做一些数据上的冗余副本,保证你的实时计算程序可以7 * 24小时的运转。
通过一整套方案(3个步骤),开启和实现实时计算程序的HA高可用性,保证一些关键数据都有其冗余副本,不至于因为节点挂掉或者其他原因导致数据丢失。
1、updateStateByKey、window等有状态的操作,自动进行checkpoint,必须设置checkpoint目录
设置完这个基本的checkpoint目录之后,有些会自动进行checkpoint操作的DStream,就实现了HA高可用性;checkpoint,相当于是会把数据保留一份在容错的文件系统中,一旦内存中的数据丢失掉;那么就可以直接从文件系统中读取数据;不需要重新进行计算
2、Driver高可用性
第一次在创建和启动StreamingContext的时候,那么将持续不断地将实时计算程序的元数据(比如说,有些dstream或者job执行到了哪个步骤),如果后面,不幸,因为某些原因导致driver节点挂掉了;那么可以让spark集群帮助我们自动重启driver,然后继续运行时候计算程序,并且是接着之前的作业继续执行;没有中断,没有数据丢失
第一次在创建和启动StreamingContext的时候,将元数据写入容错的文件系统(比如hdfs);spark-submit脚本中加一些参数;保证在driver挂掉之后,spark集群可以自己将driver重新启动起来;而且driver在启动的时候,不会重新创建一个streaming context,而是从容错文件系统(比如hdfs)中读取之前的元数据信息,包括job的执行进度,继续接着之前的进度,继续执行。 使用这种机制,就必须使用cluster模式提交,确保driver运行在某个worker上面;但是这种模式不方便我们调试程序。
代码: private static void testDriverHA() {
final String checkpointDir = "hdfs://192.168.1.105:9090/streaming_checkpoint";
JavaStreamingContextFactory contextFactory = new JavaStreamingContextFactory() {
@Override
public JavaStreamingContext create() {
jssc.checkpoint(checkpointDir); //必须要设置checkpoint目录
把main方法里的所有代码放这里
return jssc;
}
};
JavaStreamingContext context = JavaStreamingContext.getOrCreate(
checkpointDir, contextFactory);
context.start();
context.awaitTermination();
}
--------------------------------------------
spark-submit脚本设置:
--deploy-mode cluster :必须运行在cluster上
--supervise : work监控driver的运行状态,保证在driver挂掉之后,spark集群可以自己将driver重新启动起来!
3、实现RDD高可用性
启动WAL预写日志机制 spark streaming,从原理上来说,是通过receiver来进行数据接收的;接收到的数据,会被划分成一个一个的block;block会被组合成一个batch;针对一个batch,会创建一个rdd;启动一个job来执行我们定义的算子操作。 receiver主要接收到数据,那么就会立即将数据写入一份到容错文件系统(比如hdfs)上的checkpoint目录中的,一份磁盘文件中去;作为数据的冗余副本。 无论你的程序怎么挂掉,或者是数据丢失,那么数据都不肯能会永久性的丢失;因为肯定有副本。
WAL(Write-Ahead Log)预写日志机制 spark.streaming.receiver.writeAheadLog.enable true
二、SparkStreaming性能调优思路
Spark Core的性能调优策略 + 以下6点!!!
1、并行化数据接收:处理多个topic的数据时比较有效
int numStreams = 5;
List
for (int i = 0; i < numStreams; i++) {
kafkaStreams.add(KafkaUtils.createStream(...)); //多个topic
}
JavaPairDStream
unifiedStream.print();
2、spark.streaming.blockInterval:增加block数量,增加每个batch rdd的partition数量,增加处理并行度
默认时间是200ms,官方推荐不要小于50ms;
receiver从数据源源源不断地获取到数据;首先是会按照block interval,将指定时间间隔的数据,收集为一个block;默认时间是200ms,官方推荐不要小于50ms;接着呢,会将指定batch interval时间间隔内的block,合并为一个batch;创建为一个rdd,然后启动一个job,去处理这个batch rdd中的数据 batch rdd,它的partition数量是多少呢?一个batch有多少个block,就有多少个partition;就意味着并行度是多少;就意味着每个batch rdd有多少个task会并行计算和处理。
当然是希望可以比默认的task数量和并行度再多一些了;可以手动调节block interval;减少block interval;每个batch可以包含更多的block;有更多的partition;也就有更多的task并行处理每个batch rdd。
定死了,初始的rdd过来,直接就是固定的partition数量了
3、某个DStream.repartition(
有些时候,希望对某些dstream中的rdd进行定制化的分区 对dstream中的rdd进行重分区,去重分区成指定数量的分区,这样也可以提高指定dstream的rdd的计算并行度
4、调节并行度 spark.default.parallelism
reduceByKey(numPartitions)
(这是spark Core里包含的两种设置并行度的方式)
5、使用Kryo序列化机制:
spark streaming,也是有不少序列化的场景的 提高序列化task发送到executor上执行的性能,如果task很多的时候,task序列化和反序列化的性能开销也比较可观
默认输入数据的存储级别是StorageLevel.MEMORY_AND_DISK_SER_2,receiver接收到数据,默认就会进行持久化操作;首先序列化数据,存储到内存中;如果内存资源不够大,那么就写入磁盘;而且,还会写一份冗余副本到其他executor的block manager中,进行数据冗余。
6、batch interval:每个的处理时间必须小于batch interval(不然会堆积占用内存)
设置: JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
实际上你的spark streaming跑起来以后,其实都是可以在spark ui上观察它的运行情况的;可以看到batch的处理时间; 如果发现batch的处理时间大于batch interval,就必须调节batch interval 尽量不要让batch处理时间大于batch interval 比如你的batch每隔5秒生成一次;你的batch处理时间要达到6秒;就会出现,batch在你的内存中日积月累,一直囤积着,没法及时计算掉,释放内存空间;而且对内存空间的占用越来越大,那么此时会导致内存空间快速消耗 如果发现batch处理时间比batch interval要大,就尽量将batch interval调节大一些