Docker核心技术(十)
Docker归根到底是一种容器虚拟化技术。
从操作系统功能上看,Docker底层依赖的核心技术主要包括Linux操作系统的命名空间(Namespaces),控制组(Control Groups),联合文件系统(Union File Systems)和Linux虚拟网络支持。
基础架构
Docker采用了标准的C/S架构,包括客户端和服务器两个部分。
客户端和服务器既可以运行在一个机器上,也可以通过socket或者RESTful API来进行通信。
服务器
Docker daemon一般在宿主主机后台运行,作为作为服务端接受来自客户端的请求,并处理这些请求(创建,运行,分发容器)。在设计上,Docker daemon是一个非常耦合的架构,通过专门的Engine模块来分发管理各个来自客户端的任务。
Docker服务器默认监听本地的unix:///var/run/docker.sock套接字,只允许本地的root用户访问。可以通过-H选项来修改监听的方式。例如,让服务器监听本地的TCP连接1234端口:
$ sudo docker -H 0.0.0.0:1234 -d &
此外,Docker还支持通过HTTPs认证方式来验证访问。
注:Ubuntu系统中,Docker服务端的默认启动配置文件在/etc/default/docker。
客户端
Docker客户端则为用户提供一系列可执行命令,用户用这些命令实现与Docker daemon的交互。
用户使用的Docker可执行命令即为客户端程序。与Docker daemon不同的是,客户端发送命令后,等待服务端返回,一旦收到返回后,客户端立刻执行结束并退出。用户执行新的命令,需要再次调用客服端命令。
同样,客户端默认通过本地的unix:///var/run/docker.sock套接字向服务端发送命令。如果服务端没有监听到默认套接字,则需要客户端在执行命令的时候显式指定。例如,假定服务端监听在本地TCP连接1234端口,只有通过-H参数指定了正确的信息才能连接到服务端:
$ sudo docker -H tcp://127.0.0.1:1234 version
命名空间
命名空间是Linux内核针对实现容器虚拟化而引入的一个强大特性。
每个容器都可以拥有自己单独的命名空间,运行在其中的应用都像是在独立的操作系统中运行一样。命名空间保证了容器之间彼此互不影响。
我们知道,在操作系统中,包括内核、文件系统、网络、PID、UID、IPC、内存、硬盘、CPU等资源,所有的资源都是应用进程直接共享的。要想实现虚拟化,除了要实现对内存、CPU、网络IO、硬盘IO、存储空间等的限制外,还要实现文件系统、网络、PID、UID、IPC等等的相互隔离。
随着Linux系统对于命名空间功能的逐步完善,已经实现上述的所有需求,让某些进程在彼此隔离的命名空间中运行。虽然,这些进程都共用一个内核和某些运行时环境,但是彼此是不可见的。
进程命名空间
Linux通过命名空间管理进程号,对于同一个进程(同一个task_struct),在不同的命名空间中,看到的进程号不相同,每个进程命名空间有有一套自己的进程号管理方式。进程命名空间是一个父子关系的结构,子空间中的进程对于父进程是可见的。新fork出的进程在父命名空间和子命名空间将分别有一个进程号来对应。
例如,查看Docker主进程的pid进程号是5958:
$ ps -ef |grep docker
新建一个Ubuntu的“hello world”容器:
$ sudo docker run -d ubuntu /bin/sh -c “while true;do echo hello world;sleep 1;done”
查看新建容器进程的父进程,正是Docker主进程5958:
$ ps -ef | grep while
网络命名空间
如果有了PID命名空间,那么每个名字空间中的进程就可以互相隔离,但是网络端口还是共享本地系统的端口。
通过网络命名空间,可以实现网络隔离。一个网络命名空间为进程提供了一个完全独立的网络协议栈的视图。包括网络设备借口、IPv4和IPv6协议栈、IP路由表、防火墙规则,socket等等。这样每个容器的网络就能隔离开来。Docker采用虚拟网络设备(Virtual Network Device)的方式,将不同命名空间的网络设备联系到一起。默认情况下,容器中的虚拟网卡将同本地主机上的docker0网桥连接在一起。
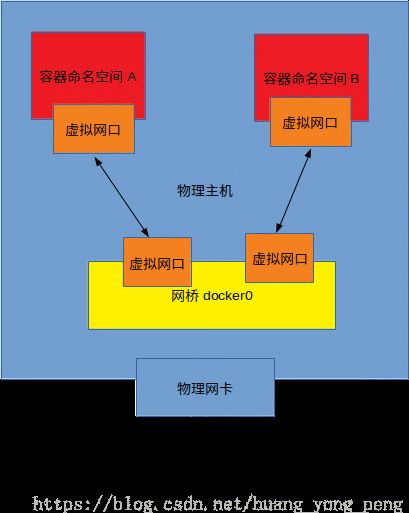
使用brctl工具,则可以看到桥接到宿主主机docker0网桥上的虚拟网口:
$ brctl show
IPC命名空间
容器中进程交互还是采用了Linux常见的进程间交互方法,包括信号量、消息队列和共享内存等。PID命名空间和IPC命名空间可以组合起来一起使用,同一个IPC名字空间内的进程可以彼此可见,允许进行交互;不同空间的进程则无法交互。
挂载命名空间
类似chroot,将一个进程放到一个特定的目录执行。挂载命名空间允许不同命名空间的进程看到的文件结构不同,这样每个命名空间中的进程所看到的文件目录彼此被隔离。
UTS命名空间
UTS(UNIX Time-sharing System)命名空间允许每个容器拥有独立的主机名和域名,从而可以虚拟处一个有独立主机名和网络空间的环境,就跟网络上一台独立的主机一样。
用户命名空间
每个容器可以有不同的用户和id,也就是说可以在容器内使用特定的内部用户执行程序,而非本地系统上存在的用户。
每个容器内部都可以有root账号,跟宿主主机不在一个命名空间。
控制组
控制组(CGroups)是Linux内核的一个特性,主要用来对共享资源进行隔离、限制、审计等。只有能控制分配到容器的资源,Docker才能避免多个容器同时运行时的系统资源竞争。
控制组技术可以提供对容器的内存、CPU、磁盘IO等资源进行限制和计费管理。
控制组的设计目的是为不同的应用情况提供统一的接口,从控制单一进程(比如nice工具)到系统级虚拟化。
具体来看,控制组提供如下功能:
- 资源限制组可以设置为不超过设定的内存限制。比如:内存子系统可以为进程组设定一个内存使用上限,一旦进程组使用的内存达到限额再申请内存,就会触发Out of Memory警告。
- 优先级通过优先级让一些组优先得到更多的CPU等资源。
- 资源审计用来统计系统实际上把多少资源用到合适的目的上,可以使用cpuacct子系统记录某个进程组使用的cpu时间。
- 隔离为组隔离名字空间,这样一个组不会看到另一个组的进程、网络连接和文件系统。
- 控制挂起、恢复和重启等操作。
安装Docker后,用户可以在/sys/fs/cgroup/memory/docker/目录下看到对Docker组应用的各种限制项:
$ cd /sys/fs/cgroup/memory/docker
$ ls
联合文件系统
联合文件系统(UnionFS)是一种轻量级的高性能分层文件系统,它支持将文件系统中的修改信息作为一次提交,并层层叠加,同时可以将不同目录挂载到同一个虚拟文件系统下。
联合文件系统是实现Docker镜像的技术基础,镜像可以通过分层来进行继承。
Docker网络实现
Docker中的网络接口默认都是虚拟的接口。虚拟接口的最大优势就是转发效率极高。这是因为Linux通过在内核中进行数据复制来实现虚拟接口之间的数据转发,即发送接口的发送缓存中的数据包将直接复制到接受接口的接受缓存中,而无需通过外部物理网络设备进行交换。
Docker容器网络就很好地利用Linux虚拟网络技术。它在本地主机和容器内分别创建一个虚拟接口,并让它们彼此连通(这样一对接口叫做vethpair)